 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability-in-Action: Enabling Expressive Manipulation and Tacit Understanding by Bending Diffusion Models in ComfyUI
Aug 10, 2025Explainable AI (XAI) in creative contexts can go beyond transparency to support artistic engagement, modifiability, and sustained practice. While curated datasets and training human-scale models can offer artists greater agency and control, large-scale generative models like text-to-image diffusion systems often obscure these possibilities. We suggest that even large models can be treated as creative materials if their internal structure is exposed and manipulable. We propose a craft-based approach to explainability rooted in long-term, hands-on engagement akin to Sch\"on's "reflection-in-action" and demonstrate its application through a model-bending and inspection plugin integrated into the node-based interface of ComfyUI. We demonstrate that by interactively manipulating different parts of a generative model, artists can develop an intuition about how each component influences the output.
Personalizable Long-Context Symbolic Music Infilling with MIDI-RWKV
Jun 16, 2025Existing work in automatic music generation has primarily focused on end-to-end systems that produce complete compositions or continuations. However, because musical composition is typically an iterative process, such systems make it difficult to engage in the back-and-forth between human and machine that is essential to computer-assisted creativity. In this study, we address the task of personalizable, multi-track, long-context, and controllable symbolic music infilling to enhance the process of computer-assisted composition. We present MIDI-RWKV, a novel model based on the RWKV-7 linear architecture, to enable efficient and coherent musical cocreation on edge devices. We also demonstrate that MIDI-RWKV admits an effective method of finetuning its initial state for personalization in the very-low-sample regime. We evaluate MIDI-RWKV and its state tuning on several quantitative and qualitative metrics, and release model weights and code at https://github.com/christianazinn/MIDI-RWKV.
Apollo: An Interactive Environment for Generating Symbolic Musical Phrases using Corpus-based Style Imitation
Apr 18, 2025



With the recent developments in machine intelligence and web technologies, new generative music systems are being explored for assisted composition using machine learning techniques on the web. Such systems are built for various tasks such as melodic, harmonic or rhythm generation, music interpolation, continuation and style imitation. In this paper, we introduce Apollo, an interactive music application for generating symbolic phrases of conventional western music using corpus-based style imitation techniques. In addition to enabling the construction and management of symbolic musical corpora, the system makes it possible for music artists and researchers to generate new musical phrases in the style of the proposed corpus. The system is available as a desktop application. The generated symbolic music materials, encoded in the MIDI format, can be exported or streamed for various purposes including using them as seed material for musical projects. We present the system design, implementation details, discuss and conclude with future work for the system.
Calliope: An Online Generative Music System for Symbolic Multi-Track Composition
Apr 18, 2025



With the rise of artificial intelligence in recent years, there has been a rapid increase in its application towards creative domains, including music. There exist many systems built that apply machine learning approaches to the problem of computer-assisted music composition (CAC). Calliope is a web application that assists users in performing a variety of multi-track composition tasks in the symbolic domain. The user can upload (Musical Instrument Digital Interface) MIDI files, visualize and edit MIDI tracks, and generate partial (via bar in-filling) or complete multi-track content using the Multi-Track Music Machine (MMM). Generation of new MIDI excerpts can be done in batch and can be combined with active playback listening for an enhanced assisted-composition workflow. The user can export generated MIDI materials or directly stream MIDI playback from the system to their favorite Digital Audio Workstation (DAW). We present a demonstration of the system, its features, generative parameters and describe the co-creative workflows that it affords.
Evaluating Human-AI Interaction via Usability, User Experience and Acceptance Measures for MMM-C: A Creative AI System for Music Composition
Apr 18, 2025



With the rise of artificial intelligence (AI), there has been increasing interest in human-AI co-creation in a variety of artistic domains including music as AI-driven systems are frequently able to generate human-competitive artifacts. Now, the implications of such systems for musical practice are being investigated. We report on a thorough evaluation of the user adoption of the Multi-Track Music Machine (MMM) as a co-creative AI tool for music composers. To do this, we integrate MMM into Cubase, a popular Digital Audio Workstation (DAW) by Steinberg, by producing a "1-parameter" plugin interface named MMM-Cubase (MMM-C), which enables human-AI co-composition. We contribute a methodological assemblage as a 3-part mixed method study measuring usability, user experience and technology acceptance of the system across two groups of expert-level composers: hobbyists and professionals. Results show positive usability and acceptance scores. Users report experiences of novelty, surprise and ease of use from using the system, and limitations on controllability and predictability of the interface when generating music. Findings indicate no significant difference between the two user groups.
The GigaMIDI Dataset with Features for Expressive Music Performance Detection
Feb 24, 2025



The Musical Instrument Digital Interface (MIDI), introduced in 1983, revolutionized music production by allowing computers and instruments to communicate efficiently. MIDI files encode musical instructions compactly, facilitating convenient music sharing. They benefit Music Information Retrieval (MIR), aiding in research on music understanding, computational musicology, and generative music. The GigaMIDI dataset contains over 1.4 million unique MIDI files, encompassing 1.8 billion MIDI note events and over 5.3 million MIDI tracks. GigaMIDI is currently the largest collection of symbolic music in MIDI format available for research purposes under fair dealing. Distinguishing between non-expressive and expressive MIDI tracks is challenging, as MIDI files do not inherently make this distinction. To address this issue, we introduce a set of innovative heuristics for detecting expressive music performance. These include the Distinctive Note Velocity Ratio (DNVR) heuristic, which analyzes MIDI note velocity; the Distinctive Note Onset Deviation Ratio (DNODR) heuristic, which examines deviations in note onset times; and the Note Onset Median Metric Level (NOMML) heuristic, which evaluates onset positions relative to metric levels. Our evaluation demonstrates these heuristics effectively differentiate between non-expressive and expressive MIDI tracks. Furthermore, after evaluation, we create the most substantial expressive MIDI dataset, employing our heuristic, NOMML. This curated iteration of GigaMIDI encompasses expressively-performed instrument tracks detected by NOMML, containing all General MIDI instruments, constituting 31% of the GigaMIDI dataset, totalling 1,655,649 tracks.
MIDI-GPT: A Controllable Generative Model for Computer-Assisted Multitrack Music Composition
Jan 28, 2025We present and release MIDI-GPT, a generative system based on the Transformer architecture that is designed for computer-assisted music composition workflows. MIDI-GPT supports the infilling of musical material at the track and bar level, and can condition generation on attributes including: instrument type, musical style, note density, polyphony level, and note duration. In order to integrate these features, we employ an alternative representation for musical material, creating a time-ordered sequence of musical events for each track and concatenating several tracks into a single sequence, rather than using a single time-ordered sequence where the musical events corresponding to different tracks are interleaved. We also propose a variation of our representation allowing for expressiveness. We present experimental results that demonstrate that MIDI-GPT is able to consistently avoid duplicating the musical material it was trained on, generate music that is stylistically similar to the training dataset, and that attribute controls allow enforcing various constraints on the generated material. We also outline several real-world applications of MIDI-GPT, including collaborations with industry partners that explore the integration and evaluation of MIDI-GPT into commercial products, as well as several artistic works produced using it.
Seizing the Means of Production: Exploring the Landscape of Crafting, Adapting and Navigating Generative AI Models in the Visual Arts
Apr 26, 2024

In this paper, we map out the landscape of options available to visual artists for creating personal artworks, including crafting, adapting and navigating deep generative models. Following that, we argue for revisiting model crafting, defined as the design and manipulation of generative models for creative goals, and motivate studying and designing for model crafting as a creative activity in its own right.
Invisible Users: Uncovering End-Users' Requirements for Explainable AI via Explanation Forms and Goals
Feb 15, 2023Non-technical end-users are silent and invisible users of the state-of-the-art explainable artificial intelligence (XAI) technologies. Their demands and requirements for AI explainability are not incorporated into the design and evaluation of XAI techniques, which are developed to explain the rationales of AI decisions to end-users and assist their critical decisions. This makes XAI techniques ineffective or even harmful in high-stakes applications, such as healthcare, criminal justice, finance, and autonomous driving systems. To systematically understand end-users' requirements to support the technical development of XAI, we conducted the EUCA user study with 32 layperson participants in four AI-assisted critical tasks. The study identified comprehensive user requirements for feature-, example-, and rule-based XAI techniques (manifested by the end-user-friendly explanation forms) and XAI evaluation objectives (manifested by the explanation goals), which were shown to be helpful to directly inspire the proposal of new XAI algorithms and evaluation metrics. The EUCA study findings, the identified explanation forms and goals for technical specification, and the EUCA study dataset support the design and evaluation of end-user-centered XAI techniques for accessible, safe, and accountable AI.
Transcending XAI Algorithm Boundaries through End-User-Inspired Design
Aug 18, 2022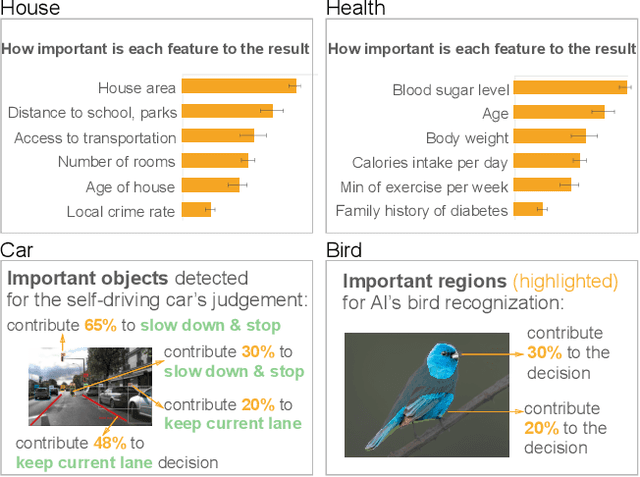
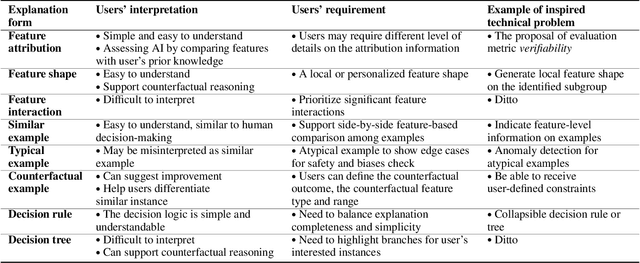
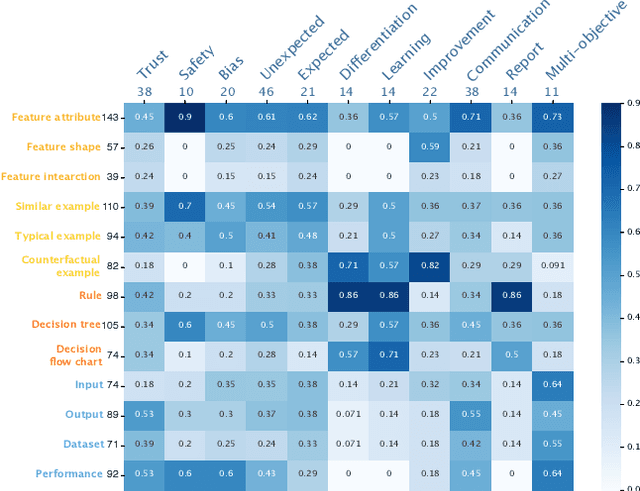
The boundaries of existing explainable artificial intelligence (XAI) algorithms are confined to problems grounded in technical users' demand for explainability. This research paradigm disproportionately ignores the larger group of non-technical end users of XAI, who do not have technical knowledge but need explanations in their AI-assisted critical decisions. Lacking explainability-focused functional support for end users may hinder the safe and responsible use of AI in high-stakes domains, such as healthcare, criminal justice, finance, and autonomous driving systems. In this work, we explore how designing XAI tailored to end users' critical tasks inspires the framing of new technical problems. To elicit users' interpretations and requirements for XAI algorithms, we first identify eight explanation forms as the communication tool between AI researchers and end users, such as explaining using features, examples, or rules. Using the explanation forms, we then conduct a user study with 32 layperson participants in the context of achieving different explanation goals (such as verifying AI decisions, and improving user's predicted outcomes) in four critical tasks. Based on the user study findings, we identify and formulate novel XAI technical problems, and propose an evaluation metric verifiability based on users' explanation goal of verifying AI decisions. Our work shows that grounding the technical problem in end users' use of XAI can inspire new research questions. Such end-user-inspired research questions have the potential to promote social good by democratizing AI and ensuring the responsible use of AI in critical domains.