 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
Reframing Music-Driven 2D Dance Pose Generation as Multi-Channel Image Generation
Dec 12, 2025Recent pose-to-video models can translate 2D pose sequences into photorealistic, identity-preserving dance videos, so the key challenge is to generate temporally coherent, rhythm-aligned 2D poses from music, especially under complex, high-variance in-the-wild distributions. We address this by reframing music-to-dance generation as a music-token-conditioned multi-channel image synthesis problem: 2D pose sequences are encoded as one-hot images, compressed by a pretrained image VAE, and modeled with a DiT-style backbone, allowing us to inherit architectural and training advances from modern text-to-image models and better capture high-variance 2D pose distributions. On top of this formulation, we introduce (i) a time-shared temporal indexing scheme that explicitly synchronizes music tokens and pose latents over time and (ii) a reference-pose conditioning strategy that preserves subject-specific body proportions and on-screen scale while enabling long-horizon segment-and-stitch generation. Experiments on a large in-the-wild 2D dance corpus and the calibrated AIST++2D benchmark show consistent improvements over representative music-to-dance methods in pose- and video-space metrics and human preference, and ablations validate the contributions of the representation, temporal indexing, and reference conditioning. See supplementary videos at https://hot-dance.github.io
Aligning Generative Music AI with Human Preferences: Methods and Challenges
Nov 19, 2025Recent advances in generative AI for music have achieved remarkable fidelity and stylistic diversity, yet these systems often fail to align with nuanced human preferences due to the specific loss functions they use. This paper advocates for the systematic application of preference alignment techniques to music generation, addressing the fundamental gap between computational optimization and human musical appreciation. Drawing on recent breakthroughs including MusicRL's large-scale preference learning, multi-preference alignment frameworks like diffusion-based preference optimization in DiffRhythm+, and inference-time optimization techniques like Text2midi-InferAlign, we discuss how these techniques can address music's unique challenges: temporal coherence, harmonic consistency, and subjective quality assessment. We identify key research challenges including scalability to long-form compositions, reliability amongst others in preference modelling. Looking forward, we envision preference-aligned music generation enabling transformative applications in interactive composition tools and personalized music services. This work calls for sustained interdisciplinary research combining advances in machine learning, music-theory to create music AI systems that truly serve human creative and experiential needs.
Discriminating real and synthetic super-resolved audio samples using embedding-based classifiers
Jan 06, 2026Generative adversarial networks (GANs) and diffusion models have recently achieved state-of-the-art performance in audio super-resolution (ADSR), producing perceptually convincing wideband audio from narrowband inputs. However, existing evaluations primarily rely on signal-level or perceptual metrics, leaving open the question of how closely the distributions of synthetic super-resolved and real wideband audio match. Here we address this problem by analyzing the separability of real and super-resolved audio in various embedding spaces. We consider both middle-band ($4\to 16$~kHz) and full-band ($16\to 48$~kHz) upsampling tasks for speech and music, training linear classifiers to distinguish real from synthetic samples based on multiple types of audio embeddings. Comparisons with objective metrics and subjective listening tests reveal that embedding-based classifiers achieve near-perfect separation, even when the generated audio attains high perceptual quality and state-of-the-art metric scores. This behavior is consistent across datasets and models, including recent diffusion-based approaches, highlighting a persistent gap between perceptual quality and true distributional fidelity in ADSR models.
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Sound and Music Biases in Deep Music Transcription Models: A Systematic Analysis
Dec 16, 2025Automatic Music Transcription (AMT) -- the task of converting music audio into note representations -- has seen rapid progress, driven largely by deep learning systems. Due to the limited availability of richly annotated music datasets, much of the progress in AMT has been concentrated on classical piano music, and even a few very specific datasets. Whether these systems can generalize effectively to other musical contexts remains an open question. Complementing recent studies on distribution shifts in sound (e.g., recording conditions), in this work we investigate the musical dimension -- specifically, variations in genre, dynamics, and polyphony levels. To this end, we introduce the MDS corpus, comprising three distinct subsets -- (1) Genre, (2) Random, and (3) MAEtest -- to emulate different axes of distribution shift. We evaluate the performance of several state-of-the-art AMT systems on the MDS corpus using both traditional information-retrieval and musically-informed performance metrics. Our extensive evaluation isolates and exposes varying degrees of performance degradation under specific distribution shifts. In particular, we measure a note-level F1 performance drop of 20 percentage points due to sound, and 14 due to genre. Generally, we find that dynamics estimation proves more vulnerable to musical variation than onset prediction. Musically informed evaluation metrics, particularly those capturing harmonic structure, help identify potential contributing factors. Furthermore, experiments with randomly generated, non-musical sequences reveal clear limitations in system performance under extreme musical distribution shifts. Altogether, these findings offer new evidence of the persistent impact of the Corpus Bias problem in deep AMT systems.
Generating Piano Music with Transformers: A Comparative Study of Scale, Data, and Metrics
Nov 10, 2025Although a variety of transformers have been proposed for symbolic music generation in recent years, there is still little comprehensive study on how specific design choices affect the quality of the generated music. In this work, we systematically compare different datasets, model architectures, model sizes, and training strategies for the task of symbolic piano music generation. To support model development and evaluation, we examine a range of quantitative metrics and analyze how well they correlate with human judgment collected through listening studies. Our best-performing model, a 950M-parameter transformer trained on 80K MIDI files from diverse genres, produces outputs that are often rated as human-composed in a Turing-style listening survey.
Incorporating Structure and Chord Constraints in Symbolic Transformer-based Melodic Harmonization
Dec 08, 2025Transformer architectures offer significant advantages regarding the generation of symbolic music; their capabilities for incorporating user preferences toward what they generate is being studied under many aspects. This paper studies the inclusion of predefined chord constraints in melodic harmonization, i.e., where a desired chord at a specific location is provided along with the melody as inputs and the autoregressive transformer model needs to incorporate the chord in the harmonization that it generates. The peculiarities of involving such constraints is discussed and an algorithm is proposed for tackling this task. This algorithm is called B* and it combines aspects of beam search and A* along with backtracking to force pretrained transformers to satisfy the chord constraints, at the correct onset position within the correct bar. The algorithm is brute-force and has exponential complexity in the worst case; however, this paper is a first attempt to highlight the difficulties of the problem and proposes an algorithm that offers many possibilities for improvements since it accommodates the involvement of heuristics.
Diff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025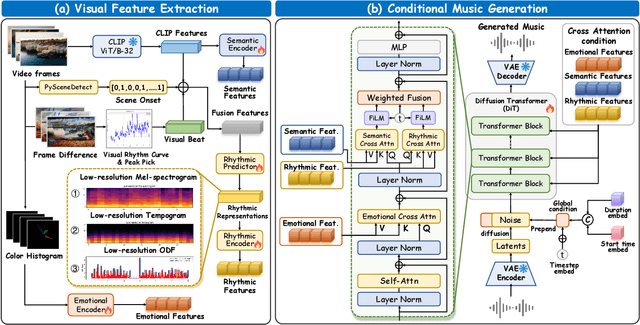
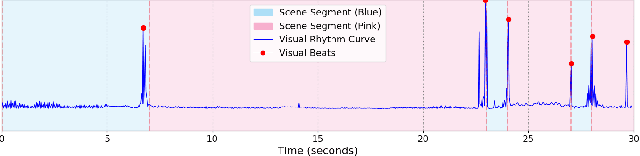
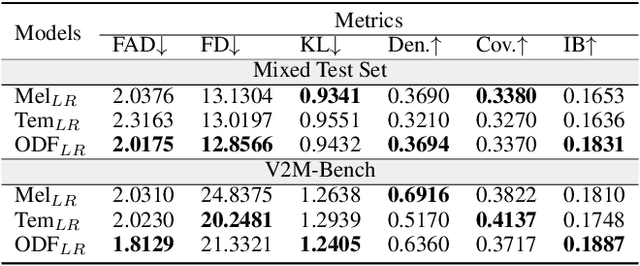
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
On the Joint Minimization of Regularization Loss Functions in Deep Variational Bayesian Methods for Attribute-Controlled Symbolic Music Generation
Nov 10, 2025Explicit latent variable models provide a flexible yet powerful framework for data synthesis, enabling controlled manipulation of generative factors. With latent variables drawn from a tractable probability density function that can be further constrained, these models enable continuous and semantically rich exploration of the output space by navigating their latent spaces. Structured latent representations are typically obtained through the joint minimization of regularization loss functions. In variational information bottleneck models, reconstruction loss and Kullback-Leibler Divergence (KLD) are often linearly combined with an auxiliary Attribute-Regularization (AR) loss. However, balancing KLD and AR turns out to be a very delicate matter. When KLD dominates over AR, generative models tend to lack controllability; when AR dominates over KLD, the stochastic encoder is encouraged to violate the standard normal prior. We explore this trade-off in the context of symbolic music generation with explicit control over continuous musical attributes. We show that existing approaches struggle to jointly minimize both regularization objectives, whereas suitable attribute transformations can help achieve both controllability and regularization of the target latent dimensions.
* IEEE Catalog No.: CFP2540S-ART ISBN: 978-9-46-459362-4
MIDI-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation
Nov 06, 2025We present MIDI-LLM, an LLM for generating multitrack MIDI music from free-form text prompts. Our approach expands a text LLM's vocabulary to include MIDI tokens, and uses a two-stage training recipe to endow text-to-MIDI abilities. By preserving the original LLM's parameter structure, we can directly leverage the vLLM library for accelerated inference. Experiments show that MIDI-LLM achieves higher quality, better text control, and faster inference compared to the recent Text2midi model. Live demo at https://midi-llm-demo.vercel.app.