 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Jun 17, 2026Graphical user interface (GUI) grounding requires vision-language models (VLMs) to identify small target elements in high-resolution screenshots and predict precise screen coordinates. On-policy self-distillation (OPSD) is a promising post-training approach for this coordinate-sensitive task, since it provides dense token-level teacher signals beyond hard coordinate labels. However, naive OPSD is not well suited to GUI grounding: OPSD evaluates the teacher on student-generated prefixes, the quality of coordinate-token teacher signals can degrade when the prefix has already deviated from the target coordinate, leading to unreliable teacher signal. To mitigate this, We propose quality-aware self-distillation for VLM-based GUI grounding, which improves coordinate-token teacher-signal quality through soft correctness-aware gating and teacher-probability scaling. The soft correctness-aware gate checks whether the teacher's current coordinate-token prediction can still be completed into the ground-truth box under the student-generated prefix. If not, the corresponding teacher signal is down-weighted. Teacher-probability scaling then uses the teacher's confidence as a lightweight factor to further calibrate the strength of the gated supervision. A key empirical finding is that neither component alone improves overall performance, whereas combining them consistently improves performance. This suggests that the two mechanisms play complementary roles: correctness-aware gating suppresses unreliable coordinate-token supervision, while teacher-probability scaling calibrates the strength of the remaining signals. Experiments across six GUI grounding benchmarks show that our method consistently improves the base model and outperforms strong baselines.
DyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
Mar 17, 2026While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct policy updates, but this often incurs high computational costs and causes mode collapse via overfitting. We argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy. To this end, we propose Dynamic Jensen-Shannon Replay (DyJR), a simple yet effective regularization framework using a dynamic reference distribution from recent trajectories. DyJR introduces two innovations: (1) A Time-Sensitive Dynamic Buffer that uses FIFO and adaptive sizing to retain only temporally proximal samples, synchronizing with model evolution; and (2) Jensen-Shannon Divergence Regularization, which replaces direct gradient updates with a distributional constraint to prevent diversity collapse. Experiments on mathematical reasoning and Text-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficiency comparable to the original GRPO. Furthermore, from the perspective of Rank-$k$ token probability evolution, we show that DyJR enhances diversity and mitigates over-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the training dynamics.
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Apr 10, 2025Recently, slow-thinking systems like GPT-o1 and DeepSeek-R1 have demonstrated great potential in solving challenging problems through explicit reflection. They significantly outperform the best fast-thinking models, such as GPT-4o, on various math and science benchmarks. However, their multimodal reasoning capabilities remain on par with fast-thinking models. For instance, GPT-o1's performance on benchmarks like MathVista, MathVerse, and MathVision is similar to fast-thinking models. In this paper, we aim to enhance the slow-thinking capabilities of vision-language models using reinforcement learning (without relying on distillation) to advance the state of the art. First, we adapt the GRPO algorithm with a novel technique called Selective Sample Replay (SSR) to address the vanishing advantages problem. While this approach yields strong performance, the resulting RL-trained models exhibit limited self-reflection or self-verification. To further encourage slow-thinking, we introduce Forced Rethinking, which appends a textual rethinking trigger to the end of initial rollouts in RL training, explicitly enforcing a self-reflection reasoning step. By combining these two techniques, our model, VL-Rethinker, advances state-of-the-art scores on MathVista, MathVerse, and MathVision to achieve 80.3%, 61.8%, and 43.9% respectively. VL-Rethinker also achieves open-source SoTA on multi-disciplinary benchmarks such as MMMU-Pro, EMMA, and MEGA-Bench, narrowing the gap with GPT-o1.
A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning
Aug 15, 2019

Detecting scene text of arbitrary shapes has been a challenging task over the past years. In this paper, we propose a novel segmentation-based text detector, namely SAST, which employs a context attended multi-task learning framework based on a Fully Convolutional Network (FCN) to learn various geometric properties for the reconstruction of polygonal representation of text regions. Taking sequential characteristics of text into consideration, a Context Attention Block is introduced to capture long-range dependencies of pixel information to obtain a more reliable segmentation. In post-processing, a Point-to-Quad assignment method is proposed to cluster pixels into text instances by integrating both high-level object knowledge and low-level pixel information in a single shot. Moreover, the polygonal representation of arbitrarily-shaped text can be extracted with the proposed geometric properties much more effectively. Experiments on several benchmarks, including ICDAR2015, ICDAR2017-MLT, SCUT-CTW1500, and Total-Text, demonstrate that SAST achieves better or comparable performance in terms of accuracy. Furthermore, the proposed algorithm runs at 27.63 FPS on SCUT-CTW1500 with a Hmean of 81.0% on a single NVIDIA Titan Xp graphics card, surpassing most of the existing segmentation-based methods.
* 9 pages, 6 figures, 7 tables, To appear in ACM Multimedia 2019
Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
Apr 13, 2019
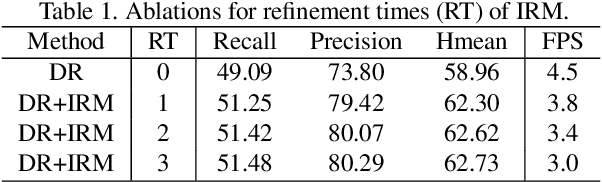
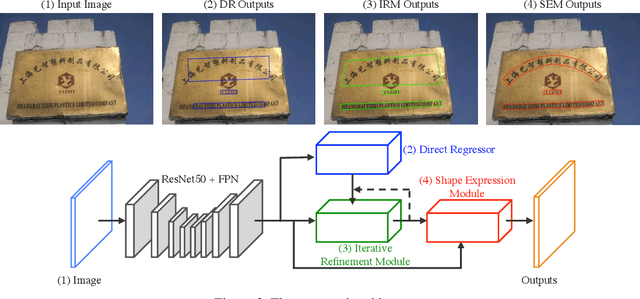

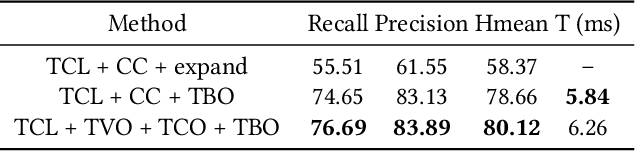
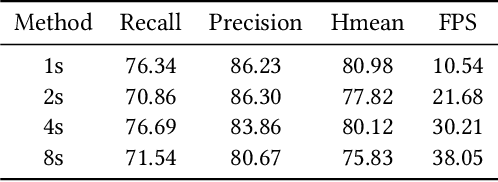
Previous scene text detection methods have progressed substantially over the past years. However, limited by the receptive field of CNNs and the simple representations like rectangle bounding box or quadrangle adopted to describe text, previous methods may fall short when dealing with more challenging text instances, such as extremely long text and arbitrarily shaped text. To address these two problems, we present a novel text detector namely LOMO, which localizes the text progressively for multiple times (or in other word, LOok More than Once). LOMO consists of a direct regressor (DR), an iterative refinement module (IRM) and a shape expression module (SEM). At first, text proposals in the form of quadrangle are generated by DR branch. Next, IRM progressively perceives the entire long text by iterative refinement based on the extracted feature blocks of preliminary proposals. Finally, a SEM is introduced to reconstruct more precise representation of irregular text by considering the geometry properties of text instance, including text region, text center line and border offsets. The state-of-the-art results on several public benchmarks including ICDAR2017-RCTW, SCUT-CTW1500, Total-Text, ICDAR2015 and ICDAR17-MLT confirm the striking robustness and effectiveness of LOMO.
TextNet: Irregular Text Reading from Images with an End-to-End Trainable Network
Dec 24, 2018

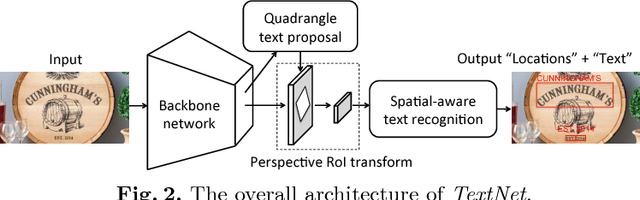
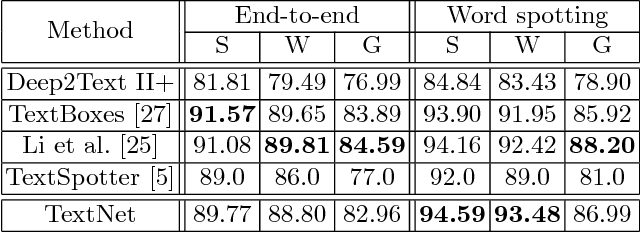
Reading text from images remains challenging due to multi-orientation, perspective distortion and especially the curved nature of irregular text. Most of existing approaches attempt to solve the problem in two or multiple stages, which is considered to be the bottleneck to optimize the overall performance. To address this issue, we propose an end-to-end trainable network architecture, named TextNet, which is able to simultaneously localize and recognize irregular text from images. Specifically, we develop a scale-aware attention mechanism to learn multi-scale image features as a backbone network, sharing fully convolutional features and computation for localization and recognition. In text detection branch, we directly generate text proposals in quadrangles, covering oriented, perspective and curved text regions. To preserve text features for recognition, we introduce a perspective RoI transform layer, which can align quadrangle proposals into small feature maps. Furthermore, in order to extract effective features for recognition, we propose to encode the aligned RoI features by RNN into context information, combining spatial attention mechanism to generate text sequences. This overall pipeline is capable of handling both regular and irregular cases. Finally, text localization and recognition tasks can be jointly trained in an end-to-end fashion with designed multi-task loss. Experiments on standard benchmarks show that the proposed TextNet can achieve state-of-the-art performance, and outperform existing approaches on irregular datasets by a large margin.