 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMmdetection
MMDetection is an open source object detection toolbox based on PyTorch that supports a wide range of object detection models.
Papers and Code
Evaluating Stenosis Detection with Grounding DINO, YOLO, and DINO-DETR
Mar 03, 2025



Detecting stenosis in coronary angiography is vital for diagnosing and managing cardiovascular diseases. This study evaluates the performance of state-of-the-art object detection models on the ARCADE dataset using the MMDetection framework. The models are assessed using COCO evaluation metrics, including Intersection over Union (IoU), Average Precision (AP), and Average Recall (AR). Results indicate variations in detection accuracy across different models, attributed to differences in algorithmic design, transformer-based vs. convolutional architectures. Additionally, several challenges were encountered during implementation, such as compatibility issues between PyTorch, CUDA, and MMDetection, as well as dataset inconsistencies in ARCADE. The findings provide insights into model selection for stenosis detection and highlight areas for further improvement in deep learning-based coronary artery disease diagnosis.
Replication Study and Benchmarking of Real-Time Object Detection Models
May 11, 2024This work examines the reproducibility and benchmarking of state-of-the-art real-time object detection models. As object detection models are often used in real-world contexts, such as robotics, where inference time is paramount, simply measuring models' accuracy is not enough to compare them. We thus compare a large variety of object detection models' accuracy and inference speed on multiple graphics cards. In addition to this large benchmarking attempt, we also reproduce the following models from scratch using PyTorch on the MS COCO 2017 dataset: DETR, RTMDet, ViTDet and YOLOv7. More importantly, we propose a unified training and evaluation pipeline, based on MMDetection's features, to better compare models. Our implementation of DETR and ViTDet could not achieve accuracy or speed performances comparable to what is declared in the original papers. On the other hand, reproduced RTMDet and YOLOv7 could match such performances. Studied papers are also found to be generally lacking for reproducibility purposes. As for MMDetection pretrained models, speed performances are severely reduced with limited computing resources (larger, more accurate models even more so). Moreover, results exhibit a strong trade-off between accuracy and speed, prevailed by anchor-free models - notably RTMDet or YOLOx models. The code used is this paper and all the experiments is available in the repository at https://github.com/Don767/segdet_mlcr2024.
An Open and Comprehensive Pipeline for Unified Object Grounding and Detection
Jan 05, 2024Grounding-DINO is a state-of-the-art open-set detection model that tackles multiple vision tasks including Open-Vocabulary Detection (OVD), Phrase Grounding (PG), and Referring Expression Comprehension (REC). Its effectiveness has led to its widespread adoption as a mainstream architecture for various downstream applications. However, despite its significance, the original Grounding-DINO model lacks comprehensive public technical details due to the unavailability of its training code. To bridge this gap, we present MM-Grounding-DINO, an open-source, comprehensive, and user-friendly baseline, which is built with the MMDetection toolbox. It adopts abundant vision datasets for pre-training and various detection and grounding datasets for fine-tuning. We give a comprehensive analysis of each reported result and detailed settings for reproduction. The extensive experiments on the benchmarks mentioned demonstrate that our MM-Grounding-DINO-Tiny outperforms the Grounding-DINO-Tiny baseline. We release all our models to the research community. Codes and trained models are released at https://github.com/open-mmlab/mmdetection/tree/main/configs/mm_grounding_dino.
Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
Feb 15, 2022
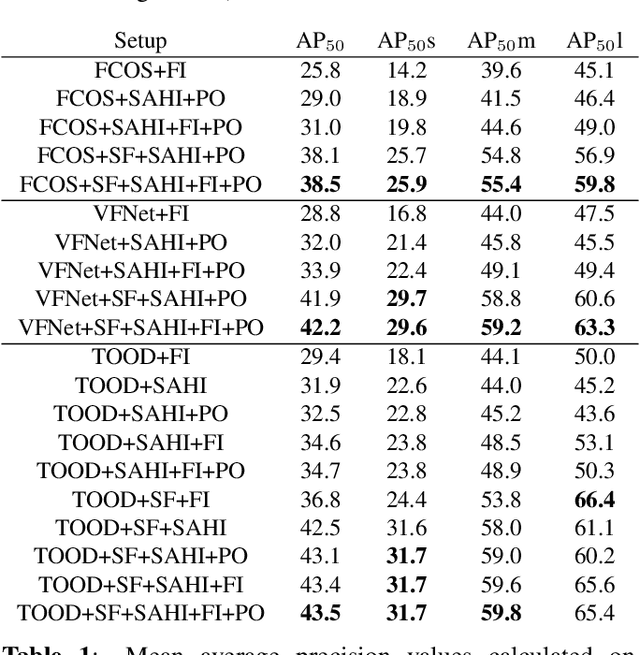
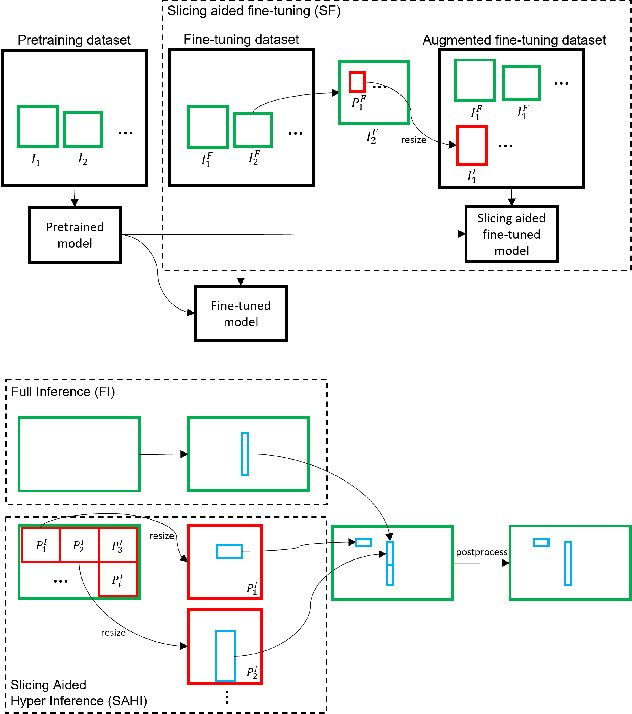
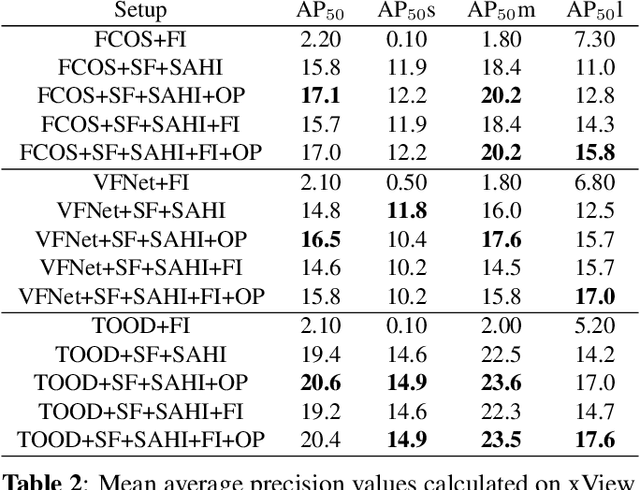
Detection of small objects and objects far away in the scene is a major challenge in surveillance applications. Such objects are represented by small number of pixels in the image and lack sufficient details, making them difficult to detect using conventional detectors. In this work, an open-source framework called Slicing Aided Hyper Inference (SAHI) is proposed that provides a generic slicing aided inference and fine-tuning pipeline for small object detection. The proposed technique is generic in the sense that it can be applied on top of any available object detector without any fine-tuning. Experimental evaluations, using object detection baselines on the Visdrone and xView aerial object detection datasets show that the proposed inference method can increase object detection AP by 6.8%, 5.1% and 5.3% for FCOS, VFNet and TOOD detectors, respectively. Moreover, the detection accuracy can be further increased with a slicing aided fine-tuning, resulting in a cumulative increase of 12.7%, 13.4% and 14.5% AP in the same order. Proposed technique has been integrated with Detectron2, MMDetection and YOLOv5 models and it is publicly available at https://github.com/obss/sahi.git .
hSDB-instrument: Instrument Localization Database for Laparoscopic and Robotic Surgeries
Oct 26, 2021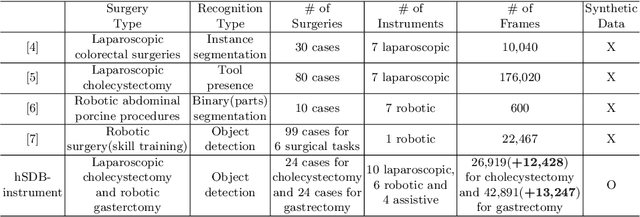
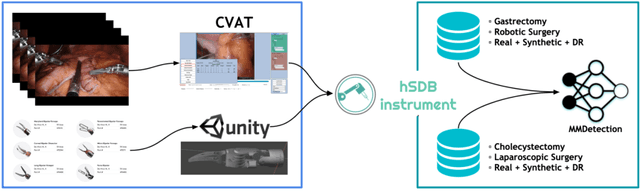
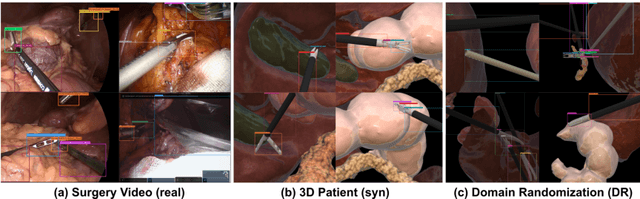
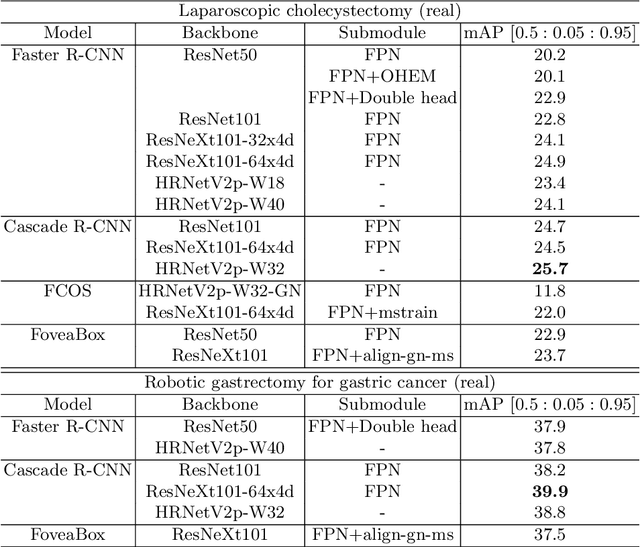
Automated surgical instrument localization is an important technology to understand the surgical process and in order to analyze them to provide meaningful guidance during surgery or surgical index after surgery to the surgeon. We introduce a new dataset that reflects the kinematic characteristics of surgical instruments for automated surgical instrument localization of surgical videos. The hSDB(hutom Surgery DataBase)-instrument dataset consists of instrument localization information from 24 cases of laparoscopic cholecystecomy and 24 cases of robotic gastrectomy. Localization information for all instruments is provided in the form of a bounding box for object detection. To handle class imbalance problem between instruments, synthesized instruments modeled in Unity for 3D models are included as training data. Besides, for 3D instrument data, a polygon annotation is provided to enable instance segmentation of the tool. To reflect the kinematic characteristics of all instruments, they are annotated with head and body parts for laparoscopic instruments, and with head, wrist, and body parts for robotic instruments separately. Annotation data of assistive tools (specimen bag, needle, etc.) that are frequently used for surgery are also included. Moreover, we provide statistical information on the hSDB-instrument dataset and the baseline localization performances of the object detection networks trained by the MMDetection library and resulting analyses.
* https://hsdb-instrument.github.io
Data-Efficient Instance Segmentation with a Single GPU
Oct 08, 2021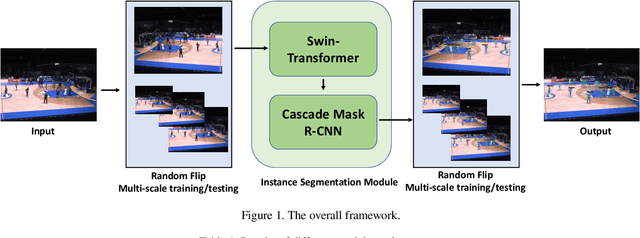

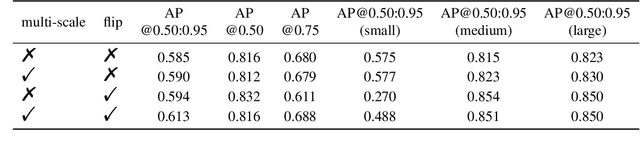
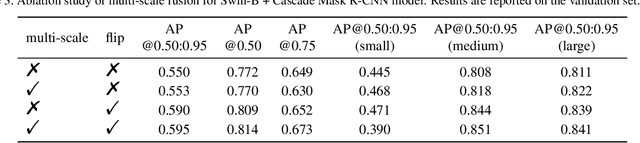
Not everyone is wealthy enough to have hundreds of GPUs or TPUs. Therefore, we've got to find a way out. In this paper, we introduce a data-efficient instance segmentation method we used in the 2021 VIPriors Instance Segmentation Challenge. Our solution is a modified version of Swin Transformer, based on the mmdetection which is a powerful toolbox. To solve the problem of lack of data, we utilize data augmentation including random flip and multiscale training to train our model. During inference, multiscale fusion is used to boost the performance. We only use a single GPU during the whole training and testing stages. In the end, our team named THU_IVG_2018 achieved the result of 0.366 for AP@0.50:0.95 on the test set, which is competitive with other top-ranking methods while only one GPU is used. Besides, our method achieved the AP@0.50:0.95 (medium) of 0.592, which ranks second among all contestants. In the end, our team ranked third among all the contestants, as announced by the organizers.
Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021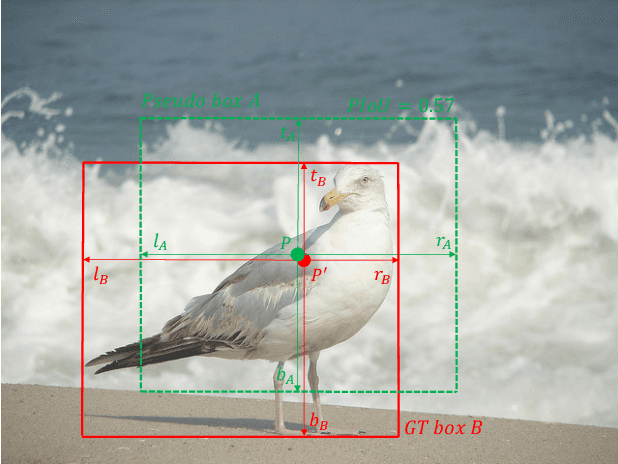
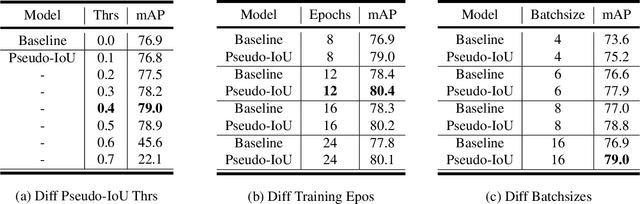
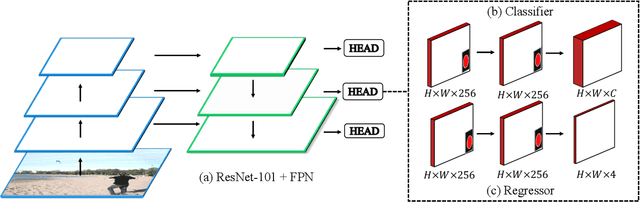
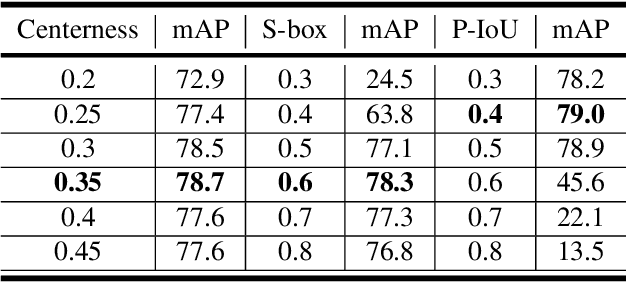
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.
Working with scale: 2nd place solution to Product Detection in Densely Packed Scenes
Jun 14, 2020



This report describes a 2nd place solution of the detection challenge which is held within CVPR 2020 Retail-Vision workshop. Instead of going further considering previous results this work mainly aims to verify previously observed takeaways by re-experimenting. The reliability and reproducibility of the results are reached by incorporating a popular object detection toolbox - MMDetection. In this report, I firstly represent the results received for Faster-RCNN and RetinaNet models, which were taken for comparison in the original work. Then I describe the experiment results with more advanced models. The final section reviews two simple tricks for Faster-RCNN model that were used for my final submission: changing default anchor scale parameter and train-time image tiling. The source code is available at https://github.com/tyomj/product_detection.
MMDetection: Open MMLab Detection Toolbox and Benchmark
Jun 17, 2019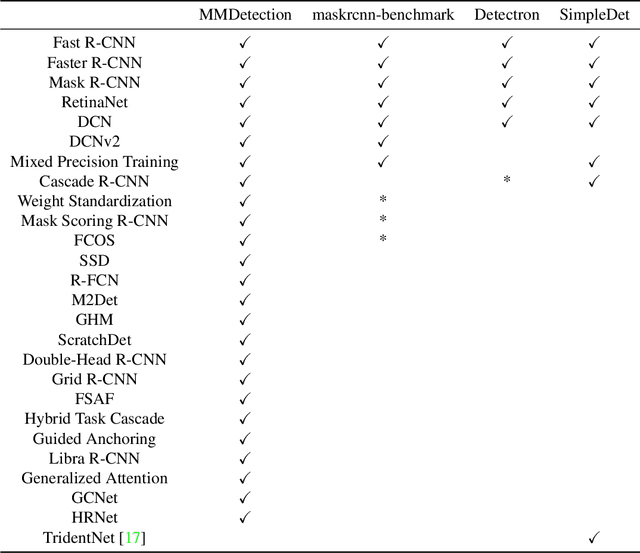
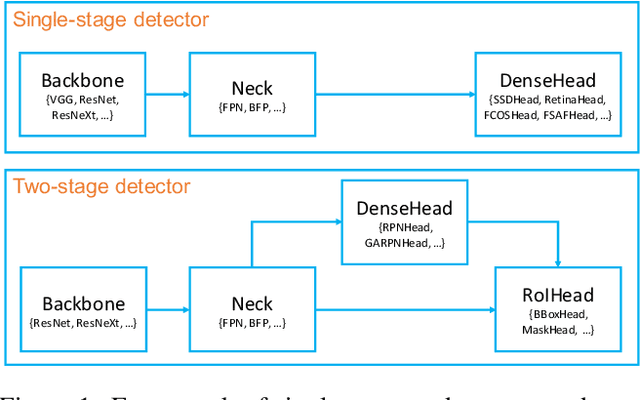
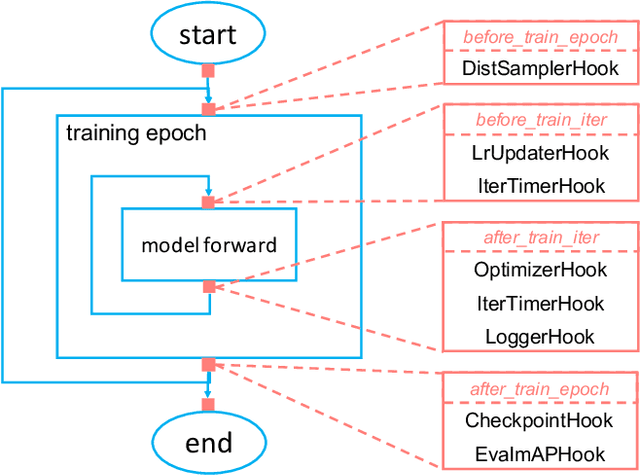
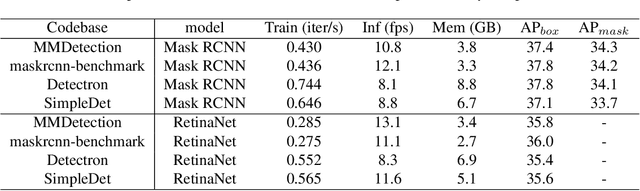
We present MMDetection, an object detection toolbox that contains a rich set of object detection and instance segmentation methods as well as related components and modules. The toolbox started from a codebase of MMDet team who won the detection track of COCO Challenge 2018. It gradually evolves into a unified platform that covers many popular detection methods and contemporary modules. It not only includes training and inference codes, but also provides weights for more than 200 network models. We believe this toolbox is by far the most complete detection toolbox. In this paper, we introduce the various features of this toolbox. In addition, we also conduct a benchmarking study on different methods, components, and their hyper-parameters. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new detectors. Code and models are available at https://github.com/open-mmlab/mmdetection. The project is under active development and we will keep this document updated.