 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Protocols and Validation for Cameras in Indoor Healthcare Monitoring
Jun 24, 2026Camera-based monitoring systems are increasingly adopted in healthcare settings for the continuous assessment of patient movement and activities. However, their technical performance under real-world indoor conditions remains insufficiently characterised, preventing appropriate camera selection for clinical or home adoption and reproducibility. Existing validation studies typically assess either device metrological performance or algorithm accuracy in isolation, and often do not systematically account for practical deployment factors, such as lighting variability, occlusions, and camera positioning. We present two technical validation protocols: the first evaluates the metrological performance of RGB and RGB-D cameras, and the second assesses their use in supporting human pose estimation, validated using state-of-the-art pose estimators. The proposed protocols systematically assess five cameras, four RGB-D and one RGB, under controlled variations in lighting, camera height, viewing angle, and occlusion level within representative indoor scenarios. The experimental results show that metrological performance varies substantially across cameras, with depth bias at 5 m ranging from 50 mm to over 1400 mm depending on the device. For 2D pose estimation, all cameras achieve broadly comparable accuracy, with mean mAP between approximately 78% and 90% across cameras and estimators, whereas 3D reconstruction error differs markedly across devices, with MPJPE ranging from 104 mm to 365 mm, closely reflecting underlying depth-sensing quality. Environmental factors have a camera- and estimator-dependent effect on 3D performance, while camera mounting height has minimal influence within the evaluated range. This work provides evidence-based guidance for the selection and deployment of cameras in healthcare monitoring applications, addressing an important gap in current technical validation practice.
Skeleton-Snippet Contrastive Learning with Multiscale Feature Fusion for Action Localization
Dec 22, 2025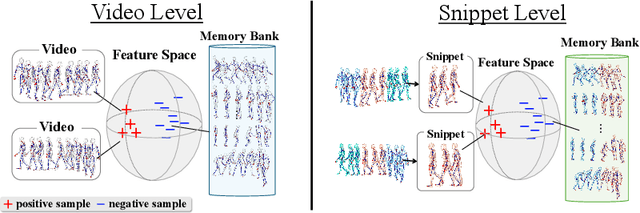
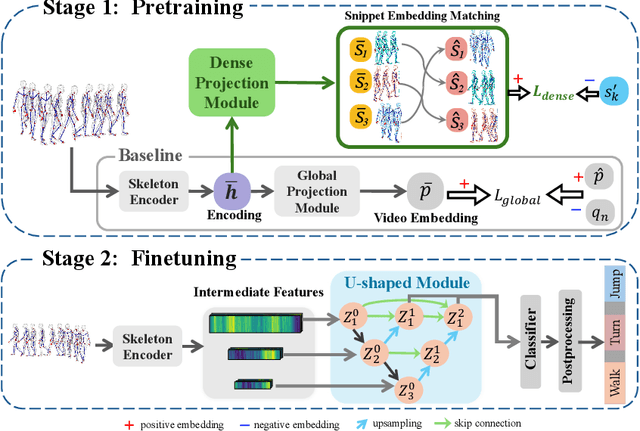
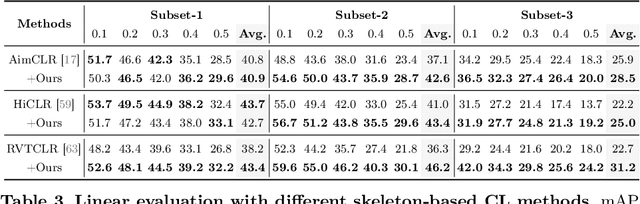
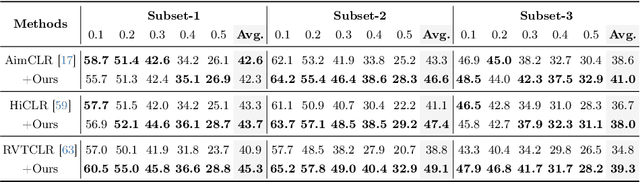
The self-supervised pretraining paradigm has achieved great success in learning 3D action representations for skeleton-based action recognition using contrastive learning. However, learning effective representations for skeleton-based temporal action localization remains challenging and underexplored. Unlike video-level {action} recognition, detecting action boundaries requires temporally sensitive features that capture subtle differences between adjacent frames where labels change. To this end, we formulate a snippet discrimination pretext task for self-supervised pretraining, which densely projects skeleton sequences into non-overlapping segments and promotes features that distinguish them across videos via contrastive learning. Additionally, we build on strong backbones of skeleton-based action recognition models by fusing intermediate features with a U-shaped module to enhance feature resolution for frame-level localization. Our approach consistently improves existing skeleton-based contrastive learning methods for action localization on BABEL across diverse subsets and evaluation protocols. We also achieve state-of-the-art transfer learning performance on PKUMMD with pretraining on NTU RGB+D and BABEL.
Your Turn: Real-World Turning Angle Estimation for Parkinson's Disease Severity Assessment
Aug 15, 2024People with Parkinson's Disease (PD) often experience progressively worsening gait, including changes in how they turn around, as the disease progresses. Existing clinical rating tools are not capable of capturing hour-by-hour variations of PD symptoms, as they are confined to brief assessments within clinic settings. Measuring real-world gait turning angles continuously and passively is a component step towards using gait characteristics as sensitive indicators of disease progression in PD. This paper presents a deep learning-based approach to automatically quantify turning angles by extracting 3D skeletons from videos and calculating the rotation of hip and knee joints. We utilise state-of-the-art human pose estimation models, Fastpose and Strided Transformer, on a total of 1386 turning video clips from 24 subjects (12 people with PD and 12 healthy control volunteers), trimmed from a PD dataset of unscripted free-living videos in a home-like setting (Turn-REMAP). We also curate a turning video dataset, Turn-H3.6M, from the public Human3.6M human pose benchmark with 3D ground truth, to further validate our method. Previous gait research has primarily taken place in clinics or laboratories evaluating scripted gait outcomes, but this work focuses on real-world settings where complexities exist, such as baggy clothing and poor lighting. Due to difficulties in obtaining accurate ground truth data in a free-living setting, we quantise the angle into the nearest bin $45^\circ$ based on the manual labelling of expert clinicians. Our method achieves a turning calculation accuracy of 41.6%, a Mean Absolute Error (MAE) of 34.7{\deg}, and a weighted precision WPrec of 68.3% for Turn-REMAP. This is the first work to explore the use of single monocular camera data to quantify turns by PD patients in a home setting.