 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOLT3D: Joint Learning of Talking Heads and 3DMM Parameters with Application to Lip-Sync
Jul 28, 2025In this work, we revisit the effectiveness of 3DMM for talking head synthesis by jointly learning a 3D face reconstruction model and a talking head synthesis model. This enables us to obtain a FACS-based blendshape representation of facial expressions that is optimized for talking head synthesis. This contrasts with previous methods that either fit 3DMM parameters to 2D landmarks or rely on pretrained face reconstruction models. Not only does our approach increase the quality of the generated face, but it also allows us to take advantage of the blendshape representation to modify just the mouth region for the purpose of audio-based lip-sync. To this end, we propose a novel lip-sync pipeline that, unlike previous methods, decouples the original chin contour from the lip-synced chin contour, and reduces flickering near the mouth.
Interpretable Convolutional SyncNet
Sep 02, 2024



Because videos in the wild can be out of sync for various reasons, a sync-net is used to bring the video back into sync for tasks that require synchronized videos. Previous state-of-the-art (SOTA) sync-nets use InfoNCE loss, rely on the transformer architecture, or both. Unfortunately, the former makes the model's output difficult to interpret, and the latter is unfriendly with large images, thus limiting the usefulness of sync-nets. In this work, we train a convolutional sync-net using the balanced BCE loss (BBCE), a loss inspired by the binary cross entropy (BCE) and the InfoNCE losses. In contrast to the InfoNCE loss, the BBCE loss does not require complicated sampling schemes. Our model can better handle larger images, and its output can be given a probabilistic interpretation. The probabilistic interpretation allows us to define metrics such as probability at offset and offscreen ratio to evaluate the sync quality of audio-visual (AV) speech datasets. Furthermore, our model achieves SOTA accuracy of $96.5\%$ on the LRS2 dataset and $93.8\%$ on the LRS3 dataset.
How to Use Dropout Correctly on Residual Networks with Batch Normalization
Feb 13, 2023



For the stable optimization of deep neural networks, regularization methods such as dropout and batch normalization have been used in various tasks. Nevertheless, the correct position to apply dropout has rarely been discussed, and different positions have been employed depending on the practitioners. In this study, we investigate the correct position to apply dropout. We demonstrate that for a residual network with batch normalization, applying dropout at certain positions increases the performance, whereas applying dropout at other positions decreases the performance. Based on theoretical analysis, we provide the following guideline for the correct position to apply dropout: apply one dropout after the last batch normalization but before the last weight layer in the residual branch. We provide detailed theoretical explanations to support this claim and demonstrate them through module tests. In addition, we investigate the correct position of dropout in the head that produces the final prediction. Although the current consensus is to apply dropout after global average pooling, we prove that applying dropout before global average pooling leads to a more stable output. The proposed guidelines are validated through experiments using different datasets and models.
Graph Self-Attention for learning graph representation with Transformer
Jan 30, 2022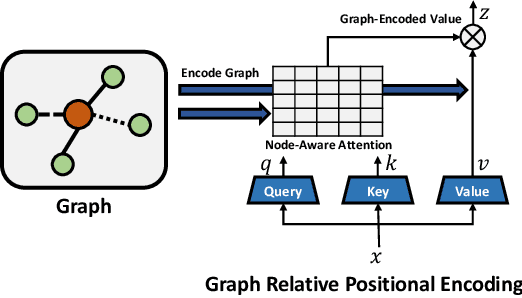

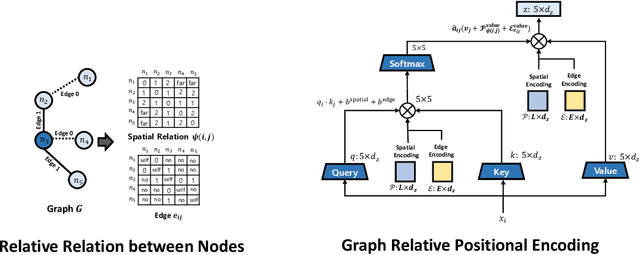
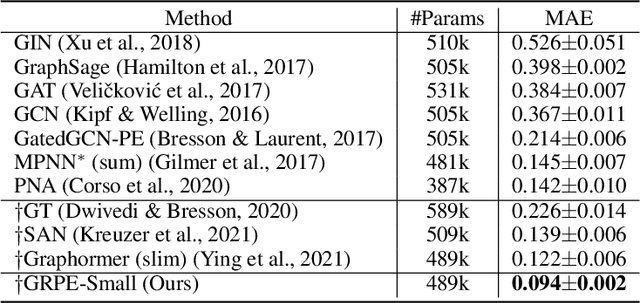
We propose a novel Graph Self-Attention module to enable Transformer models to learn graph representation. We aim to incorporate graph information, on the attention map and hidden representations of Transformer. To this end, we propose context-aware attention which considers the interactions between query, key and graph information. Moreover, we propose graph-embedded value to encode the graph information on the hidden representation. Our extensive experiments and ablation studies validate that our method successfully encodes graph representation on Transformer architecture. Finally, our method achieves state-of-the-art performance on multiple benchmarks of graph representation learning, such as graph classification on images and molecules to graph regression on quantum chemistry.
Mounting Video Metadata on Transformer-based Language Model for Open-ended Video Question Answering
Aug 11, 2021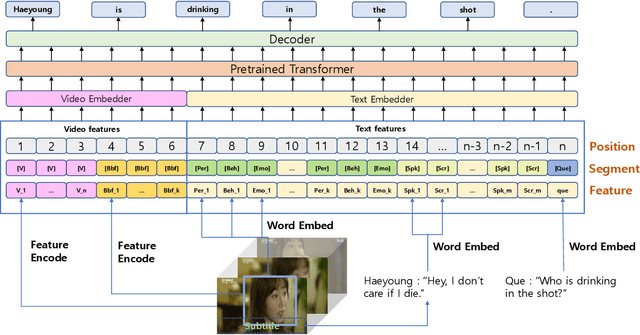

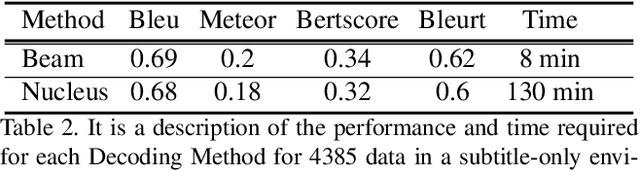
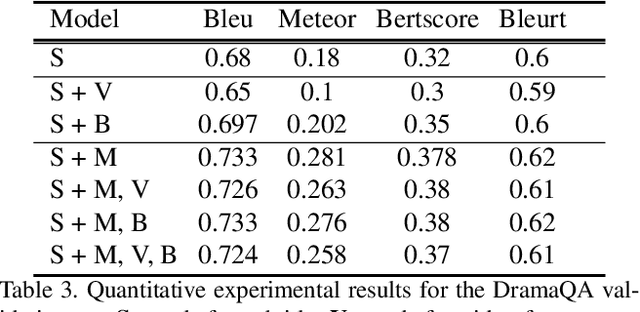
Video question answering has recently received a lot of attention from multimodal video researchers. Most video question answering datasets are usually in the form of multiple-choice. But, the model for the multiple-choice task does not infer the answer. Rather it compares the answer candidates for picking the correct answer. Furthermore, it makes it difficult to extend to other tasks. In this paper, we challenge the existing multiple-choice video question answering by changing it to open-ended video question answering. To tackle open-ended question answering, we use the pretrained GPT2 model. The model is fine-tuned with video inputs and subtitles. An ablation study is performed by changing the existing DramaQA dataset to an open-ended question answering, and it shows that performance can be improved using video metadata.