 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Open Vocabulary: Multimodal Prompting for Object Detection in Remote Sensing Images
Feb 02, 2026Open-vocabulary object detection in remote sensing commonly relies on text-only prompting to specify target categories, implicitly assuming that inference-time category queries can be reliably grounded through pretraining-induced text-visual alignment. In practice, this assumption often breaks down in remote sensing scenarios due to task- and application-specific category semantics, resulting in unstable category specification under open-vocabulary settings. To address this limitation, we propose RS-MPOD, a multimodal open-vocabulary detection framework that reformulates category specification beyond text-only prompting by incorporating instance-grounded visual prompts, textual prompts, and their multimodal integration. RS-MPOD introduces a visual prompt encoder to extract appearance-based category cues from exemplar instances, enabling text-free category specification, and a multimodal fusion module to integrate visual and textual information when both modalities are available. Extensive experiments on standard, cross-dataset, and fine-grained remote sensing benchmarks show that visual prompting yields more reliable category specification under semantic ambiguity and distribution shifts, while multimodal prompting provides a flexible alternative that remains competitive when textual semantics are well aligned.
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025



Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025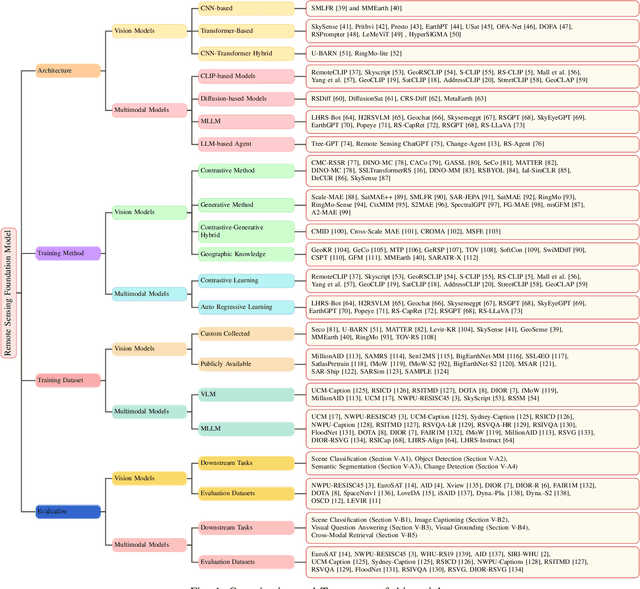
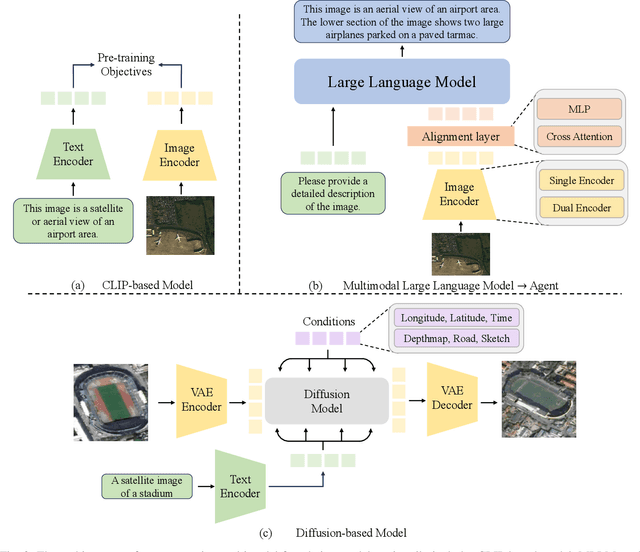

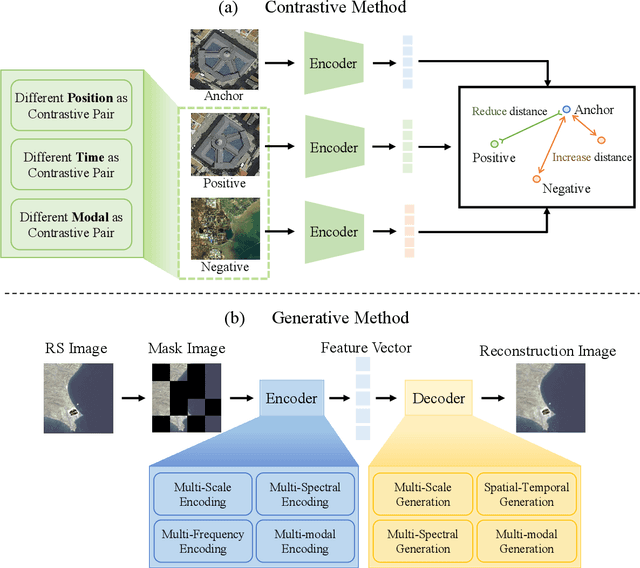
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
OpenRSD: Towards Open-prompts for Object Detection in Remote Sensing Images
Mar 08, 2025



Remote sensing object detection has made significant progress, but most studies still focus on closed-set detection, limiting generalization across diverse datasets. Open-vocabulary object detection (OVD) provides a solution by leveraging multimodal associations between text prompts and visual features. However, existing OVD methods for remote sensing (RS) images are constrained by small-scale datasets and fail to address the unique challenges of remote sensing interpretation, include oriented object detection and the need for both high precision and real-time performance in diverse scenarios. To tackle these challenges, we propose OpenRSD, a universal open-prompt RS object detection framework. OpenRSD supports multimodal prompts and integrates multi-task detection heads to balance accuracy and real-time requirements. Additionally, we design a multi-stage training pipeline to enhance the generalization of model. Evaluated on seven public datasets, OpenRSD demonstrates superior performance in oriented and horizontal bounding box detection, with real-time inference capabilities suitable for large-scale RS image analysis. Compared to YOLO-World, OpenRSD exhibits an 8.7\% higher average precision and achieves an inference speed of 20.8 FPS. Codes and models will be released.
Training on Fake Labels: Mitigating Label Leakage in Split Learning via Secure Dimension Transformation
Oct 11, 2024



Two-party split learning has emerged as a popular paradigm for vertical federated learning. To preserve the privacy of the label owner, split learning utilizes a split model, which only requires the exchange of intermediate representations (IRs) based on the inputs and gradients for each IR between two parties during the learning process. However, split learning has recently been proven to survive label inference attacks. Though several defense methods could be adopted, they either have limited defensive performance or significantly negatively impact the original mission. In this paper, we propose a novel two-party split learning method to defend against existing label inference attacks while maintaining the high utility of the learned models. Specifically, we first craft a dimension transformation module, SecDT, which could achieve bidirectional mapping between original labels and increased K-class labels to mitigate label leakage from the directional perspective. Then, a gradient normalization algorithm is designed to remove the magnitude divergence of gradients from different classes. We propose a softmax-normalized Gaussian noise to mitigate privacy leakage and make our K unknowable to adversaries. We conducted experiments on real-world datasets, including two binary-classification datasets (Avazu and Criteo) and three multi-classification datasets (MNIST, FashionMNIST, CIFAR-10); we also considered current attack schemes, including direction, norm, spectral, and model completion attacks. The detailed experiments demonstrate our proposed method's effectiveness and superiority over existing approaches. For instance, on the Avazu dataset, the attack AUC of evaluated four prominent attacks could be reduced by 0.4532+-0.0127.
PS-TTL: Prototype-based Soft-labels and Test-Time Learning for Few-shot Object Detection
Aug 11, 2024In recent years, Few-Shot Object Detection (FSOD) has gained widespread attention and made significant progress due to its ability to build models with a good generalization power using extremely limited annotated data. The fine-tuning based paradigm is currently dominating this field, where detectors are initially pre-trained on base classes with sufficient samples and then fine-tuned on novel ones with few samples, but the scarcity of labeled samples of novel classes greatly interferes precisely fitting their data distribution, thus hampering the performance. To address this issue, we propose a new framework for FSOD, namely Prototype-based Soft-labels and Test-Time Learning (PS-TTL). Specifically, we design a Test-Time Learning (TTL) module that employs a mean-teacher network for self-training to discover novel instances from test data, allowing detectors to learn better representations and classifiers for novel classes. Furthermore, we notice that even though relatively low-confidence pseudo-labels exhibit classification confusion, they still tend to recall foreground. We thus develop a Prototype-based Soft-labels (PS) strategy through assessing similarities between low-confidence pseudo-labels and category prototypes as soft-labels to unleash their potential, which substantially mitigates the constraints posed by few-shot samples. Extensive experiments on both the VOC and COCO benchmarks show that PS-TTL achieves the state-of-the-art, highlighting its effectiveness. The code and model are available at https://github.com/gaoyingjay/PS-TTL.
MutDet: Mutually Optimizing Pre-training for Remote Sensing Object Detection
Jul 13, 2024



Detection pre-training methods for the DETR series detector have been extensively studied in natural scenes, e.g., DETReg. However, the detection pre-training remains unexplored in remote sensing scenes. In existing pre-training methods, alignment between object embeddings extracted from a pre-trained backbone and detector features is significant. However, due to differences in feature extraction methods, a pronounced feature discrepancy still exists and hinders the pre-training performance. The remote sensing images with complex environments and more densely distributed objects exacerbate the discrepancy. In this work, we propose a novel Mutually optimizing pre-training framework for remote sensing object Detection, dubbed as MutDet. In MutDet, we propose a systemic solution against this challenge. Firstly, we propose a mutual enhancement module, which fuses the object embeddings and detector features bidirectionally in the last encoder layer, enhancing their information interaction.Secondly, contrastive alignment loss is employed to guide this alignment process softly and simultaneously enhances detector features' discriminativity. Finally, we design an auxiliary siamese head to mitigate the task gap arising from the introduction of enhancement module. Comprehensive experiments on various settings show new state-of-the-art transfer performance. The improvement is particularly pronounced when data quantity is limited. When using 10% of the DIOR-R data, MutDet improves DetReg by 6.1% in AP50. Codes and models are available at: https://github.com/floatingstarZ/MutDet.
BeamVQ: Aligning Space-Time Forecasting Model via Self-training on Physics-aware Metrics
May 27, 2024



Data-driven deep learning has emerged as the new paradigm to model complex physical space-time systems. These data-driven methods learn patterns by optimizing statistical metrics and tend to overlook the adherence to physical laws, unlike traditional model-driven numerical methods. Thus, they often generate predictions that are not physically realistic. On the other hand, by sampling a large amount of high quality predictions from a data-driven model, some predictions will be more physically plausible than the others and closer to what will happen in the future. Based on this observation, we propose \emph{Beam search by Vector Quantization} (BeamVQ) to enhance the physical alignment of data-driven space-time forecasting models. The key of BeamVQ is to train model on self-generated samples filtered with physics-aware metrics. To be flexibly support different backbone architectures, BeamVQ leverages a code bank to transform any encoder-decoder model to the continuous state space into discrete codes. Afterwards, it iteratively employs beam search to sample high-quality sequences, retains those with the highest physics-aware scores, and trains model on the new dataset. Comprehensive experiments show that BeamVQ not only gave an average statistical skill score boost for more than 32% for ten backbones on five datasets, but also significantly enhances physics-aware metrics.
YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images
Apr 09, 2024



Detecting objects from aerial images poses significant challenges due to the following factors: 1) Aerial images typically have very large sizes, generally with millions or even hundreds of millions of pixels, while computational resources are limited. 2) Small object size leads to insufficient information for effective detection. 3) Non-uniform object distribution leads to computational resource wastage. To address these issues, we propose YOLC (You Only Look Clusters), an efficient and effective framework that builds on an anchor-free object detector, CenterNet. To overcome the challenges posed by large-scale images and non-uniform object distribution, we introduce a Local Scale Module (LSM) that adaptively searches cluster regions for zooming in for accurate detection. Additionally, we modify the regression loss using Gaussian Wasserstein distance (GWD) to obtain high-quality bounding boxes. Deformable convolution and refinement methods are employed in the detection head to enhance the detection of small objects. We perform extensive experiments on two aerial image datasets, including Visdrone2019 and UAVDT, to demonstrate the effectiveness and superiority of our proposed approach.
A General and Efficient Federated Split Learning with Pre-trained Image Transformers for Heterogeneous Data
Mar 24, 2024Federated Split Learning (FSL) is a promising distributed learning paradigm in practice, which gathers the strengths of both Federated Learning (FL) and Split Learning (SL) paradigms, to ensure model privacy while diminishing the resource overhead of each client, especially on large transformer models in a resource-constrained environment, e.g., Internet of Things (IoT). However, almost all works merely investigate the performance with simple neural network models in FSL. Despite the minor efforts focusing on incorporating Vision Transformers (ViT) as model architectures, they train ViT from scratch, thereby leading to enormous training overhead in each device with limited resources. Therefore, in this paper, we harness Pre-trained Image Transformers (PITs) as the initial model, coined FES-PIT, to accelerate the training process and improve model robustness. Furthermore, we propose FES-PTZO to hinder the gradient inversion attack, especially having the capability compatible with black-box scenarios, where the gradient information is unavailable. Concretely, FES-PTZO approximates the server gradient by utilizing a zeroth-order (ZO) optimization, which replaces the backward propagation with just one forward process. Empirically, we are the first to provide a systematic evaluation of FSL methods with PITs in real-world datasets, different partial device participations, and heterogeneous data splits. Our experiments verify the effectiveness of our algorithms.