 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Anti Spoofing
Face anti-spoofing is the process of detecting and preventing spoofing attacks on face recognition systems.
Papers and Code
Domain-generalizable Face Anti-Spoofing with Patch-based Multi-tasking and Artifact Pattern Conversion
Apr 10, 2026Face Anti-Spoofing (FAS) algorithms, designed to secure face recognition systems against spoofing, struggle with limited dataset diversity, impairing their ability to handle unseen visual domains and spoofing methods. We introduce the Pattern Conversion Generative Adversarial Network (PCGAN) to enhance domain generalization in FAS. PCGAN effectively disentangles latent vectors for spoof artifacts and facial features, allowing to generate images with diverse artifacts. We further incorporate patch-based and multi-task learning to tackle partial attacks and overfitting issues to facial features. Our extensive experiments validate PCGAN's effectiveness in domain generalization and detecting partial attacks, giving a substantial improvement in facial recognition security.
* The published version is available at DOI: https://doi.org/10.1016/j.patcog.2026.113640
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
Mar 01, 2026Face recognition remains vulnerable to presentation attacks, calling for robust Face Anti-Spoofing (FAS) solutions. Recent MLLM-based FAS methods reformulate the binary classification task as the generation of brief textual descriptions to improve cross-domain generalization. However, their generalizability is still limited, as such descriptions mainly capture intuitive semantic cues (e.g., mask contours) while struggling to perceive fine-grained visual patterns. To address this limitation, we incorporate external visual tools into MLLMs to encourage deeper investigation of subtle spoof clues. Specifically, we propose the Tool-Augmented Reasoning FAS (TAR-FAS) framework, which reformulates the FAS task as a Chain-of-Thought with Visual Tools (CoT-VT) paradigm, allowing MLLMs to begin with intuitive observations and adaptively invoke external visual tools for fine-grained investigation. To this end, we design a tool-augmented data annotation pipeline and construct the ToolFAS-16K dataset, which contains multi-turn tool-use reasoning trajectories. Furthermore, we introduce a tool-aware FAS training pipeline, where Diverse-Tool Group Relative Policy Optimization (DT-GRPO) enables the model to autonomously learn efficient tool use. Extensive experiments under a challenging one-to-eleven cross-domain protocol demonstrate that TAR-FAS achieves SOTA performance while providing fine-grained visual investigation for trustworthy spoof detection.
Virtual camera detection: Catching video injection attacks in remote biometric systems
Dec 11, 2025



Face anti-spoofing (FAS) is a vital component of remote biometric authentication systems based on facial recognition, increasingly used across web-based applications. Among emerging threats, video injection attacks -- facilitated by technologies such as deepfakes and virtual camera software -- pose significant challenges to system integrity. While virtual camera detection (VCD) has shown potential as a countermeasure, existing literature offers limited insight into its practical implementation and evaluation. This study introduces a machine learning-based approach to VCD, with a focus on its design and validation. The model is trained on metadata collected during sessions with authentic users. Empirical results demonstrate its effectiveness in identifying video injection attempts and reducing the risk of malicious users bypassing FAS systems.
Learning Representation and Synergy Invariances: A Povable Framework for Generalized Multimodal Face Anti-Spoofing
Nov 18, 2025



Multimodal Face Anti-Spoofing (FAS) methods, which integrate multiple visual modalities, often suffer even more severe performance degradation than unimodal FAS when deployed in unseen domains. This is mainly due to two overlooked risks that affect cross-domain multimodal generalization. The first is the modal representation invariant risk, i.e., whether representations remain generalizable under domain shift. We theoretically show that the inherent class asymmetry in FAS (diverse spoofs vs. compact reals) enlarges the upper bound of generalization error, and this effect is further amplified in multimodal settings. The second is the modal synergy invariant risk, where models overfit to domain-specific inter-modal correlations. Such spurious synergy cannot generalize to unseen attacks in target domains, leading to performance drops. To solve these issues, we propose a provable framework, namely Multimodal Representation and Synergy Invariance Learning (RiSe). For representation risk, RiSe introduces Asymmetric Invariant Risk Minimization (AsyIRM), which learns an invariant spherical decision boundary in radial space to fit asymmetric distributions, while preserving domain cues in angular space. For synergy risk, RiSe employs Multimodal Synergy Disentanglement (MMSD), a self-supervised task enhancing intrinsic, generalizable modal features via cross-sample mixing and disentanglement. Theoretical analysis and experiments verify RiSe, which achieves state-of-the-art cross-domain performance.
InstructFLIP: Exploring Unified Vision-Language Model for Face Anti-spoofing
Jul 16, 2025Face anti-spoofing (FAS) aims to construct a robust system that can withstand diverse attacks. While recent efforts have concentrated mainly on cross-domain generalization, two significant challenges persist: limited semantic understanding of attack types and training redundancy across domains. We address the first by integrating vision-language models (VLMs) to enhance the perception of visual input. For the second challenge, we employ a meta-domain strategy to learn a unified model that generalizes well across multiple domains. Our proposed InstructFLIP is a novel instruction-tuned framework that leverages VLMs to enhance generalization via textual guidance trained solely on a single domain. At its core, InstructFLIP explicitly decouples instructions into content and style components, where content-based instructions focus on the essential semantics of spoofing, and style-based instructions consider variations related to the environment and camera characteristics. Extensive experiments demonstrate the effectiveness of InstructFLIP by outperforming SOTA models in accuracy and substantially reducing training redundancy across diverse domains in FAS. Project website is available at https://kunkunlin1221.github.io/InstructFLIP.
Paired-Sampling Contrastive Framework for Joint Physical-Digital Face Attack Detection
Aug 20, 2025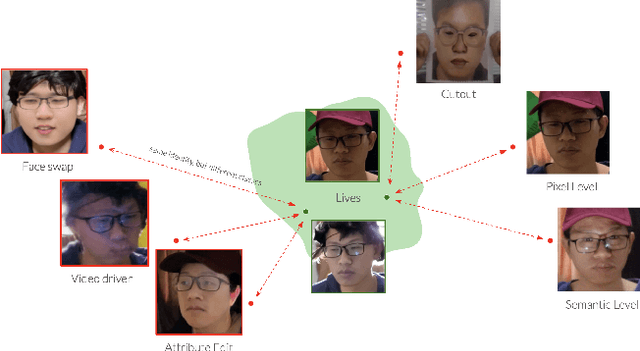
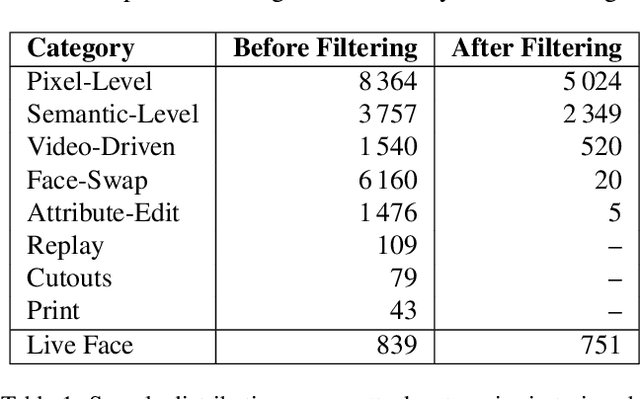

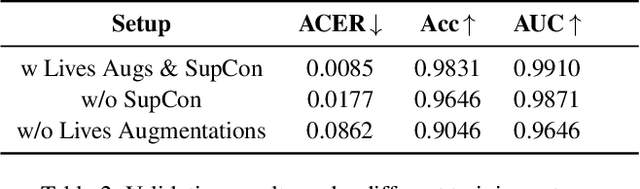
Modern face recognition systems remain vulnerable to spoofing attempts, including both physical presentation attacks and digital forgeries. Traditionally, these two attack vectors have been handled by separate models, each targeting its own artifacts and modalities. However, maintaining distinct detectors increases system complexity and inference latency and leaves systems exposed to combined attack vectors. We propose the Paired-Sampling Contrastive Framework, a unified training approach that leverages automatically matched pairs of genuine and attack selfies to learn modality-agnostic liveness cues. Evaluated on the 6th Face Anti-Spoofing Challenge Unified Physical-Digital Attack Detection benchmark, our method achieves an average classification error rate (ACER) of 2.10 percent, outperforming prior solutions. The framework is lightweight (4.46 GFLOPs) and trains in under one hour, making it practical for real-world deployment. Code and pretrained models are available at https://github.com/xPONYx/iccv2025_deepfake_challenge.
Spectral Masking and Interpolation Attack (SMIA): A Black-box Adversarial Attack against Voice Authentication and Anti-Spoofing Systems
Sep 09, 2025Voice Authentication Systems (VAS) use unique vocal characteristics for verification. They are increasingly integrated into high-security sectors such as banking and healthcare. Despite their improvements using deep learning, they face severe vulnerabilities from sophisticated threats like deepfakes and adversarial attacks. The emergence of realistic voice cloning complicates detection, as systems struggle to distinguish authentic from synthetic audio. While anti-spoofing countermeasures (CMs) exist to mitigate these risks, many rely on static detection models that can be bypassed by novel adversarial methods, leaving a critical security gap. To demonstrate this vulnerability, we propose the Spectral Masking and Interpolation Attack (SMIA), a novel method that strategically manipulates inaudible frequency regions of AI-generated audio. By altering the voice in imperceptible zones to the human ear, SMIA creates adversarial samples that sound authentic while deceiving CMs. We conducted a comprehensive evaluation of our attack against state-of-the-art (SOTA) models across multiple tasks, under simulated real-world conditions. SMIA achieved a strong attack success rate (ASR) of at least 82% against combined VAS/CM systems, at least 97.5% against standalone speaker verification systems, and 100% against countermeasures. These findings conclusively demonstrate that current security postures are insufficient against adaptive adversarial attacks. This work highlights the urgent need for a paradigm shift toward next-generation defenses that employ dynamic, context-aware frameworks capable of evolving with the threat landscape.
Leveraging Intermediate Features of Vision Transformer for Face Anti-Spoofing
May 30, 2025Face recognition systems are designed to be robust against changes in head pose, illumination, and blurring during image capture. If a malicious person presents a face photo of the registered user, they may bypass the authentication process illegally. Such spoofing attacks need to be detected before face recognition. In this paper, we propose a spoofing attack detection method based on Vision Transformer (ViT) to detect minute differences between live and spoofed face images. The proposed method utilizes the intermediate features of ViT, which have a good balance between local and global features that are important for spoofing attack detection, for calculating loss in training and score in inference. The proposed method also introduces two data augmentation methods: face anti-spoofing data augmentation and patch-wise data augmentation, to improve the accuracy of spoofing attack detection. We demonstrate the effectiveness of the proposed method through experiments using the OULU-NPU and SiW datasets.
Denoising and Alignment: Rethinking Domain Generalization for Multimodal Face Anti-Spoofing
May 14, 2025Face Anti-Spoofing (FAS) is essential for the security of facial recognition systems in diverse scenarios such as payment processing and surveillance. Current multimodal FAS methods often struggle with effective generalization, mainly due to modality-specific biases and domain shifts. To address these challenges, we introduce the \textbf{M}ulti\textbf{m}odal \textbf{D}enoising and \textbf{A}lignment (\textbf{MMDA}) framework. By leveraging the zero-shot generalization capability of CLIP, the MMDA framework effectively suppresses noise in multimodal data through denoising and alignment mechanisms, thereby significantly enhancing the generalization performance of cross-modal alignment. The \textbf{M}odality-\textbf{D}omain Joint \textbf{D}ifferential \textbf{A}ttention (\textbf{MD2A}) module in MMDA concurrently mitigates the impacts of domain and modality noise by refining the attention mechanism based on extracted common noise features. Furthermore, the \textbf{R}epresentation \textbf{S}pace \textbf{S}oft (\textbf{RS2}) Alignment strategy utilizes the pre-trained CLIP model to align multi-domain multimodal data into a generalized representation space in a flexible manner, preserving intricate representations and enhancing the model's adaptability to various unseen conditions. We also design a \textbf{U}-shaped \textbf{D}ual \textbf{S}pace \textbf{A}daptation (\textbf{U-DSA}) module to enhance the adaptability of representations while maintaining generalization performance. These improvements not only enhance the framework's generalization capabilities but also boost its ability to represent complex representations. Our experimental results on four benchmark datasets under different evaluation protocols demonstrate that the MMDA framework outperforms existing state-of-the-art methods in terms of cross-domain generalization and multimodal detection accuracy. The code will be released soon.
Learning Unknown Spoof Prompts for Generalized Face Anti-Spoofing Using Only Real Face Images
May 06, 2025



Face anti-spoofing is a critical technology for ensuring the security of face recognition systems. However, its ability to generalize across diverse scenarios remains a significant challenge. In this paper, we attribute the limited generalization ability to two key factors: covariate shift, which arises from external data collection variations, and semantic shift, which results from substantial differences in emerging attack types. To address both challenges, we propose a novel approach for learning unknown spoof prompts, relying solely on real face images from a single source domain. Our method generates textual prompts for real faces and potential unknown spoof attacks by leveraging the general knowledge embedded in vision-language models, thereby enhancing the model's ability to generalize to unseen target domains. Specifically, we introduce a diverse spoof prompt optimization framework to learn effective prompts. This framework constrains unknown spoof prompts within a relaxed prior knowledge space while maximizing their distance from real face images. Moreover, it enforces semantic independence among different spoof prompts to capture a broad range of spoof patterns. Experimental results on nine datasets demonstrate that the learned prompts effectively transfer the knowledge of vision-language models, enabling state-of-the-art generalization ability against diverse unknown attack types across unseen target domains without using any spoof face images.