 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Latent Representation for Joint Text-to-Audio-Visual Synthesis
Nov 07, 2025We propose a text-to-talking-face synthesis framework leveraging latent speech representations from HierSpeech++. A Text-to-Vec module generates Wav2Vec2 embeddings from text, which jointly condition speech and face generation. To handle distribution shifts between clean and TTS-predicted features, we adopt a two-stage training: pretraining on Wav2Vec2 embeddings and finetuning on TTS outputs. This enables tight audio-visual alignment, preserves speaker identity, and produces natural, expressive speech and synchronized facial motion without ground-truth audio at inference. Experiments show that conditioning on TTS-predicted latent features outperforms cascaded pipelines, improving both lip-sync and visual realism.
Assessing Identity Leakage in Talking Face Generation: Metrics and Evaluation Framework
Nov 05, 2025



Inpainting-based talking face generation aims to preserve video details such as pose, lighting, and gestures while modifying only lip motion, often using an identity reference image to maintain speaker consistency. However, this mechanism can introduce lip leaking, where generated lips are influenced by the reference image rather than solely by the driving audio. Such leakage is difficult to detect with standard metrics and conventional test setup. To address this, we propose a systematic evaluation methodology to analyze and quantify lip leakage. Our framework employs three complementary test setups: silent-input generation, mismatched audio-video pairing, and matched audio-video synthesis. We also introduce derived metrics including lip-sync discrepancy and silent-audio-based lip-sync scores. In addition, we study how different identity reference selections affect leakage, providing insights into reference design. The proposed methodology is model-agnostic and establishes a more reliable benchmark for future research in talking face generation.
CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding
Jul 29, 2025We address the problem of Embodied Reference Understanding, which involves predicting the object that a person in the scene is referring to through both pointing gesture and language. Accurately identifying the referent requires multimodal understanding: integrating textual instructions, visual pointing, and scene context. However, existing methods often struggle to effectively leverage visual clues for disambiguation. We also observe that, while the referent is often aligned with the head-to-fingertip line, it occasionally aligns more closely with the wrist-to-fingertip line. Therefore, relying on a single line assumption can be overly simplistic and may lead to suboptimal performance. To address this, we propose a dual-model framework, where one model learns from the head-to-fingertip direction and the other from the wrist-to-fingertip direction. We further introduce a Gaussian ray heatmap representation of these lines and use them as input to provide a strong supervisory signal that encourages the model to better attend to pointing cues. To combine the strengths of both models, we present the CLIP-Aware Pointing Ensemble module, which performs a hybrid ensemble based on CLIP features. Additionally, we propose an object center prediction head as an auxiliary task to further enhance referent localization. We validate our approach through extensive experiments and analysis on the benchmark YouRefIt dataset, achieving an improvement of approximately 4 mAP at the 0.25 IoU threshold.
Mask-Free Audio-driven Talking Face Generation for Enhanced Visual Quality and Identity Preservation
Jul 28, 2025Audio-Driven Talking Face Generation aims at generating realistic videos of talking faces, focusing on accurate audio-lip synchronization without deteriorating any identity-related visual details. Recent state-of-the-art methods are based on inpainting, meaning that the lower half of the input face is masked, and the model fills the masked region by generating lips aligned with the given audio. Hence, to preserve identity-related visual details from the lower half, these approaches additionally require an unmasked identity reference image randomly selected from the same video. However, this common masking strategy suffers from (1) information loss in the input faces, significantly affecting the networks' ability to preserve visual quality and identity details, (2) variation between identity reference and input image degrading reconstruction performance, and (3) the identity reference negatively impacting the model, causing unintended copying of elements unaligned with the audio. To address these issues, we propose a mask-free talking face generation approach while maintaining the 2D-based face editing task. Instead of masking the lower half, we transform the input images to have closed mouths, using a two-step landmark-based approach trained in an unpaired manner. Subsequently, we provide these edited but unmasked faces to a lip adaptation model alongside the audio to generate appropriate lip movements. Thus, our approach needs neither masked input images nor identity reference images. We conduct experiments on the benchmark LRS2 and HDTF datasets and perform various ablation studies to validate our contributions.
Titanic Calling: Low Bandwidth Video Conference from the Titanic Wreck
Oct 15, 2024



In this paper, we report on communication experiments conducted in the summer of 2022 during a deep dive to the wreck of the Titanic. Radio transmission is not possible in deep sea water, and communication links rely on sonar signals. Due to the low bandwidth of sonar signals and the need to communicate readable data, text messaging is used in deep-sea missions. In this paper, we report results and experiences from a messaging system that converts speech to text in a submarine, sends text messages to the surface, and reconstructs those messages as synthetic lip-synchronous videos of the speakers. The resulting system was tested during an actual dive to Titanic in the summer of 2022. We achieved an acceptable latency for a system of such complexity as well as good quality. The system demonstration video can be found at the following link: https://youtu.be/C4lyM86-5Ig
Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation
May 07, 2024



In the task of talking face generation, the objective is to generate a face video with lips synchronized to the corresponding audio while preserving visual details and identity information. Current methods face the challenge of learning accurate lip synchronization while avoiding detrimental effects on visual quality, as well as robustly evaluating such synchronization. To tackle these problems, we propose utilizing an audio-visual speech representation expert (AV-HuBERT) for calculating lip synchronization loss during training. Moreover, leveraging AV-HuBERT's features, we introduce three novel lip synchronization evaluation metrics, aiming to provide a comprehensive assessment of lip synchronization performance. Experimental results, along with a detailed ablation study, demonstrate the effectiveness of our approach and the utility of the proposed evaluation metrics.
Plug the Leaks: Advancing Audio-driven Talking Face Generation by Preventing Unintended Information Flow
Jul 18, 2023



Audio-driven talking face generation is the task of creating a lip-synchronized, realistic face video from given audio and reference frames. This involves two major challenges: overall visual quality of generated images on the one hand, and audio-visual synchronization of the mouth part on the other hand. In this paper, we start by identifying several problematic aspects of synchronization methods in recent audio-driven talking face generation approaches. Specifically, this involves unintended flow of lip and pose information from the reference to the generated image, as well as instabilities during model training. Subsequently, we propose various techniques for obviating these issues: First, a silent-lip reference image generator prevents leaking of lips from the reference to the generated image. Second, an adaptive triplet loss handles the pose leaking problem. Finally, we propose a stabilized formulation of synchronization loss, circumventing aforementioned training instabilities while additionally further alleviating the lip leaking issue. Combining the individual improvements, we present state-of-the art performance on LRS2 and LRW in both synchronization and visual quality. We further validate our design in various ablation experiments, confirming the individual contributions as well as their complementary effects.
A Survey on Computer Vision based Human Analysis in the COVID-19 Era
Nov 07, 2022



The emergence of COVID-19 has had a global and profound impact, not only on society as a whole, but also on the lives of individuals. Various prevention measures were introduced around the world to limit the transmission of the disease, including face masks, mandates for social distancing and regular disinfection in public spaces, and the use of screening applications. These developments also triggered the need for novel and improved computer vision techniques capable of (i) providing support to the prevention measures through an automated analysis of visual data, on the one hand, and (ii) facilitating normal operation of existing vision-based services, such as biometric authentication schemes, on the other. Especially important here, are computer vision techniques that focus on the analysis of people and faces in visual data and have been affected the most by the partial occlusions introduced by the mandates for facial masks. Such computer vision based human analysis techniques include face and face-mask detection approaches, face recognition techniques, crowd counting solutions, age and expression estimation procedures, models for detecting face-hand interactions and many others, and have seen considerable attention over recent years. The goal of this survey is to provide an introduction to the problems induced by COVID-19 into such research and to present a comprehensive review of the work done in the computer vision based human analysis field. Particular attention is paid to the impact of facial masks on the performance of various methods and recent solutions to mitigate this problem. Additionally, a detailed review of existing datasets useful for the development and evaluation of methods for COVID-19 related applications is also provided. Finally, to help advance the field further, a discussion on the main open challenges and future research direction is given.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022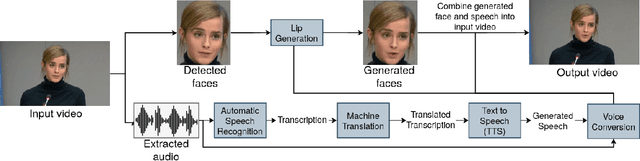
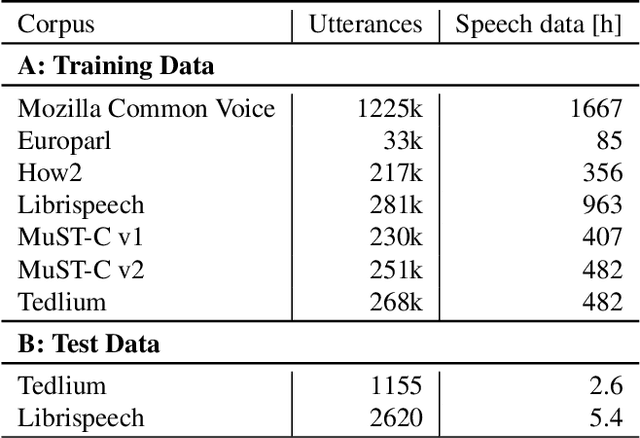
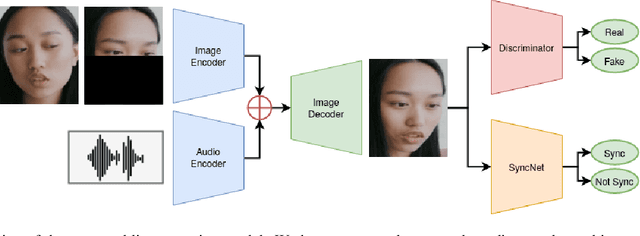
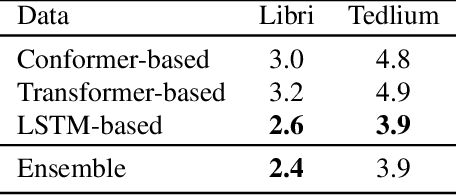
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
Exposure Correction Model to Enhance Image Quality
Apr 22, 2022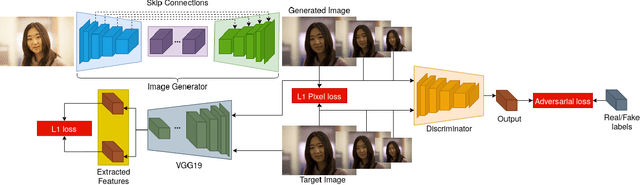
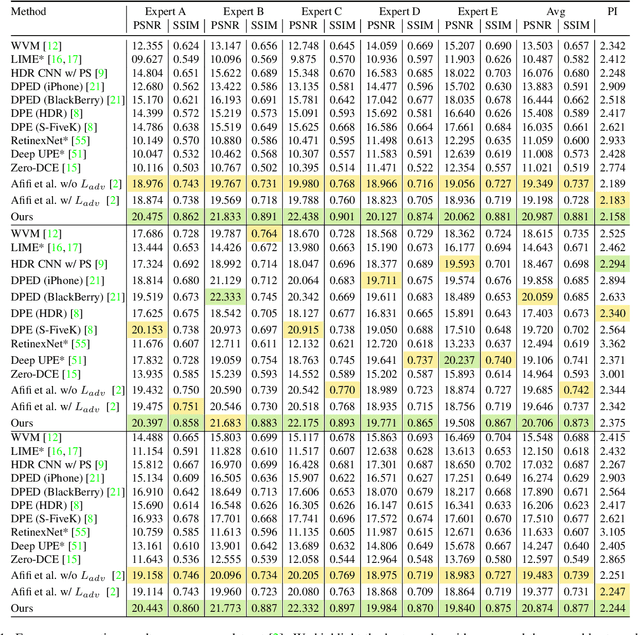

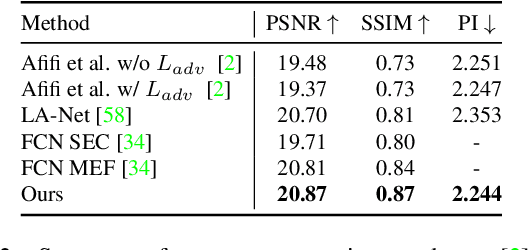
Exposure errors in an image cause a degradation in the contrast and low visibility in the content. In this paper, we address this problem and propose an end-to-end exposure correction model in order to handle both under- and overexposure errors with a single model. Our model contains an image encoder, consecutive residual blocks, and image decoder to synthesize the corrected image. We utilize perceptual loss, feature matching loss, and multi-scale discriminator to increase the quality of the generated image as well as to make the training more stable. The experimental results indicate the effectiveness of proposed model. We achieve the state-of-the-art result on a large-scale exposure dataset. Besides, we investigate the effect of exposure setting of the image on the portrait matting task. We find that under- and overexposed images cause severe degradation in the performance of the portrait matting models. We show that after applying exposure correction with the proposed model, the portrait matting quality increases significantly. https://github.com/yamand16/ExposureCorrection