 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Performance Profiling of Large Language Models
May 28, 2026Large language models (LLMs) frequently achieve impressive scores on standardized benchmarks, yet accuracy alone offers a limited view of their capabilities. Evaluating open-source LLMs through leaderboards faces persistent issues like data contamination, narrow task scope, and weak alignment with real-world reliability. Benchmark-based evaluations such as MMLU PRO, BBH, or IFEval primarily capture \textit{what} a model outputs on fixed test sets, not \textit{how} it processes information, calibrates uncertainty, or structures internal knowledge. In this article, we advocate for a shift from benchmark-centric evaluation toward a complementary, \textit{state-centered intrinsic assessment} of LLMs. To this end, we introduce \textbf{Latent Performance Profiling (LPP)} -- a framework that derives task-agnostic diagnostics from hidden activations and output distributions. LPP defines a set of scalar metrics on a model's latent representations and dynamics, revealing scale-independent traits that enable interpretable comparisons and uncover hidden vulnerabilities. Unlike static accuracy scores, LPP provides stable, architecture-sensitive signatures across models of similar size. With extensive empirical analyses across eight LLMs, spanning a size range of 0.5B-14B, we demonstrate that models with similar benchmark scores can exhibit contrasting latent profiles, such as differences in entropy or adaptability. Guided by these insights, we design synthetic probes for uncertainty and symbolic reasoning that align with intrinsic metrics while decoupling from leaderboard bias. We recommend that reporting LPP alongside benchmarks provides a deeper, interpretable understanding of model behavior, enabling more reliable model selection, safety assessment, and evaluation beyond surface-level accuracy.
Unbiased Model Prediction Without Using Protected Attribute Information
Mar 31, 2026The problem of bias persists in the deep learning community as models continue to provide disparate performance across different demographic subgroups. Therefore, several algorithms have been proposed to improve the fairness of deep models. However, a majority of these algorithms utilize the protected attribute information for bias mitigation, which severely limits their application in real-world scenarios. To address this concern, we have proposed a novel algorithm, termed as \textbf{Non-Protected Attribute-based Debiasing (NPAD)} algorithm for bias mitigation, that does not require the protected attribute information. The proposed NPAD algorithm utilizes the auxiliary information provided by the non-protected attributes to optimize the model for bias mitigation. Further, two different loss functions, \textbf{Debiasing via Attribute Cluster Loss (DACL)} and \textbf{Filter Redundancy Loss (FRL)} have been proposed to optimize the model for fairness goals. Multiple experiments are performed on the LFWA and CelebA datasets for facial attribute prediction, and a significant reduction in bias across different gender and age subgroups is observed.
Right Looks, Wrong Reasons: Compositional Fidelity in Text-to-Image Generation
Nov 13, 2025The architectural blueprint of today's leading text-to-image models contains a fundamental flaw: an inability to handle logical composition. This survey investigates this breakdown across three core primitives-negation, counting, and spatial relations. Our analysis reveals a dramatic performance collapse: models that are accurate on single primitives fail precipitously when these are combined, exposing severe interference. We trace this failure to three key factors. First, training data show a near-total absence of explicit negations. Second, continuous attention architectures are fundamentally unsuitable for discrete logic. Third, evaluation metrics reward visual plausibility over constraint satisfaction. By analyzing recent benchmarks and methods, we show that current solutions and simple scaling cannot bridge this gap. Achieving genuine compositionality, we conclude, will require fundamental advances in representation and reasoning rather than incremental adjustments to existing architectures.
TAIGen: Training-Free Adversarial Image Generation via Diffusion Models
Aug 20, 2025Adversarial attacks from generative models often produce low-quality images and require substantial computational resources. Diffusion models, though capable of high-quality generation, typically need hundreds of sampling steps for adversarial generation. This paper introduces TAIGen, a training-free black-box method for efficient adversarial image generation. TAIGen produces adversarial examples using only 3-20 sampling steps from unconditional diffusion models. Our key finding is that perturbations injected during the mixing step interval achieve comparable attack effectiveness without processing all timesteps. We develop a selective RGB channel strategy that applies attention maps to the red channel while using GradCAM-guided perturbations on green and blue channels. This design preserves image structure while maximizing misclassification in target models. TAIGen maintains visual quality with PSNR above 30 dB across all tested datasets. On ImageNet with VGGNet as source, TAIGen achieves 70.6% success against ResNet, 80.8% against MNASNet, and 97.8% against ShuffleNet. The method generates adversarial examples 10x faster than existing diffusion-based attacks. Our method achieves the lowest robust accuracy, indicating it is the most impactful attack as the defense mechanism is least successful in purifying the images generated by TAIGen.
Quantum-Inspired Audio Unlearning: Towards Privacy-Preserving Voice Biometrics
Jul 29, 2025The widespread adoption of voice-enabled authentication and audio biometric systems have significantly increased privacy vulnerabilities associated with sensitive speech data. Compliance with privacy regulations such as GDPR's right to be forgotten and India's DPDP Act necessitates targeted and efficient erasure of individual-specific voice signatures from already-trained biometric models. Existing unlearning methods designed for visual data inadequately handle the sequential, temporal, and high-dimensional nature of audio signals, leading to ineffective or incomplete speaker and accent erasure. To address this, we introduce QPAudioEraser, a quantum-inspired audio unlearning framework. Our our-phase approach involves: (1) weight initialization using destructive interference to nullify target features, (2) superposition-based label transformations that obscure class identity, (3) an uncertainty-maximizing quantum loss function, and (4) entanglement-inspired mixing of correlated weights to retain model knowledge. Comprehensive evaluations with ResNet18, ViT, and CNN architectures across AudioMNIST, Speech Commands, LibriSpeech, and Speech Accent Archive datasets validate QPAudioEraser's superior performance. The framework achieves complete erasure of target data (0% Forget Accuracy) while incurring minimal impact on model utility, with a performance degradation on retained data as low as 0.05%. QPAudioEraser consistently surpasses conventional baselines across single-class, multi-class, sequential, and accent-level erasure scenarios, establishing the proposed approach as a robust privacy-preserving solution.
Harmonizing Geometry and Uncertainty: Diffusion with Hyperspheres
Jun 12, 2025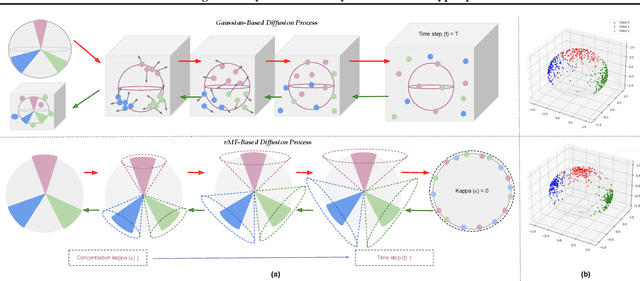
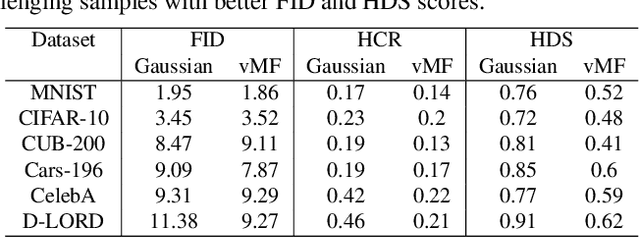


Do contemporary diffusion models preserve the class geometry of hyperspherical data? Standard diffusion models rely on isotropic Gaussian noise in the forward process, inherently favoring Euclidean spaces. However, many real-world problems involve non-Euclidean distributions, such as hyperspherical manifolds, where class-specific patterns are governed by angular geometry within hypercones. When modeled in Euclidean space, these angular subtleties are lost, leading to suboptimal generative performance. To address this limitation, we introduce HyperSphereDiff to align hyperspherical structures with directional noise, preserving class geometry and effectively capturing angular uncertainty. We demonstrate both theoretically and empirically that this approach aligns the generative process with the intrinsic geometry of hyperspherical data, resulting in more accurate and geometry-aware generative models. We evaluate our framework on four object datasets and two face datasets, showing that incorporating angular uncertainty better preserves the underlying hyperspherical manifold. Resources are available at: {https://github.com/IAB-IITJ/Harmonizing-Geometry-and-Uncertainty-Diffusion-with-Hyperspheres/}
Multimodal Zero-Shot Framework for Deepfake Hate Speech Detection in Low-Resource Languages
Jun 10, 2025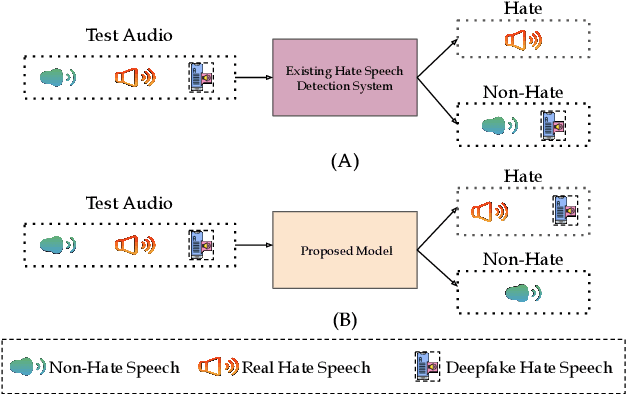
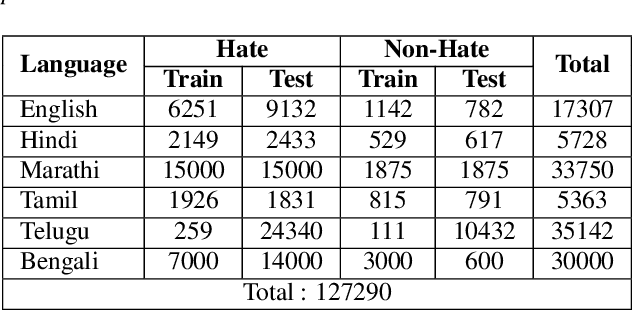
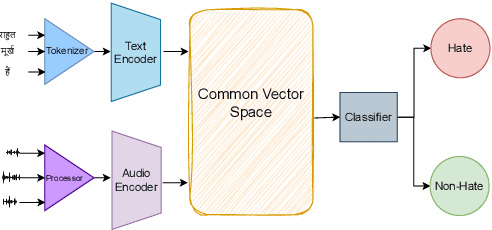
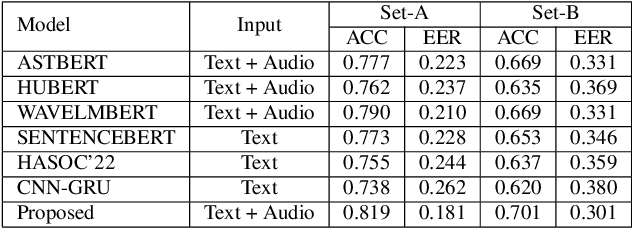
This paper introduces a novel multimodal framework for hate speech detection in deepfake audio, excelling even in zero-shot scenarios. Unlike previous approaches, our method uses contrastive learning to jointly align audio and text representations across languages. We present the first benchmark dataset with 127,290 paired text and synthesized speech samples in six languages: English and five low-resource Indian languages (Hindi, Bengali, Marathi, Tamil, Telugu). Our model learns a shared semantic embedding space, enabling robust cross-lingual and cross-modal classification. Experiments on two multilingual test sets show our approach outperforms baselines, achieving accuracies of 0.819 and 0.701, and generalizes well to unseen languages. This demonstrates the advantage of combining modalities for hate speech detection in synthetic media, especially in low-resource settings where unimodal models falter. The Dataset is available at https://www.iab-rubric.org/resources.
SynHate: Detecting Hate Speech in Synthetic Deepfake Audio
Jun 07, 2025The rise of deepfake audio and hate speech, powered by advanced text-to-speech, threatens online safety. We present SynHate, the first multilingual dataset for detecting hate speech in synthetic audio, spanning 37 languages. SynHate uses a novel four-class scheme: Real-normal, Real-hate, Fake-normal, and Fake-hate. Built from MuTox and ADIMA datasets, it captures diverse hate speech patterns globally and in India. We evaluate five leading self-supervised models (Whisper-small/medium, XLS-R, AST, mHuBERT), finding notable performance differences by language, with Whisper-small performing best overall. Cross-dataset generalization remains a challenge. By releasing SynHate and baseline code, we aim to advance robust, culturally sensitive, and multilingual solutions against synthetic hate speech. The dataset is available at https://www.iab-rubric.org/resources.
Can Quantized Audio Language Models Perform Zero-Shot Spoofing Detection?
Jun 07, 2025Quantization is essential for deploying large audio language models (LALMs) efficiently in resource-constrained environments. However, its impact on complex tasks, such as zero-shot audio spoofing detection, remains underexplored. This study evaluates the zero-shot capabilities of five LALMs, GAMA, LTU-AS, MERaLiON, Qwen-Audio, and SALMONN, across three distinct datasets: ASVspoof2019, In-the-Wild, and WaveFake, and investigates their robustness to quantization (FP32, FP16, INT8). Despite high initial spoof detection accuracy, our analysis demonstrates severe predictive biases toward spoof classification across all models, rendering their practical performance equivalent to random classification. Interestingly, quantization to FP16 precision resulted in negligible performance degradation compared to FP32, effectively halving memory and computational requirements without materially impacting accuracy. However, INT8 quantization intensified model biases, significantly degrading balanced accuracy. These findings highlight critical architectural limitations and emphasize FP16 quantization as an optimal trade-off, providing guidelines for practical deployment and future model refinement.
LitMAS: A Lightweight and Generalized Multi-Modal Anti-Spoofing Framework for Biometric Security
Jun 07, 2025Biometric authentication systems are increasingly being deployed in critical applications, but they remain susceptible to spoofing. Since most of the research efforts focus on modality-specific anti-spoofing techniques, building a unified, resource-efficient solution across multiple biometric modalities remains a challenge. To address this, we propose LitMAS, a $\textbf{Li}$gh$\textbf{t}$ weight and generalizable $\textbf{M}$ulti-modal $\textbf{A}$nti-$\textbf{S}$poofing framework designed to detect spoofing attacks in speech, face, iris, and fingerprint-based biometric systems. At the core of LitMAS is a Modality-Aligned Concentration Loss, which enhances inter-class separability while preserving cross-modal consistency and enabling robust spoof detection across diverse biometric traits. With just 6M parameters, LitMAS surpasses state-of-the-art methods by $1.36\%$ in average EER across seven datasets, demonstrating high efficiency, strong generalizability, and suitability for edge deployment. Code and trained models are available at https://github.com/IAB-IITJ/LitMAS.