 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhala: Scaling Acoustic Token Language Models Toward High-Fidelity Music Generation
May 03, 2026A common design pattern in high-quality music generation is to handle structure and fidelity in different representation spaces: a generator first models high-level structure, followed by diffusion-based or neural decoding stages that reconstruct fine details. In this work, we explore an alternative view: both may be progressively modeled within a single deep acoustic-token hierarchy. To study this, we build a 64-layer residual vector quantization (RVQ) acoustic representation and propose a two-stage coarse-to-fine generation framework. A backbone model first generates coarse acoustic tokens for the full track, and a super-resolution model then completes finer tokens within the same acoustic token space. The super-resolution stage works at full-track scale and refines tokens layer by layer while running in parallel over time, leading to a fixed 62-step inference process. To jointly improve lyric alignment and fine-detail reconstruction, we further introduce hybrid-attention training: the alignment objective uses causal attention, while layer-wise refinement uses full attention. A key finding is that text--vocal alignment can emerge within pure acoustic-token language modeling, without requiring a separate semantic token stage. Moreover, initializing the super-resolution model from the trained backbone significantly improves convergence and final quality. Taken together, our results suggest that high-quality music generation can be effectively pursued without separating structure and fidelity into heterogeneous representation spaces. Instead, both can be progressively modeled within a unified acoustic-token hierarchy, pointing toward a simpler and more unified path to high-quality music generation.
SymphonyGen: 3D Hierarchical Orchestral Generation with Controllable Harmony Skeleton
Apr 28, 2026Generating symphonic music requires simultaneously managing high-level structural form and dense, multi-track orchestration. Existing symbolic models often struggle with a "complexity-control imbalance", in which scaling bottlenecks limit long-term granular steerability. We present SymphonyGen, a 3D hierarchical framework for contemporary cinematic orchestration. SymphonyGen employs a cascading decoder architecture that decomposes the Bar, Track, and Event axes, improving computational efficiency and scalability over conventional 1D or 2D models. We introduce "short-score" conditioning via a beat-quantized multi-voice harmony skeleton, enabling outline control while preserving textural diversity. The model is further refined using Group Relative Policy Optimization (GRPO) with a cross-modal audio-perceptual reward, aligning symbolic output with modern acoustic expectations. Additionally, we implement a dissonance-averse sampling algorithm to suppress unintended tonal clashes during inference. Objective evaluations show that both reinforcement learning and dissonance-averse sampling effectively enhance harmonic cleanliness while maintaining melodic expression. Subjective evaluations demonstrate that SymphonyGen outperforms baselines in musicality and preference for orchestral music generation. Demo page: https://symphonygen.github.io/
AI Psychometrics: Evaluating the Psychological Reasoning of Large Language Models with Psychometric Validities
Mar 11, 2026The immense number of parameters and deep neural networks make large language models (LLMs) rival the complexity of human brains, which also makes them opaque ``black box'' systems that are challenging to evaluate and interpret. AI Psychometrics is an emerging field that aims to tackle these challenges by applying psychometric methodologies to evaluate and interpret the psychological traits and processes of artificial intelligence (AI) systems. This paper investigates the application of AI Psychometrics to evaluate the psychological reasoning and overall psychometric validity of four prominent LLMs: GPT-3.5, GPT-4, LLaMA-2, and LLaMA-3. Using the Technology Acceptance Model (TAM), we examined convergent, discriminant, predictive, and external validity across these models. Our findings reveal that the responses from all these models generally met all validity criteria. Moreover, higher-performing models like GPT-4 and LLaMA-3 consistently demonstrated superior psychometric validity compared to their predecessors, GPT-3.5 and LLaMA-2. These results help to establish the validity of applying AI Psychometrics to evaluate and interpret large language models.
* Accepted for publication in the Proceedings of the 58th Hawaii International Conference on System Sciences (HICSS), 2025
TISDiSS: A Training-Time and Inference-Time Scalable Framework for Discriminative Source Separation
Sep 19, 2025Source separation is a fundamental task in speech, music, and audio processing, and it also provides cleaner and larger data for training generative models. However, improving separation performance in practice often depends on increasingly large networks, inflating training and deployment costs. Motivated by recent advances in inference-time scaling for generative modeling, we propose Training-Time and Inference-Time Scalable Discriminative Source Separation (TISDiSS), a unified framework that integrates early-split multi-loss supervision, shared-parameter design, and dynamic inference repetitions. TISDiSS enables flexible speed-performance trade-offs by adjusting inference depth without retraining additional models. We further provide systematic analyses of architectural and training choices and show that training with more inference repetitions improves shallow-inference performance, benefiting low-latency applications. Experiments on standard speech separation benchmarks demonstrate state-of-the-art performance with a reduced parameter count, establishing TISDiSS as a scalable and practical framework for adaptive source separation.
ELGAR: Expressive Cello Performance Motion Generation for Audio Rendition
May 07, 2025The art of instrument performance stands as a vivid manifestation of human creativity and emotion. Nonetheless, generating instrument performance motions is a highly challenging task, as it requires not only capturing intricate movements but also reconstructing the complex dynamics of the performer-instrument interaction. While existing works primarily focus on modeling partial body motions, we propose Expressive ceLlo performance motion Generation for Audio Rendition (ELGAR), a state-of-the-art diffusion-based framework for whole-body fine-grained instrument performance motion generation solely from audio. To emphasize the interactive nature of the instrument performance, we introduce Hand Interactive Contact Loss (HICL) and Bow Interactive Contact Loss (BICL), which effectively guarantee the authenticity of the interplay. Moreover, to better evaluate whether the generated motions align with the semantic context of the music audio, we design novel metrics specifically for string instrument performance motion generation, including finger-contact distance, bow-string distance, and bowing score. Extensive evaluations and ablation studies are conducted to validate the efficacy of the proposed methods. In addition, we put forward a motion generation dataset SPD-GEN, collated and normalized from the MoCap dataset SPD. As demonstrated, ELGAR has shown great potential in generating instrument performance motions with complicated and fast interactions, which will promote further development in areas such as animation, music education, interactive art creation, etc.
NotaGen: Advancing Musicality in Symbolic Music Generation with Large Language Model Training Paradigms
Feb 26, 2025We introduce NotaGen, a symbolic music generation model aiming to explore the potential of producing high-quality classical sheet music. Inspired by the success of Large Language Models (LLMs), NotaGen adopts pre-training, fine-tuning, and reinforcement learning paradigms (henceforth referred to as the LLM training paradigms). It is pre-trained on 1.6M pieces of music, and then fine-tuned on approximately 9K high-quality classical compositions conditioned on "period-composer-instrumentation" prompts. For reinforcement learning, we propose the CLaMP-DPO method, which further enhances generation quality and controllability without requiring human annotations or predefined rewards. Our experiments demonstrate the efficacy of CLaMP-DPO in symbolic music generation models with different architectures and encoding schemes. Furthermore, subjective A/B tests show that NotaGen outperforms baseline models against human compositions, greatly advancing musical aesthetics in symbolic music generation. The project homepage is https://electricalexis.github.io/notagen-demo.
CLaMP 2: Multimodal Music Information Retrieval Across 101 Languages Using Large Language Models
Oct 17, 2024



Challenges in managing linguistic diversity and integrating various musical modalities are faced by current music information retrieval systems. These limitations reduce their effectiveness in a global, multimodal music environment. To address these issues, we introduce CLaMP 2, a system compatible with 101 languages that supports both ABC notation (a text-based musical notation format) and MIDI (Musical Instrument Digital Interface) for music information retrieval. CLaMP 2, pre-trained on 1.5 million ABC-MIDI-text triplets, includes a multilingual text encoder and a multimodal music encoder aligned via contrastive learning. By leveraging large language models, we obtain refined and consistent multilingual descriptions at scale, significantly reducing textual noise and balancing language distribution. Our experiments show that CLaMP 2 achieves state-of-the-art results in both multilingual semantic search and music classification across modalities, thus establishing a new standard for inclusive and global music information retrieval.
MelodyT5: A Unified Score-to-Score Transformer for Symbolic Music Processing
Jul 02, 2024



In the domain of symbolic music research, the progress of developing scalable systems has been notably hindered by the scarcity of available training data and the demand for models tailored to specific tasks. To address these issues, we propose MelodyT5, a novel unified framework that leverages an encoder-decoder architecture tailored for symbolic music processing in ABC notation. This framework challenges the conventional task-specific approach, considering various symbolic music tasks as score-to-score transformations. Consequently, it integrates seven melody-centric tasks, from generation to harmonization and segmentation, within a single model. Pre-trained on MelodyHub, a newly curated collection featuring over 261K unique melodies encoded in ABC notation and encompassing more than one million task instances, MelodyT5 demonstrates superior performance in symbolic music processing via multi-task transfer learning. Our findings highlight the efficacy of multi-task transfer learning in symbolic music processing, particularly for data-scarce tasks, challenging the prevailing task-specific paradigms and offering a comprehensive dataset and framework for future explorations in this domain.
Beyond Language Models: Byte Models are Digital World Simulators
Feb 29, 2024



Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour. It has almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour, with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world.
CCOM-HuQin: an Annotated Multimodal Chinese Fiddle Performance Dataset
Sep 14, 2022
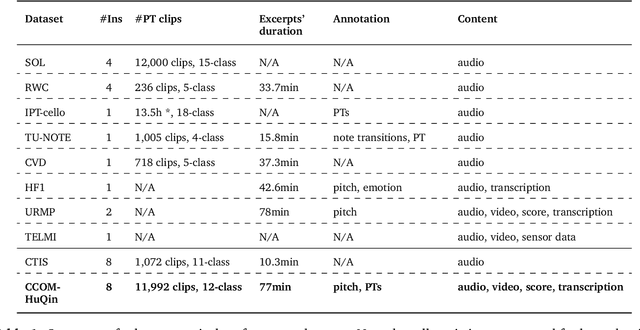
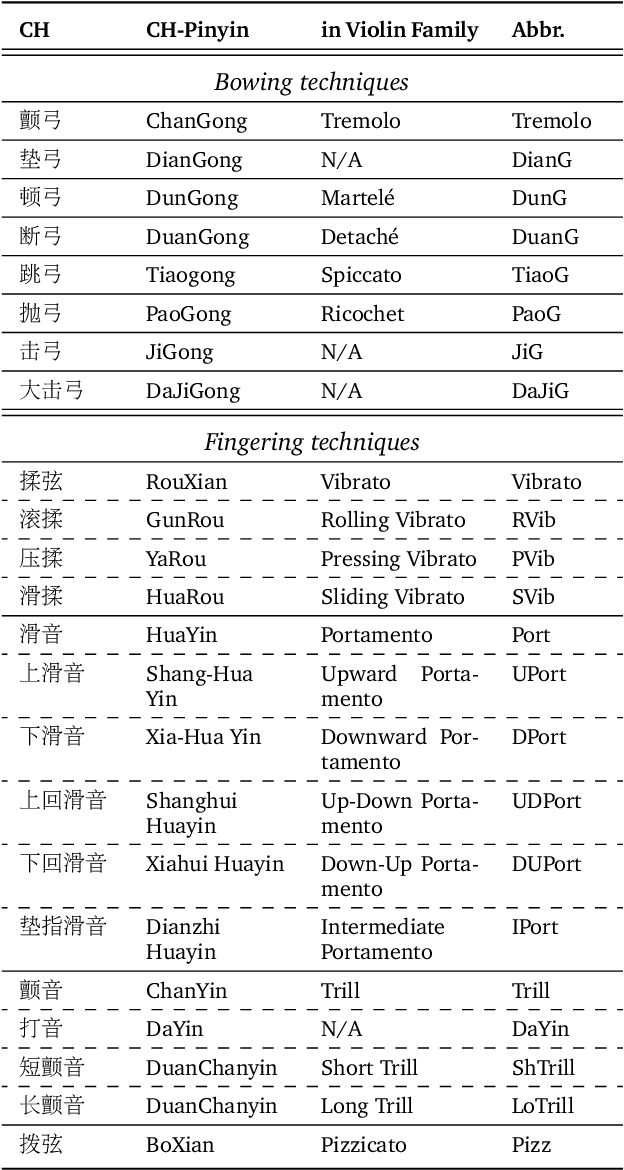
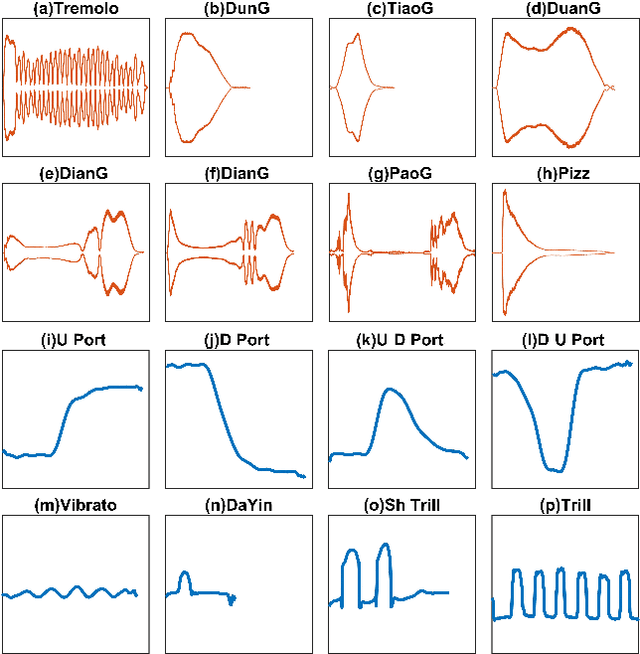
HuQin is a family of traditional Chinese bowed string instruments. Playing techniques(PTs) embodied in various playing styles add abundant emotional coloring and aesthetic feelings to HuQin performance. The complex applied techniques make HuQin music a challenging source for fundamental MIR tasks such as pitch analysis, transcription and score-audio alignment. In this paper, we present a multimodal performance dataset of HuQin music that contains audio-visual recordings of 11,992 single PT clips and 57 annotated musical pieces of classical excerpts. We systematically describe the HuQin PT taxonomy based on musicological theory and practical use cases. Then we introduce the dataset creation methodology and highlight the annotation principles featuring PTs. We analyze the statistics in different aspects to demonstrate the variety of PTs played in HuQin subcategories and perform preliminary experiments to show the potential applications of the dataset in various MIR tasks and cross-cultural music studies. Finally, we propose future work to be extended on the dataset.