 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Supervised Action Recognition
Papers and Code
ASMa: Asymmetric Spatio-temporal Masking for Skeleton Action Representation Learning
Feb 05, 2026Self-supervised learning (SSL) has shown remarkable success in skeleton-based action recognition by leveraging data augmentations to learn meaningful representations. However, existing SSL methods rely on data augmentations that predominantly focus on masking high-motion frames and high-degree joints such as joints with degree 3 or 4. This results in biased and incomplete feature representations that struggle to generalize across varied motion patterns. To address this, we propose Asymmetric Spatio-temporal Masking (ASMa) for Skeleton Action Representation Learning, a novel combination of masking to learn a full spectrum of spatio-temporal dynamics inherent in human actions. ASMa employs two complementary masking strategies: one that selectively masks high-degree joints and low-motion, and another that masks low-degree joints and high-motion frames. These masking strategies ensure a more balanced and comprehensive skeleton representation learning. Furthermore, we introduce a learnable feature alignment module to effectively align the representations learned from both masked views. To facilitate deployment in resource-constrained settings and on low-resource devices, we compress the learned and aligned representation into a lightweight model using knowledge distillation. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets demonstrate that our approach outperforms existing SSL methods with an average improvement of 2.7-4.4% in fine-tuning and up to 5.9% in transfer learning to noisy datasets and achieves competitive performance compared to fully supervised baselines. Our distilled model achieves 91.4% parameter reduction and 3x faster inference on edge devices while maintaining competitive accuracy, enabling practical deployment in resource-constrained scenarios.
Variational Contrastive Learning for Skeleton-based Action Recognition
Jan 12, 2026In recent years, self-supervised representation learning for skeleton-based action recognition has advanced with the development of contrastive learning methods. However, most of contrastive paradigms are inherently discriminative and often struggle to capture the variability and uncertainty intrinsic to human motion. To address this issue, we propose a variational contrastive learning framework that integrates probabilistic latent modeling with contrastive self-supervised learning. This formulation enables the learning of structured and semantically meaningful representations that generalize across different datasets and supervision levels. Extensive experiments on three widely used skeleton-based action recognition benchmarks show that our proposed method consistently outperforms existing approaches, particularly in low-label regimes. Moreover, qualitative analyses show that the features provided by our method are more relevant given the motion and sample characteristics, with more focus on important skeleton joints, when compared to the other methods.
Action100M: A Large-scale Video Action Dataset
Jan 15, 2026Inferring physical actions from visual observations is a fundamental capability for advancing machine intelligence in the physical world. Achieving this requires large-scale, open-vocabulary video action datasets that span broad domains. We introduce Action100M, a large-scale dataset constructed from 1.2M Internet instructional videos (14.6 years of duration), yielding O(100 million) temporally localized segments with open-vocabulary action supervision and rich captions. Action100M is generated by a fully automated pipeline that (i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings, (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions, and (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption). Training VL-JEPA on Action100M demonstrates consistent data-scaling improvements and strong zero-shot performance across diverse action recognition benchmarks, establishing Action100M as a new foundation for scalable research in video understanding and world modeling.
COMPOSE: Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation
Jan 14, 20263D pose estimation from sparse multi-views is a critical task for numerous applications, including action recognition, sports analysis, and human-robot interaction. Optimization-based methods typically follow a two-stage pipeline, first detecting 2D keypoints in each view and then associating these detections across views to triangulate the 3D pose. Existing methods rely on mere pairwise associations to model this correspondence problem, treating global consistency between views (i.e., cycle consistency) as a soft constraint. Yet, reconciling these constraints for multiple views becomes brittle when spurious associations propagate errors. We thus propose COMPOSE, a novel framework that formulates multi-view pose correspondence matching as a hypergraph partitioning problem rather than through pairwise association. While the complexity of the resulting integer linear program grows exponentially in theory, we introduce an efficient geometric pruning strategy to substantially reduce the search space. COMPOSE achieves improvements of up to 23% in average precision over previous optimization-based methods and up to 11% over self-supervised end-to-end learned methods, offering a promising solution to a widely studied problem.
Skeleton-Snippet Contrastive Learning with Multiscale Feature Fusion for Action Localization
Dec 22, 2025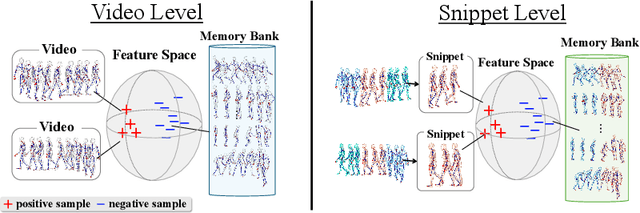
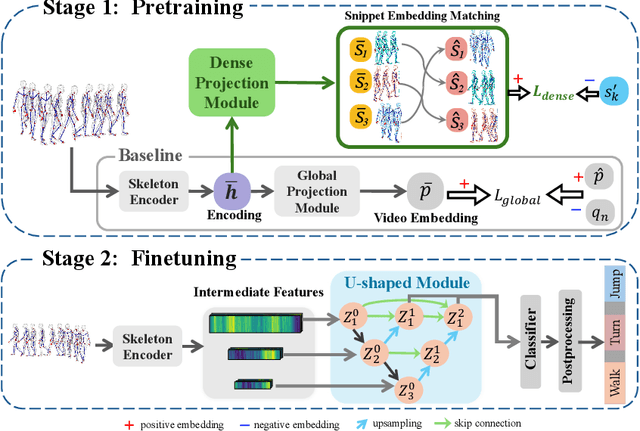
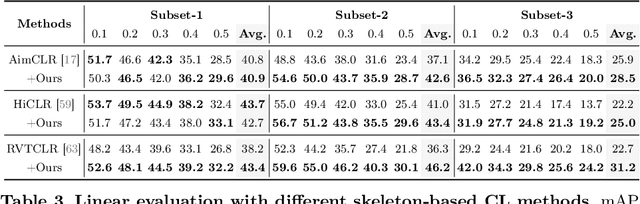
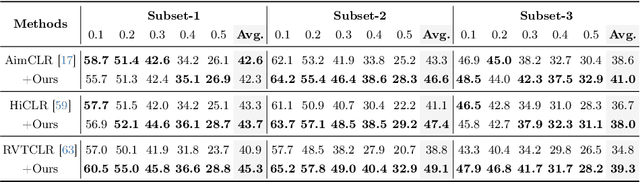
The self-supervised pretraining paradigm has achieved great success in learning 3D action representations for skeleton-based action recognition using contrastive learning. However, learning effective representations for skeleton-based temporal action localization remains challenging and underexplored. Unlike video-level {action} recognition, detecting action boundaries requires temporally sensitive features that capture subtle differences between adjacent frames where labels change. To this end, we formulate a snippet discrimination pretext task for self-supervised pretraining, which densely projects skeleton sequences into non-overlapping segments and promotes features that distinguish them across videos via contrastive learning. Additionally, we build on strong backbones of skeleton-based action recognition models by fusing intermediate features with a U-shaped module to enhance feature resolution for frame-level localization. Our approach consistently improves existing skeleton-based contrastive learning methods for action localization on BABEL across diverse subsets and evaluation protocols. We also achieve state-of-the-art transfer learning performance on PKUMMD with pretraining on NTU RGB+D and BABEL.
DoGCLR: Dominance-Game Contrastive Learning Network for Skeleton-Based Action Recognition
Nov 19, 2025Existing self-supervised contrastive learning methods for skeleton-based action recognition often process all skeleton regions uniformly, and adopt a first-in-first-out (FIFO) queue to store negative samples, which leads to motion information loss and non-optimal negative sample selection. To address these challenges, this paper proposes Dominance-Game Contrastive Learning network for skeleton-based action Recognition (DoGCLR), a self-supervised framework based on game theory. DoGCLR models the construction of positive and negative samples as a dynamic Dominance Game, where both sample types interact to reach an equilibrium that balances semantic preservation and discriminative strength. Specifically, a spatio-temporal dual weight localization mechanism identifies key motion regions and guides region-wise augmentations to enhance motion diversity while maintaining semantics. In parallel, an entropy-driven dominance strategy manages the memory bank by retaining high entropy (hard) negatives and replacing low-entropy (weak) ones, ensuring consistent exposure to informative contrastive signals. Extensive experiments are conducted on NTU RGB+D and PKU-MMD datasets. On NTU RGB+D 60 X-Sub/X-View, DoGCLR achieves 81.1%/89.4% accuracy, and on NTU RGB+D 120 X-Sub/X-Set, DoGCLR achieves 71.2%/75.5% accuracy, surpassing state-of-the-art methods by 0.1%, 2.7%, 1.1%, and 2.3%, respectively. On PKU-MMD Part I/Part II, DoGCLR performs comparably to the state-of-the-art methods and achieves a 1.9% higher accuracy on Part II, highlighting its strong robustness on more challenging scenarios.
Privacy Beyond Pixels: Latent Anonymization for Privacy-Preserving Video Understanding
Nov 11, 2025We introduce a novel formulation of visual privacy preservation for video foundation models that operates entirely in the latent space. While spatio-temporal features learned by foundation models have deepened general understanding of video content, sharing or storing these extracted visual features for downstream tasks inadvertently reveals sensitive personal information like skin color, gender, or clothing. Current privacy preservation methods focus on input-pixel-level anonymization, which requires retraining the entire utility video model and results in task-specific anonymization, making them unsuitable for recent video foundational models. To address these challenges, we introduce a lightweight Anonymizing Adapter Module (AAM) that removes private information from video features while retaining general task utility. AAM can be applied in a plug-and-play fashion to frozen video encoders, minimizing the computational burden of finetuning and re-extracting features. Our framework employs three newly designed training objectives: (1) a clip-level self-supervised privacy objective to reduce mutual information between static clips, (2) a co-training objective to retain utility across seen tasks, and (3) a latent consistency loss for generalization on unseen tasks. Our extensive evaluations demonstrate a significant 35% reduction in privacy leakage while maintaining near-baseline utility performance across various downstream tasks: Action Recognition (Kinetics400, UCF101, HMDB51), Temporal Action Detection (THUMOS14), and Anomaly Detection (UCF-Crime). We also provide an analysis on anonymization for sensitive temporal attribute recognition. Additionally, we propose new protocols for assessing gender bias in action recognition models, showing that our method effectively mitigates such biases and promotes more equitable video understanding.
RCMCL: A Unified Contrastive Learning Framework for Robust Multi-Modal (RGB-D, Skeleton, Point Cloud) Action Understanding
Nov 06, 2025Human action recognition (HAR) with multi-modal inputs (RGB-D, skeleton, point cloud) can achieve high accuracy but typically relies on large labeled datasets and degrades sharply when sensors fail or are noisy. We present Robust Cross-Modal Contrastive Learning (RCMCL), a self-supervised framework that learns modality-invariant representations and remains reliable under modality dropout and corruption. RCMCL jointly optimizes (i) a cross-modal contrastive objective that aligns heterogeneous streams, (ii) an intra-modal self-distillation objective that improves view-invariance and reduces redundancy, and (iii) a degradation simulation objective that explicitly trains models to recover from masked or corrupted inputs. At inference, an Adaptive Modality Gating (AMG) network assigns data-driven reliability weights to each modality for robust fusion. On NTU RGB+D 120 (CS/CV) and UWA3D-II, RCMCL attains state-of-the-art accuracy in standard settings and exhibits markedly better robustness: under severe dual-modality dropout it shows only an 11.5% degradation, significantly outperforming strong supervised fusion baselines. These results indicate that self-supervised cross-modal alignment, coupled with explicit degradation modeling and adaptive fusion, is key to deployable multi-modal HAR.
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025



Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
Towards Efficient General Feature Prediction in Masked Skeleton Modeling
Sep 03, 2025



Recent advances in the masked autoencoder (MAE) paradigm have significantly propelled self-supervised skeleton-based action recognition. However, most existing approaches limit reconstruction targets to raw joint coordinates or their simple variants, resulting in computational redundancy and limited semantic representation. To address this, we propose a novel General Feature Prediction framework (GFP) for efficient mask skeleton modeling. Our key innovation is replacing conventional low-level reconstruction with high-level feature prediction that spans from local motion patterns to global semantic representations. Specifically, we introduce a collaborative learning framework where a lightweight target generation network dynamically produces diversified supervision signals across spatial-temporal hierarchies, avoiding reliance on pre-computed offline features. The framework incorporates constrained optimization to ensure feature diversity while preventing model collapse. Experiments on NTU RGB+D 60, NTU RGB+D 120 and PKU-MMD demonstrate the benefits of our approach: Computational efficiency (with 6.2$\times$ faster training than standard masked skeleton modeling methods) and superior representation quality, achieving state-of-the-art performance in various downstream tasks.