 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Money, Fake Models: Deceptive Model Claims in Shadow APIs
Mar 05, 2026Access to frontier large language models (LLMs), such as GPT-5 and Gemini-2.5, is often hindered by high pricing, payment barriers, and regional restrictions. These limitations drive the proliferation of $\textit{shadow APIs}$, third-party services that claim to provide access to official model services without regional limitations via indirect access. Despite their widespread use, it remains unclear whether shadow APIs deliver outputs consistent with those of the official APIs, raising concerns about the reliability of downstream applications and the validity of research findings that depend on them. In this paper, we present the first systematic audit between official LLM APIs and corresponding shadow APIs. We first identify 17 shadow APIs that have been utilized in 187 academic papers, with the most popular one reaching 5,966 citations and 58,639 GitHub stars by December 6, 2025. Through multidimensional auditing of three representative shadow APIs across utility, safety, and model verification, we uncover both indirect and direct evidence of deception practices in shadow APIs. Specifically, we reveal performance divergence reaching up to $47.21\%$, significant unpredictability in safety behaviors, and identity verification failures in $45.83\%$ of fingerprint tests. These deceptive practices critically undermine the reproducibility and validity of scientific research, harm the interests of shadow API users, and damage the reputation of official model providers.
Sparse Models, Sparse Safety: Unsafe Routes in Mixture-of-Experts LLMs
Feb 09, 2026By introducing routers to selectively activate experts in Transformer layers, the mixture-of-experts (MoE) architecture significantly reduces computational costs in large language models (LLMs) while maintaining competitive performance, especially for models with massive parameters. However, prior work has largely focused on utility and efficiency, leaving the safety risks associated with this sparse architecture underexplored. In this work, we show that the safety of MoE LLMs is as sparse as their architecture by discovering unsafe routes: routing configurations that, once activated, convert safe outputs into harmful ones. Specifically, we first introduce the Router Safety importance score (RoSais) to quantify the safety criticality of each layer's router. Manipulation of only the high-RoSais router(s) can flip the default route into an unsafe one. For instance, on JailbreakBench, masking 5 routers in DeepSeek-V2-Lite increases attack success rate (ASR) by over 4$\times$ to 0.79, highlighting an inherent risk that router manipulation may naturally occur in MoE LLMs. We further propose a Fine-grained token-layer-wise Stochastic Optimization framework to discover more concrete Unsafe Routes (F-SOUR), which explicitly considers the sequentiality and dynamics of input tokens. Across four representative MoE LLM families, F-SOUR achieves an average ASR of 0.90 and 0.98 on JailbreakBench and AdvBench, respectively. Finally, we outline defensive perspectives, including safety-aware route disabling and router training, as promising directions to safeguard MoE LLMs. We hope our work can inform future red-teaming and safeguarding of MoE LLMs. Our code is provided in https://github.com/TrustAIRLab/UnsafeMoE.
Training on Fake Labels: Mitigating Label Leakage in Split Learning via Secure Dimension Transformation
Oct 11, 2024



Two-party split learning has emerged as a popular paradigm for vertical federated learning. To preserve the privacy of the label owner, split learning utilizes a split model, which only requires the exchange of intermediate representations (IRs) based on the inputs and gradients for each IR between two parties during the learning process. However, split learning has recently been proven to survive label inference attacks. Though several defense methods could be adopted, they either have limited defensive performance or significantly negatively impact the original mission. In this paper, we propose a novel two-party split learning method to defend against existing label inference attacks while maintaining the high utility of the learned models. Specifically, we first craft a dimension transformation module, SecDT, which could achieve bidirectional mapping between original labels and increased K-class labels to mitigate label leakage from the directional perspective. Then, a gradient normalization algorithm is designed to remove the magnitude divergence of gradients from different classes. We propose a softmax-normalized Gaussian noise to mitigate privacy leakage and make our K unknowable to adversaries. We conducted experiments on real-world datasets, including two binary-classification datasets (Avazu and Criteo) and three multi-classification datasets (MNIST, FashionMNIST, CIFAR-10); we also considered current attack schemes, including direction, norm, spectral, and model completion attacks. The detailed experiments demonstrate our proposed method's effectiveness and superiority over existing approaches. For instance, on the Avazu dataset, the attack AUC of evaluated four prominent attacks could be reduced by 0.4532+-0.0127.
Making Recommender Systems More Knowledgeable: A Framework to Incorporate Side Information
Jun 02, 2024



Session-based recommender systems typically focus on using only the triplet (user_id, timestamp, item_id) to make predictions of users' next actions. In this paper, we aim to utilize side information to help recommender systems catch patterns and signals otherwise undetectable. Specifically, we propose a general framework for incorporating item-specific side information into the recommender system to enhance its performance without much modification on the original model architecture. Experimental results on several models and datasets prove that with side information, our recommender system outperforms state-of-the-art models by a considerable margin and converges much faster. Additionally, we propose a new type of loss to regularize the attention mechanism used by recommender systems and evaluate its influence on model performance. Furthermore, through analysis, we put forward a few insights on potential further improvements.
EnvPool: A Highly Parallel Reinforcement Learning Environment Execution Engine
Jun 21, 2022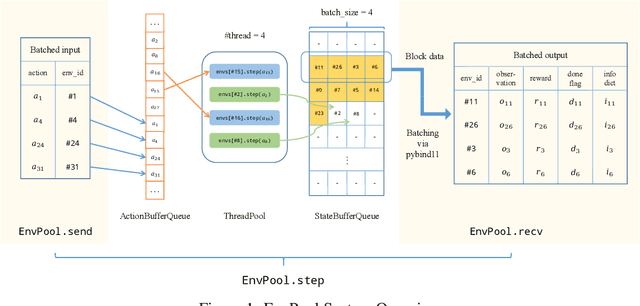
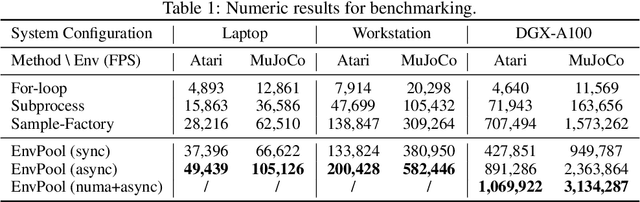
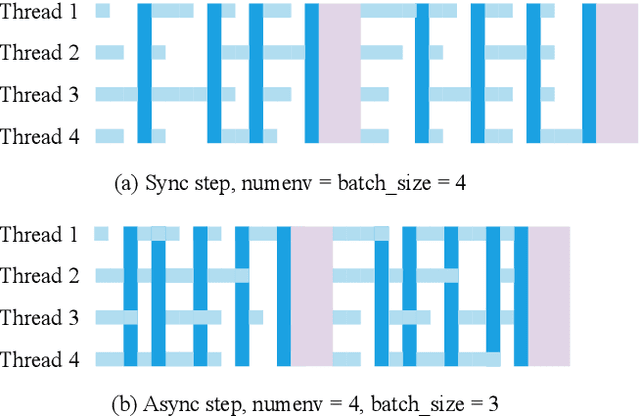
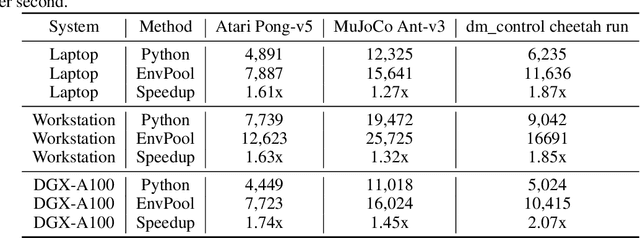
There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others aim to improve the system's overall throughput. In this paper, we try to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop, and a modest workstation, to a high-end machine like NVIDIA DGX-A100. On a high-end machine, EnvPool achieves 1 million frames per second for the environment execution on Atari environments and 3 million frames per second on MuJoCo environments. When running on a laptop, the speed of EnvPool is 2.8 times of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has the great potential to become the de facto RL environment execution engine. Example runs show that it takes only 5 minutes to train Atari Pong and MuJoCo Ant, both on a laptop. EnvPool has already been open-sourced at https://github.com/sail-sg/envpool.
The Application of Active Query K-Means in Text Classification
Jul 16, 2021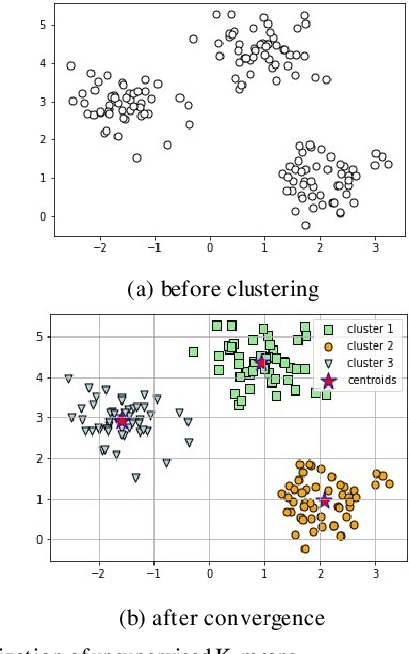
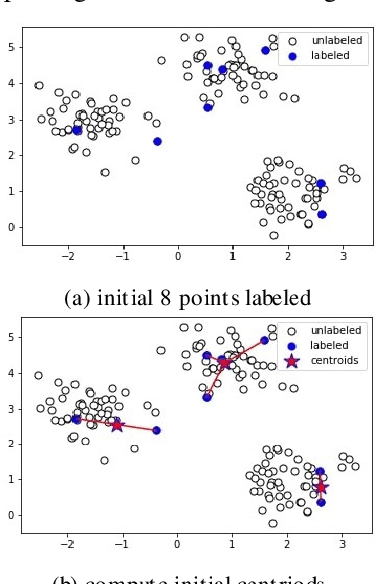
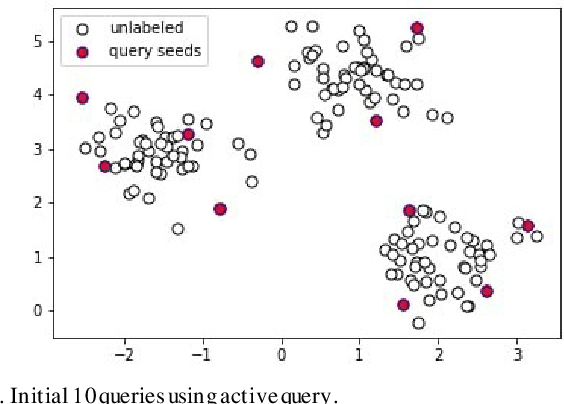

Active learning is a state-of-art machine learning approach to deal with an abundance of unlabeled data. In the field of Natural Language Processing, typically it is costly and time-consuming to have all the data annotated. This inefficiency inspires out our application of active learning in text classification. Traditional unsupervised k-means clustering is first modified into a semi-supervised version in this research. Then, a novel attempt is applied to further extend the algorithm into active learning scenario with Penalized Min-Max-selection, so as to make limited queries that yield more stable initial centroids. This method utilizes both the interactive query results from users and the underlying distance representation. After tested on a Chinese news dataset, it shows a consistent increase in accuracy while lowering the cost in training.
* 6 pages, 3 algorithms, 4 tables, 8 figures For source code and questions, please email Yukun Jiang at jy2363@nyu.edu Reply would follow shortly