 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
RN-Net: Reservoir Nodes-Enabled Neuromorphic Vision Sensing Network
Mar 21, 2023Event-based cameras are inspired by the sparse and asynchronous spike representation of the biological visual system. However, processing the even data requires either using expensive feature descriptors to transform spikes into frames, or using spiking neural networks that are difficult to train. In this work, we propose a neural network architecture based on simple convolution layers integrated with dynamic temporal encoding reservoirs with low hardware and training costs. The Reservoir Nodes-enabled neuromorphic vision sensing Network (RN-Net) allows the network to efficiently process asynchronous temporal features, and achieves the highest accuracy of 99.2% for DVS128 Gesture reported to date, and one of the highest accuracy of 67.5% for DVS Lip dataset at a much smaller network size. By leveraging the internal dynamics of memristors, asynchronous temporal feature encoding can be implemented at very low hardware cost without preprocessing or dedicated memory and arithmetic units. The use of simple DNN blocks and backpropagation based training rules further reduces its implementation cost. Code will be publicly available.
NoiseCAM: Explainable AI for the Boundary Between Noise and Adversarial Attacks
Mar 09, 2023



Deep Learning (DL) and Deep Neural Networks (DNNs) are widely used in various domains. However, adversarial attacks can easily mislead a neural network and lead to wrong decisions. Defense mechanisms are highly preferred in safety-critical applications. In this paper, firstly, we use the gradient class activation map (GradCAM) to analyze the behavior deviation of the VGG-16 network when its inputs are mixed with adversarial perturbation or Gaussian noise. In particular, our method can locate vulnerable layers that are sensitive to adversarial perturbation and Gaussian noise. We also show that the behavior deviation of vulnerable layers can be used to detect adversarial examples. Secondly, we propose a novel NoiseCAM algorithm that integrates information from globally and pixel-level weighted class activation maps. Our algorithm is susceptible to adversarial perturbations and will not respond to Gaussian random noise mixed in the inputs. Third, we compare detecting adversarial examples using both behavior deviation and NoiseCAM, and we show that NoiseCAM outperforms behavior deviation modeling in its overall performance. Our work could provide a useful tool to defend against certain adversarial attacks on deep neural networks.
Object-centric Learning with Cyclic Walks between Parts and Whole
Feb 16, 2023Learning object-centric representations from complex natural environments enables both humans and machines with reasoning abilities from low-level perceptual features. To capture compositional entities of the scene, we proposed cyclic walks between perceptual features extracted from CNN or transformers and object entities. First, a slot-attention module interfaces with these perceptual features and produces a finite set of slot representations. These slots can bind to any object entities in the scene via inter-slot competitions for attention. Next, we establish entity-feature correspondence with cyclic walks along high transition probability based on pairwise similarity between perceptual features (aka "parts") and slot-binded object representations (aka "whole"). The whole is greater than its parts and the parts constitute the whole. The part-whole interactions form cycle consistencies, as supervisory signals, to train the slot-attention module. We empirically demonstrate that the networks trained with our cyclic walks can extract object-centric representations on seven image datasets in three unsupervised learning tasks. In contrast to object-centric models attached with a decoder for image or feature reconstructions, our cyclic walks provide strong supervision signals, avoiding computation overheads and enhancing memory efficiency.
HumanGen: Generating Human Radiance Fields with Explicit Priors
Dec 10, 2022



Recent years have witnessed the tremendous progress of 3D GANs for generating view-consistent radiance fields with photo-realism. Yet, high-quality generation of human radiance fields remains challenging, partially due to the limited human-related priors adopted in existing methods. We present HumanGen, a novel 3D human generation scheme with detailed geometry and $\text{360}^{\circ}$ realistic free-view rendering. It explicitly marries the 3D human generation with various priors from the 2D generator and 3D reconstructor of humans through the design of "anchor image". We introduce a hybrid feature representation using the anchor image to bridge the latent space of HumanGen with the existing 2D generator. We then adopt a pronged design to disentangle the generation of geometry and appearance. With the aid of the anchor image, we adapt a 3D reconstructor for fine-grained details synthesis and propose a two-stage blending scheme to boost appearance generation. Extensive experiments demonstrate our effectiveness for state-of-the-art 3D human generation regarding geometry details, texture quality, and free-view performance. Notably, HumanGen can also incorporate various off-the-shelf 2D latent editing methods, seamlessly lifting them into 3D.
Zebra: Deeply Integrating System-Level Provenance Search and Tracking for Efficient Attack Investigation
Nov 10, 2022



System auditing has emerged as a key approach for monitoring system call events and investigating sophisticated attacks. Based on the collected audit logs, research has proposed to search for attack patterns or track the causal dependencies of system events to reveal the attack sequence. However, existing approaches either cannot reveal long-range attack sequences or suffer from the dependency explosion problem due to a lack of focus on attack-relevant parts, and thus are insufficient for investigating complex attacks. To bridge the gap, we propose Zebra, a system that synergistically integrates attack pattern search and causal dependency tracking for efficient attack investigation. With Zebra, security analysts can alternate between search and tracking to reveal the entire attack sequence in a progressive, user-guided manner, while mitigating the dependency explosion problem by prioritizing the attack-relevant parts. To enable this, Zebra provides (1) an expressive and concise domain-specific language, Tstl, for performing various types of search and tracking analyses, and (2) an optimized language execution engine for efficient execution over a big amount of auditing data. Evaluations on a broad set of attack cases demonstrate the effectiveness of Zebra in facilitating a timely attack investigation.
Spectral Representation Learning for Conditional Moment Models
Oct 29, 2022



Many problems in causal inference and economics can be formulated in the framework of conditional moment models, which characterize the target function through a collection of conditional moment restrictions. For nonparametric conditional moment models, efficient estimation has always relied on preimposed conditions on various measures of ill-posedness of the hypothesis space, which are hard to validate when flexible models are used. In this work, we address this issue by proposing a procedure that automatically learns representations with controlled measures of ill-posedness. Our method approximates a linear representation defined by the spectral decomposition of a conditional expectation operator, which can be used for kernelized estimators and is known to facilitate minimax optimal estimation in certain settings. We show this representation can be efficiently estimated from data, and establish L2 consistency for the resulting estimator. We evaluate the proposed method on proximal causal inference tasks, exhibiting promising performance on high-dimensional, semi-synthetic data.
Application of Deep Q Learning with Stimulation Results for Elevator Optimization
Sep 30, 2022
This paper presents a methodology for combining programming and mathematics to optimize elevator wait times. Based on simulated user data generated according to the canonical three-peak model of elevator traffic, we first develop a naive model from an intuitive understanding of the logic behind elevators. We take into consideration a general array of features including capacity, acceleration, and maximum wait time thresholds to adequately model realistic circumstances. Using the same evaluation framework, we proceed to develop a Deep Q Learning model in an attempt to match the hard-coded naive approach for elevator control. Throughout the majority of the paper, we work under a Markov Decision Process (MDP) schema, but later explore how the assumption fails to characterize the highly stochastic overall Elevator Group Control System (EGCS).
Modeling Perceptual Loudness of Piano Tone: Theory and Applications
Sep 21, 2022
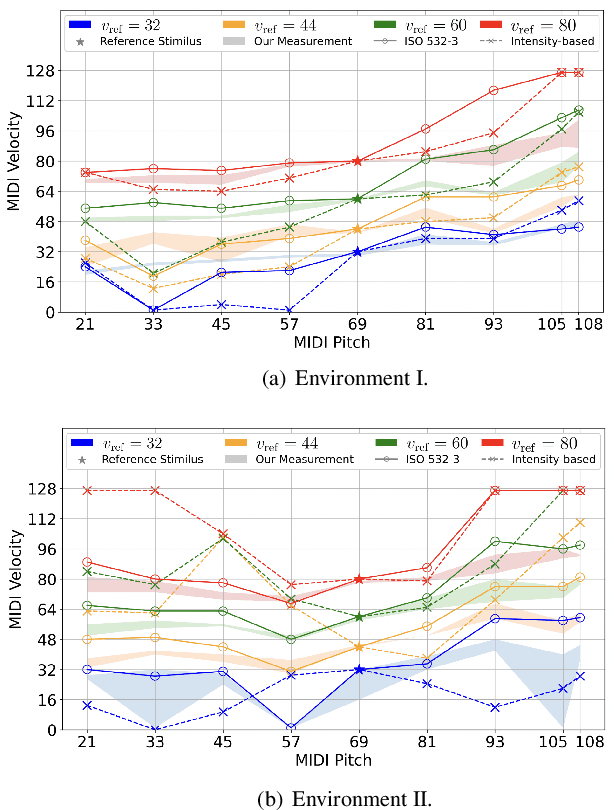
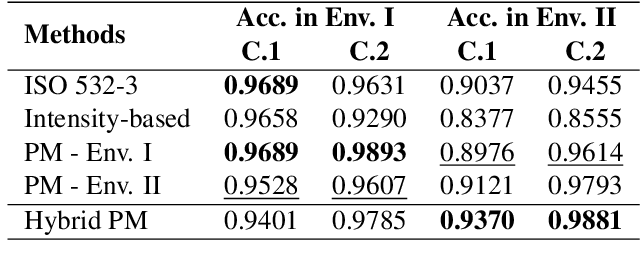
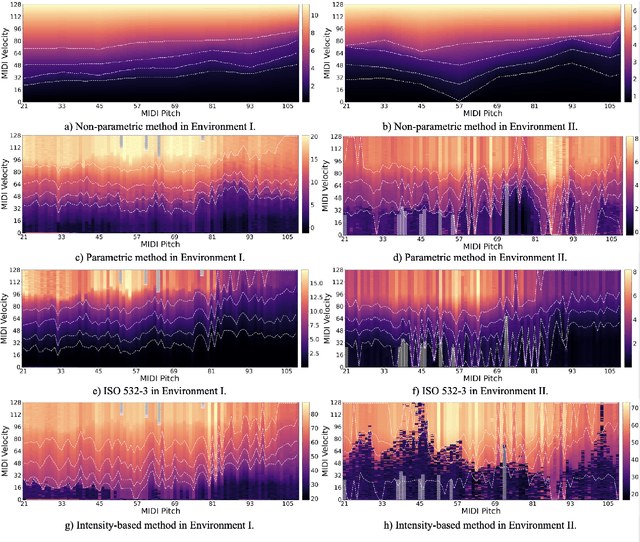
The relationship between perceptual loudness and physical attributes of sound is an important subject in both computer music and psychoacoustics. Early studies of "equal-loudness contour" can trace back to the 1920s and the measured loudness with respect to intensity and frequency has been revised many times since then. However, most studies merely focus on synthesized sound, and the induced theories on natural tones with complex timbre have rarely been justified. To this end, we investigate both theory and applications of natural-tone loudness perception in this paper via modeling piano tone. The theory part contains: 1) an accurate measurement of piano-tone equal-loudness contour of pitches, and 2) a machine-learning model capable of inferring loudness purely based on spectral features trained on human subject measurements. As for the application, we apply our theory to piano control transfer, in which we adjust the MIDI velocities on two different player pianos (in different acoustic environments) to achieve the same perceptual effect. Experiments show that both our theoretical loudness modeling and the corresponding performance control transfer algorithm significantly outperform their baselines.
Generative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects
Sep 09, 2022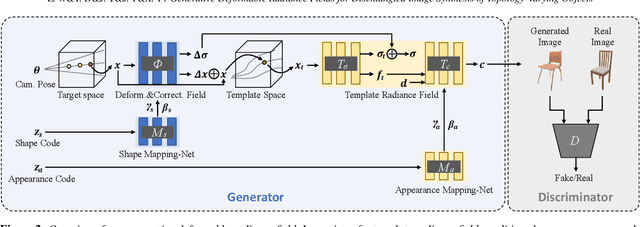
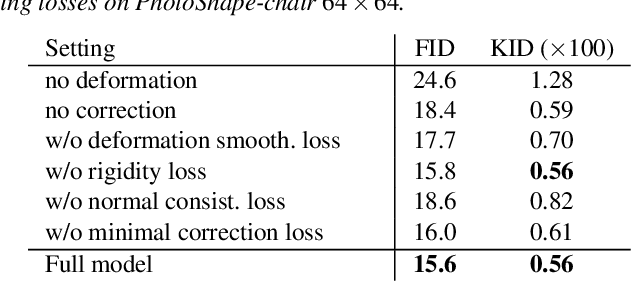
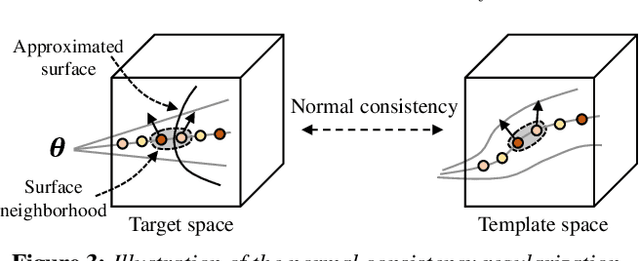
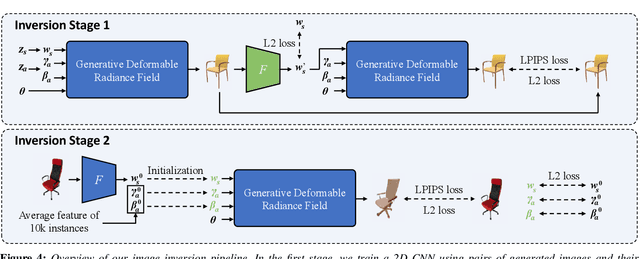
3D-aware generative models have demonstrated their superb performance to generate 3D neural radiance fields (NeRF) from a collection of monocular 2D images even for topology-varying object categories. However, these methods still lack the capability to separately control the shape and appearance of the objects in the generated radiance fields. In this paper, we propose a generative model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. Our method generates deformable radiance fields, which builds the dense correspondence between the density fields of the objects and encodes their appearances in a shared template field. Our disentanglement is achieved in an unsupervised manner without introducing extra labels to previous 3D-aware GAN training. We also develop an effective image inversion scheme for reconstructing the radiance field of an object in a real monocular image and manipulating its shape and appearance. Experiments show that our method can successfully learn the generative model from unstructured monocular images and well disentangle the shape and appearance for objects (e.g., chairs) with large topological variance. The model trained on synthetic data can faithfully reconstruct the real object in a given single image and achieve high-quality texture and shape editing results.