 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluWorld: A Controlled Benchmark for Hallucination via Reference World Models
May 19, 2026Hallucination remains a central failure mode of large language models, but existing benchmarks operationalize it inconsistently across summarization, question answering, retrieval-augmented generation, and agentic interaction. This fragmentation makes it unclear whether a mitigation that works in one setting reduces hallucinations across contexts. Current benchmarks either require human annotation and fixed references that may be memorized, or rely on observations in settings that are difficult to reproduce. To study root causes, we introduce HalluWorld, an extensible benchmark grounded in an explicit reference-world formulation: a model hallucinates when it produces an observable claim that is false with respect to this world. Building on this view, we construct synthetic and semi-synthetic environments in which the reference world is fully specified, the model's view is controlled, and hallucination labels are generated automatically. HalluWorld spans gridworlds, chess, and realistic terminal tasks, enabling controlled variation of world complexity, observability, temporal change, and source-conflict policy, and disentangling hallucinations into fine-grained error categories. We evaluate frontier and open-weight language models across these settings and find consistent patterns: perceptual hallucination on directly observed information is near-solved for frontier models, while multi-step state tracking and causal forward simulation remain difficult and are not generally solved by extended thinking. In the terminal setting, models also struggle with when to abstain. The uneven profile of failures across probe types and domains suggests that hallucinations arise from distinct failure modes rather than a single capability. Our results suggest that controlled reference worlds offer a scalable and reproducible path toward measuring and reducing hallucinations in modern language models.
To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Apr 01, 2026Retrieval-augmented generation (RAG) improves language model (LM) performance by providing relevant context at test time for knowledge-intensive situations. However, the relationship between parametric knowledge acquired during pretraining and non-parametric knowledge accessed via retrieval remains poorly understood, especially under fixed data budgets. In this work, we systematically study the trade-off between pretraining corpus size and retrieval store size across a wide range of model and data scales. We train OLMo-2-based LMs ranging from 30M to 3B parameters on up to 100B tokens of DCLM data, while varying both pretraining data scale (1-150x the number of parameters) and retrieval store size (1-20x), and evaluate performance across a diverse suite of benchmarks spanning reasoning, scientific QA, and open-domain QA. We find that retrieval consistently improves performance over parametric-only baselines across model scales and introduce a three-dimensional scaling framework that models performance as a function of model size, pretraining tokens, and retrieval corpus size. This scaling manifold enables us to estimate optimal allocations of a fixed data budget between pretraining and retrieval, revealing that the marginal utility of retrieval depends strongly on model scale, task type, and the degree of pretraining saturation. Our results provide a quantitative foundation for understanding when and how retrieval should complement pretraining, offering practical guidance for allocating data resources in the design of scalable language modeling systems.
A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Dec 25, 2025Despite numerous attempts to solve the issue of hallucination since the inception of neural language models, it remains a problem in even frontier large language models today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of language models.
AMSbench: A Comprehensive Benchmark for Evaluating MLLM Capabilities in AMS Circuits
May 30, 2025



Analog/Mixed-Signal (AMS) circuits play a critical role in the integrated circuit (IC) industry. However, automating Analog/Mixed-Signal (AMS) circuit design has remained a longstanding challenge due to its difficulty and complexity. Recent advances in Multi-modal Large Language Models (MLLMs) offer promising potential for supporting AMS circuit analysis and design. However, current research typically evaluates MLLMs on isolated tasks within the domain, lacking a comprehensive benchmark that systematically assesses model capabilities across diverse AMS-related challenges. To address this gap, we introduce AMSbench, a benchmark suite designed to evaluate MLLM performance across critical tasks including circuit schematic perception, circuit analysis, and circuit design. AMSbench comprises approximately 8000 test questions spanning multiple difficulty levels and assesses eight prominent models, encompassing both open-source and proprietary solutions such as Qwen 2.5-VL and Gemini 2.5 Pro. Our evaluation highlights significant limitations in current MLLMs, particularly in complex multi-modal reasoning and sophisticated circuit design tasks. These results underscore the necessity of advancing MLLMs' understanding and effective application of circuit-specific knowledge, thereby narrowing the existing performance gap relative to human expertise and moving toward fully automated AMS circuit design workflows. Our data is released at https://huggingface.co/datasets/wwhhyy/AMSBench
FaceShield: Explainable Face Anti-Spoofing with Multimodal Large Language Models
May 14, 2025



Face anti-spoofing (FAS) is crucial for protecting facial recognition systems from presentation attacks. Previous methods approached this task as a classification problem, lacking interpretability and reasoning behind the predicted results. Recently, multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and decision-making in visual tasks. However, there is currently no universal and comprehensive MLLM and dataset specifically designed for FAS task. To address this gap, we propose FaceShield, a MLLM for FAS, along with the corresponding pre-training and supervised fine-tuning (SFT) datasets, FaceShield-pre10K and FaceShield-sft45K. FaceShield is capable of determining the authenticity of faces, identifying types of spoofing attacks, providing reasoning for its judgments, and detecting attack areas. Specifically, we employ spoof-aware vision perception (SAVP) that incorporates both the original image and auxiliary information based on prior knowledge. We then use an prompt-guided vision token masking (PVTM) strategy to random mask vision tokens, thereby improving the model's generalization ability. We conducted extensive experiments on three benchmark datasets, demonstrating that FaceShield significantly outperforms previous deep learning models and general MLLMs on four FAS tasks, i.e., coarse-grained classification, fine-grained classification, reasoning, and attack localization. Our instruction datasets, protocols, and codes will be released soon.
Automated SAR ADC Sizing Using Analytical Equations
May 14, 2025



Conventional analog and mixed-signal (AMS) circuit designs heavily rely on manual effort, which is time-consuming and labor-intensive. This paper presents a fully automated design methodology for Successive Approximation Register (SAR) Analog-to-Digital Converters (ADCs) from performance specifications to complete transistor sizing. To tackle the high-dimensional sizing problem, we propose a dual optimization scheme. The system-level optimization iteratively partitions the overall requirements and analytically maps them to subcircuit design specifications, while local optimization loops determines the subcircuits' design parameters. The dependency graph-based framework serializes the simulations for verification, knowledge-based calculations, and transistor sizing optimization in topological order, which eliminates the need for human intervention. We demonstrate the effectiveness of the proposed methodology through two case studies with varying performance specifications, achieving high SNDR and low power consumption while meeting all the specified design constraints.
AMSnet 2.0: A Large AMS Database with AI Segmentation for Net Detection
May 14, 2025



Current multimodal large language models (MLLMs) struggle to understand circuit schematics due to their limited recognition capabilities. This could be attributed to the lack of high-quality schematic-netlist training data. Existing work such as AMSnet applies schematic parsing to generate netlists. However, these methods rely on hard-coded heuristics and are difficult to apply to complex or noisy schematics in this paper. We therefore propose a novel net detection mechanism based on segmentation with high robustness. The proposed method also recovers positional information, allowing digital reconstruction of schematics. We then expand AMSnet dataset with schematic images from various sources and create AMSnet 2.0. AMSnet 2.0 contains 2,686 circuits with schematic images, Spectre-formatted netlists, OpenAccess digital schematics, and positional information for circuit components and nets, whereas AMSnet only includes 792 circuits with SPICE netlists but no digital schematics.
AMSnet-KG: A Netlist Dataset for LLM-based AMS Circuit Auto-Design Using Knowledge Graph RAG
Nov 07, 2024



High-performance analog and mixed-signal (AMS) circuits are mainly full-custom designed, which is time-consuming and labor-intensive. A significant portion of the effort is experience-driven, which makes the automation of AMS circuit design a formidable challenge. Large language models (LLMs) have emerged as powerful tools for Electronic Design Automation (EDA) applications, fostering advancements in the automatic design process for large-scale AMS circuits. However, the absence of high-quality datasets has led to issues such as model hallucination, which undermines the robustness of automatically generated circuit designs. To address this issue, this paper introduces AMSnet-KG, a dataset encompassing various AMS circuit schematics and netlists. We construct a knowledge graph with annotations on detailed functional and performance characteristics. Facilitated by AMSnet-KG, we propose an automated AMS circuit generation framework that utilizes the comprehensive knowledge embedded in LLMs. We first formulate a design strategy (e.g., circuit architecture using a number of circuit components) based on required specifications. Next, matched circuit components are retrieved and assembled into a complete topology, and transistor sizing is obtained through Bayesian optimization. Simulation results of the netlist are fed back to the LLM for further topology refinement, ensuring the circuit design specifications are met. We perform case studies of operational amplifier and comparator design to verify the automatic design flow from specifications to netlists with minimal human effort. The dataset used in this paper will be open-sourced upon publishing of this paper.
AMSNet: Netlist Dataset for AMS Circuits
May 15, 2024



Today's analog/mixed-signal (AMS) integrated circuit (IC) designs demand substantial manual intervention. The advent of multimodal large language models (MLLMs) has unveiled significant potential across various fields, suggesting their applicability in streamlining large-scale AMS IC design as well. A bottleneck in employing MLLMs for automatic AMS circuit generation is the absence of a comprehensive dataset delineating the schematic-netlist relationship. We therefore design an automatic technique for converting schematics into netlists, and create dataset AMSNet, encompassing transistor-level schematics and corresponding SPICE format netlists. With a growing size, AMSNet can significantly facilitate exploration of MLLM applications in AMS circuit design. We have made an initial set of netlists public, and will make both our netlist generation tool and the full dataset available upon publishing of this paper.
LW-GCN: A Lightweight FPGA-based Graph Convolutional Network Accelerator
Nov 04, 2021
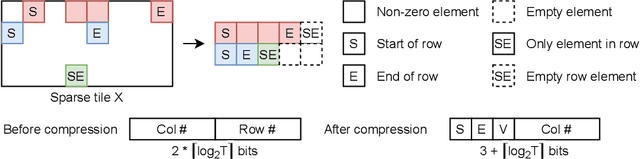

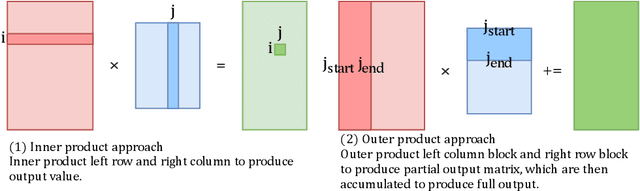
Graph convolutional networks (GCNs) have been introduced to effectively process non-euclidean graph data. However, GCNs incur large amounts of irregularity in computation and memory access, which prevents efficient use of traditional neural network accelerators. Moreover, existing dedicated GCN accelerators demand high memory volumes and are difficult to implement onto resource limited edge devices. In this work, we propose LW-GCN, a lightweight FPGA-based accelerator with a software-hardware co-designed process to tackle irregularity in computation and memory access in GCN inference. LW-GCN decomposes the main GCN operations into sparse-dense matrix multiplication (SDMM) and dense matrix multiplication (DMM). We propose a novel compression format to balance workload across PEs and prevent data hazards. Moreover, we apply data quantization and workload tiling, and map both SDMM and DMM of GCN inference onto a uniform architecture on resource limited hardware. Evaluation on GCN and GraphSAGE are performed on Xilinx Kintex-7 FPGA with three popular datasets. Compared to existing CPU, GPU, and state-of-the-art FPGA-based accelerator, LW-GCN reduces latency by up to 60x, 12x and 1.7x and increases power efficiency by up to 912x., 511x and 3.87x, respectively. Furthermore, compared with NVIDIA's latest edge GPU Jetson Xavier NX, LW-GCN achieves speedup and energy savings of 32x and 84x, respectively.