 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMFace-DiT: A Dual-Stream Diffusion Transformer for High-Fidelity Multimodal Face Generation
Mar 30, 2026Recent multimodal face generation models address the spatial control limitations of text-to-image diffusion models by augmenting text-based conditioning with spatial priors such as segmentation masks, sketches, or edge maps. This multimodal fusion enables controllable synthesis aligned with both high-level semantic intent and low-level structural layout. However, most existing approaches typically extend pre-trained text-to-image pipelines by appending auxiliary control modules or stitching together separate uni-modal networks. These ad hoc designs inherit architectural constraints, duplicate parameters, and often fail under conflicting modalities or mismatched latent spaces, limiting their ability to perform synergistic fusion across semantic and spatial domains. We introduce MMFace-DiT, a unified dual-stream diffusion transformer engineered for synergistic multimodal face synthesis. Its core novelty lies in a dual-stream transformer block that processes spatial (mask/sketch) and semantic (text) tokens in parallel, deeply fusing them through a shared Rotary Position-Embedded (RoPE) Attention mechanism. This design prevents modal dominance and ensures strong adherence to both text and structural priors to achieve unprecedented spatial-semantic consistency for controllable face generation. Furthermore, a novel Modality Embedder enables a single cohesive model to dynamically adapt to varying spatial conditions without retraining. MMFace-DiT achieves a 40% improvement in visual fidelity and prompt alignment over six state-of-the-art multimodal face generation models, establishing a flexible new paradigm for end-to-end controllable generative modeling. The code and dataset are available on our project page: https://vcbsl.github.io/MMFace-DiT/
VoxMorph: Scalable Zero-shot Voice Identity Morphing via Disentangled Embeddings
Jan 27, 2026Morphing techniques generate artificial biometric samples that combine features from multiple individuals, allowing each contributor to be verified against a single enrolled template. While extensively studied in face recognition, this vulnerability remains largely unexplored in voice biometrics. Prior work on voice morphing is computationally expensive, non-scalable, and limited to acoustically similar identity pairs, constraining practical deployment. Moreover, existing sound-morphing methods target audio textures, music, or environmental sounds and are not transferable to voice identity manipulation. We propose VoxMorph, a zero-shot framework that produces high-fidelity voice morphs from as little as five seconds of audio per subject without model retraining. Our method disentangles vocal traits into prosody and timbre embeddings, enabling fine-grained interpolation of speaking style and identity. These embeddings are fused via Spherical Linear Interpolation (Slerp) and synthesized using an autoregressive language model coupled with a Conditional Flow Matching network. VoxMorph achieves state-of-the-art performance, delivering a 2.6x gain in audio quality, a 73% reduction in intelligibility errors, and a 67.8% morphing attack success rate on automated speaker verification systems under strict security thresholds. This work establishes a practical and scalable paradigm for voice morphing with significant implications for biometric security. The code and dataset are available on our project page: https://vcbsl.github.io/VoxMorph/
DOOMGAN:High-Fidelity Dynamic Identity Obfuscation Ocular Generative Morphing
Jul 23, 2025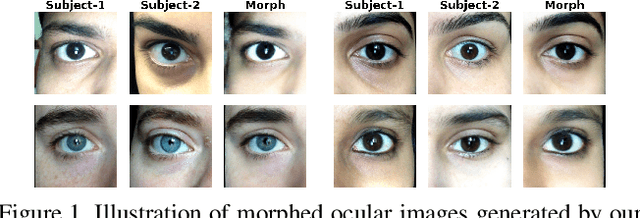
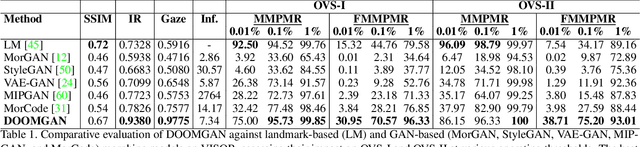
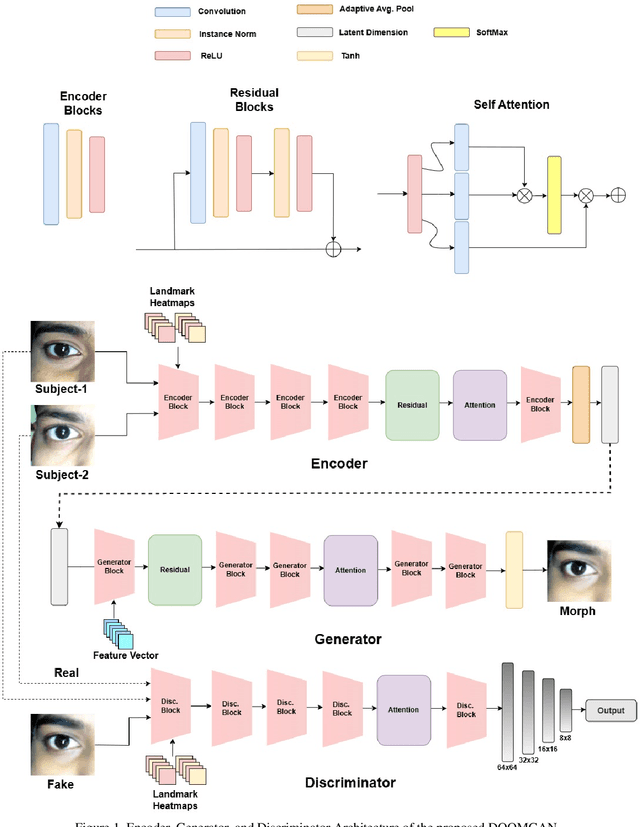
Ocular biometrics in the visible spectrum have emerged as a prominent modality due to their high accuracy, resistance to spoofing, and non-invasive nature. However, morphing attacks, synthetic biometric traits created by blending features from multiple individuals, threaten biometric system integrity. While extensively studied for near-infrared iris and face biometrics, morphing in visible-spectrum ocular data remains underexplored. Simulating such attacks demands advanced generation models that handle uncontrolled conditions while preserving detailed ocular features like iris boundaries and periocular textures. To address this gap, we introduce DOOMGAN, that encompasses landmark-driven encoding of visible ocular anatomy, attention-guided generation for realistic morph synthesis, and dynamic weighting of multi-faceted losses for optimized convergence. DOOMGAN achieves over 20% higher attack success rates than baseline methods under stringent thresholds, along with 20% better elliptical iris structure generation and 30% improved gaze consistency. We also release the first comprehensive ocular morphing dataset to support further research in this domain.