 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


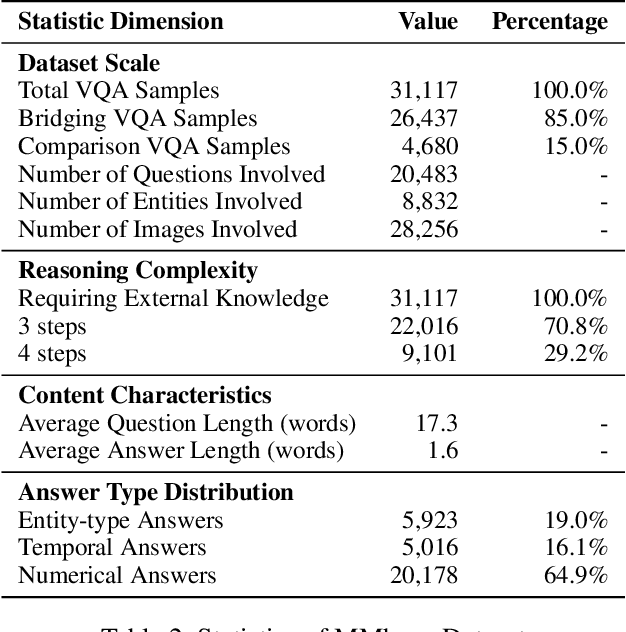
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
From Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
Dec 12, 2025



This paper introduces the concept of Microscopic Spatial Intelligence (MiSI), the capability to perceive and reason about the spatial relationships of invisible microscopic entities, which is fundamental to scientific discovery. To assess the potential of Vision-Language Models (VLMs) in this domain, we propose a systematic benchmark framework MiSI-Bench. This framework features over 163,000 question-answer pairs and 587,000 images derived from approximately 4,000 molecular structures, covering nine complementary tasks that evaluate abilities ranging from elementary spatial transformations to complex relational identifications. Experimental results reveal that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model demonstrates substantial potential, even surpassing humans in spatial transformation tasks, while its poor performance in scientifically-grounded tasks like hydrogen bond recognition underscores the necessity of integrating explicit domain knowledge for progress toward scientific AGI. The datasets are available at https://huggingface.co/datasets/zongzhao/MiSI-bench.
Are Large Language Models Chronically Online Surfers? A Dataset for Chinese Internet Meme Explanation
Oct 01, 2025Large language models (LLMs) are trained on vast amounts of text from the Internet, but do they truly understand the viral content that rapidly spreads online -- commonly known as memes? In this paper, we introduce CHIME, a dataset for CHinese Internet Meme Explanation. The dataset comprises popular phrase-based memes from the Chinese Internet, annotated with detailed information on their meaning, origin, example sentences, types, etc. To evaluate whether LLMs understand these memes, we designed two tasks. In the first task, we assessed the models' ability to explain a given meme, identify its origin, and generate appropriate example sentences. The results show that while LLMs can explain the meanings of some memes, their performance declines significantly for culturally and linguistically nuanced meme types. Additionally, they consistently struggle to provide accurate origins for the memes. In the second task, we created a set of multiple-choice questions (MCQs) requiring LLMs to select the most appropriate meme to fill in a blank within a contextual sentence. While the evaluated models were able to provide correct answers, their performance remains noticeably below human levels. We have made CHIME public and hope it will facilitate future research on computational meme understanding.
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 26, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
STAR-R1: Spacial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
iMOVE: Instance-Motion-Aware Video Understanding
Feb 18, 2025



Enhancing the fine-grained instance spatiotemporal motion perception capabilities of Video Large Language Models is crucial for improving their temporal and general video understanding. However, current models struggle to perceive detailed and complex instance motions. To address these challenges, we have made improvements from both data and model perspectives. In terms of data, we have meticulously curated iMOVE-IT, the first large-scale instance-motion-aware video instruction-tuning dataset. This dataset is enriched with comprehensive instance motion annotations and spatiotemporal mutual-supervision tasks, providing extensive training for the model's instance-motion-awareness. Building on this foundation, we introduce iMOVE, an instance-motion-aware video foundation model that utilizes Event-aware Spatiotemporal Efficient Modeling to retain informative instance spatiotemporal motion details while maintaining computational efficiency. It also incorporates Relative Spatiotemporal Position Tokens to ensure awareness of instance spatiotemporal positions. Evaluations indicate that iMOVE excels not only in video temporal understanding and general video understanding but also demonstrates significant advantages in long-term video understanding.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.
E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding
Sep 26, 2024



Recent advances in Video Large Language Models (Video-LLMs) have demonstrated their great potential in general-purpose video understanding. To verify the significance of these models, a number of benchmarks have been proposed to diagnose their capabilities in different scenarios. However, existing benchmarks merely evaluate models through video-level question-answering, lacking fine-grained event-level assessment and task diversity. To fill this gap, we introduce E.T. Bench (Event-Level & Time-Sensitive Video Understanding Benchmark), a large-scale and high-quality benchmark for open-ended event-level video understanding. Categorized within a 3-level task taxonomy, E.T. Bench encompasses 7.3K samples under 12 tasks with 7K videos (251.4h total length) under 8 domains, providing comprehensive evaluations. We extensively evaluated 8 Image-LLMs and 12 Video-LLMs on our benchmark, and the results reveal that state-of-the-art models for coarse-level (video-level) understanding struggle to solve our fine-grained tasks, e.g., grounding event-of-interests within videos, largely due to the short video context length, improper time representations, and lack of multi-event training data. Focusing on these issues, we further propose a strong baseline model, E.T. Chat, together with an instruction-tuning dataset E.T. Instruct 164K tailored for fine-grained event-level understanding. Our simple but effective solution demonstrates superior performance in multiple scenarios.
How to Make Cross Encoder a Good Teacher for Efficient Image-Text Retrieval?
Jul 10, 2024



Dominant dual-encoder models enable efficient image-text retrieval but suffer from limited accuracy while the cross-encoder models offer higher accuracy at the expense of efficiency. Distilling cross-modality matching knowledge from cross-encoder to dual-encoder provides a natural approach to harness their strengths. Thus we investigate the following valuable question: how to make cross-encoder a good teacher for dual-encoder? Our findings are threefold:(1) Cross-modal similarity score distribution of cross-encoder is more concentrated while the result of dual-encoder is nearly normal making vanilla logit distillation less effective. However ranking distillation remains practical as it is not affected by the score distribution.(2) Only the relative order between hard negatives conveys valid knowledge while the order information between easy negatives has little significance.(3) Maintaining the coordination between distillation loss and dual-encoder training loss is beneficial for knowledge transfer. Based on these findings we propose a novel Contrastive Partial Ranking Distillation (CPRD) method which implements the objective of mimicking relative order between hard negative samples with contrastive learning. This approach coordinates with the training of the dual-encoder effectively transferring valid knowledge from the cross-encoder to the dual-encoder. Extensive experiments on image-text retrieval and ranking tasks show that our method surpasses other distillation methods and significantly improves the accuracy of dual-encoder.