 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT: A Data-Free Continual Learning Approach for Real-Time Semantic Segmentation via Boundary Guidance
May 26, 2026Real-time semantic segmentation models offer an excellent balance between accuracy and inference speed. However, deploying these models in dynamic real world environments often requires the ability to learn novel classes incrementally without retraining on the entire dataset. This capability is known as continual learning. In this regard, the standard fine-tuning methods in deep learning often fail due to catastrophic forgetting, where the model learns new information but forgets previously trained and learned classes. Contributing to this crucial domain, the current paper proposes a novel continual learning framework tailored for PIDNet, which is a widely cited state-of-the-art real-time semantic segmentation model. Our method, PILOT(Parallel Incremental Learning Over Time), introduces a real-time and lightweight strategy by implementing a parallel Derivative-branch (D-branch) designed to capture the high frequency boundary information of novel classes while freezing the trained parameters of the original segmentation network. This novel setup allows the model to adapt to new semantic categories while preserving the knowledge of previously learned classes. By using only data associated with the new class, our model significantly reduces training overhead. Experimental results demonstrate that our approach successfully segments new classes while maintaining high mean Intersection over Union (mIoU) on the original base classes, thereby comfortably outperforming all major continual learning approaches in this domain. Overall, PILOT is shown to effectively mitigate catastrophic forgetting with minimal impact on inference latency, thus maintaining real-time performance.
Explainable Machine Learning for Cyberattack Identification from Traffic Flows
May 02, 2025The increasing automation of traffic management systems has made them prime targets for cyberattacks, disrupting urban mobility and public safety. Traditional network-layer defenses are often inaccessible to transportation agencies, necessitating a machine learning-based approach that relies solely on traffic flow data. In this study, we simulate cyberattacks in a semi-realistic environment, using a virtualized traffic network to analyze disruption patterns. We develop a deep learning-based anomaly detection system, demonstrating that Longest Stop Duration and Total Jam Distance are key indicators of compromised signals. To enhance interpretability, we apply Explainable AI (XAI) techniques, identifying critical decision factors and diagnosing misclassification errors. Our analysis reveals two primary challenges: transitional data inconsistencies, where mislabeled recovery-phase traffic misleads the model, and model limitations, where stealth attacks in low-traffic conditions evade detection. This work enhances AI-driven traffic security, improving both detection accuracy and trustworthiness in smart transportation systems.
Machine Learning for Cyber-Attack Identification from Traffic Flows
May 02, 2025This paper presents our simulation of cyber-attacks and detection strategies on the traffic control system in Daytona Beach, FL. using Raspberry Pi virtual machines and the OPNSense firewall, along with traffic dynamics from SUMO and exploitation via the Metasploit framework. We try to answer the research questions: are we able to identify cyber attacks by only analyzing traffic flow patterns. In this research, the cyber attacks are focused particularly when lights are randomly turned all green or red at busy intersections by adversarial attackers. Despite challenges stemming from imbalanced data and overlapping traffic patterns, our best model shows 85\% accuracy when detecting intrusions purely using traffic flow statistics. Key indicators for successful detection included occupancy, jam length, and halting durations.
Explainable AI for Comparative Analysis of Intrusion Detection Models
Jun 14, 2024Explainable Artificial Intelligence (XAI) has become a widely discussed topic, the related technologies facilitate better understanding of conventional black-box models like Random Forest, Neural Networks and etc. However, domain-specific applications of XAI are still insufficient. To fill this gap, this research analyzes various machine learning models to the tasks of binary and multi-class classification for intrusion detection from network traffic on the same dataset using occlusion sensitivity. The models evaluated include Linear Regression, Logistic Regression, Linear Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Random Forest, Decision Trees, and Multi-Layer Perceptrons (MLP). We trained all models to the accuracy of 90\% on the UNSW-NB15 Dataset. We found that most classifiers leverage only less than three critical features to achieve such accuracies, indicating that effective feature engineering could actually be far more important for intrusion detection than applying complicated models. We also discover that Random Forest provides the best performance in terms of accuracy, time efficiency and robustness. Data and code available at https://github.com/pcwhy/XML-IntrusionDetection.git
GraphDAC: A Graph-Analytic Approach to Dynamic Airspace Configuration
Jul 29, 2023



The current National Airspace System (NAS) is reaching capacity due to increased air traffic, and is based on outdated pre-tactical planning. This study proposes a more dynamic airspace configuration (DAC) approach that could increase throughput and accommodate fluctuating traffic, ideal for emergencies. The proposed approach constructs the airspace as a constraints-embedded graph, compresses its dimensions, and applies a spectral clustering-enabled adaptive algorithm to generate collaborative airport groups and evenly distribute workloads among them. Under various traffic conditions, our experiments demonstrate a 50\% reduction in workload imbalances. This research could ultimately form the basis for a recommendation system for optimized airspace configuration. Code available at https://github.com/KeFenge2022/GraphDAC.git
NoiseCAM: Explainable AI for the Boundary Between Noise and Adversarial Attacks
Mar 09, 2023



Deep Learning (DL) and Deep Neural Networks (DNNs) are widely used in various domains. However, adversarial attacks can easily mislead a neural network and lead to wrong decisions. Defense mechanisms are highly preferred in safety-critical applications. In this paper, firstly, we use the gradient class activation map (GradCAM) to analyze the behavior deviation of the VGG-16 network when its inputs are mixed with adversarial perturbation or Gaussian noise. In particular, our method can locate vulnerable layers that are sensitive to adversarial perturbation and Gaussian noise. We also show that the behavior deviation of vulnerable layers can be used to detect adversarial examples. Secondly, we propose a novel NoiseCAM algorithm that integrates information from globally and pixel-level weighted class activation maps. Our algorithm is susceptible to adversarial perturbations and will not respond to Gaussian random noise mixed in the inputs. Third, we compare detecting adversarial examples using both behavior deviation and NoiseCAM, and we show that NoiseCAM outperforms behavior deviation modeling in its overall performance. Our work could provide a useful tool to defend against certain adversarial attacks on deep neural networks.
Exploring Adversarial Attacks on Neural Networks: An Explainable Approach
Mar 08, 2023Deep Learning (DL) is being applied in various domains, especially in safety-critical applications such as autonomous driving. Consequently, it is of great significance to ensure the robustness of these methods and thus counteract uncertain behaviors caused by adversarial attacks. In this paper, we use gradient heatmaps to analyze the response characteristics of the VGG-16 model when the input images are mixed with adversarial noise and statistically similar Gaussian random noise. In particular, we compare the network response layer by layer to determine where errors occurred. Several interesting findings are derived. First, compared to Gaussian random noise, intentionally generated adversarial noise causes severe behavior deviation by distracting the area of concentration in the networks. Second, in many cases, adversarial examples only need to compromise a few intermediate blocks to mislead the final decision. Third, our experiments revealed that specific blocks are more vulnerable and easier to exploit by adversarial examples. Finally, we demonstrate that the layers $Block4\_conv1$ and $Block5\_cov1$ of the VGG-16 model are more susceptible to adversarial attacks. Our work could provide valuable insights into developing more reliable Deep Neural Network (DNN) models.
Zero-bias Deep Neural Network for Quickest RF Signal Surveillance
Oct 12, 2021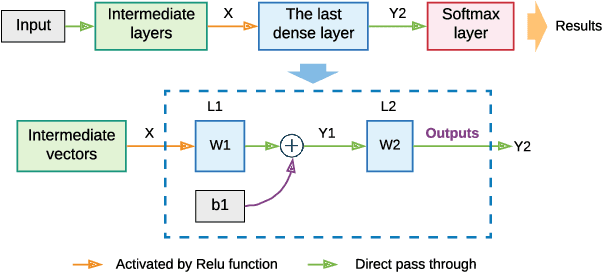
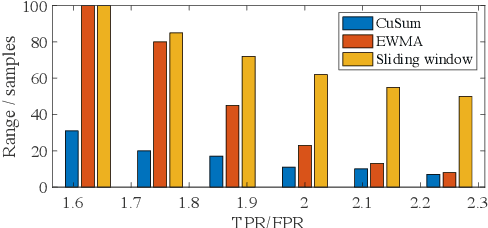
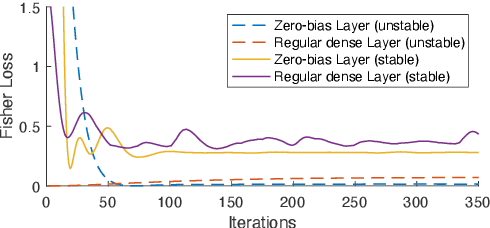
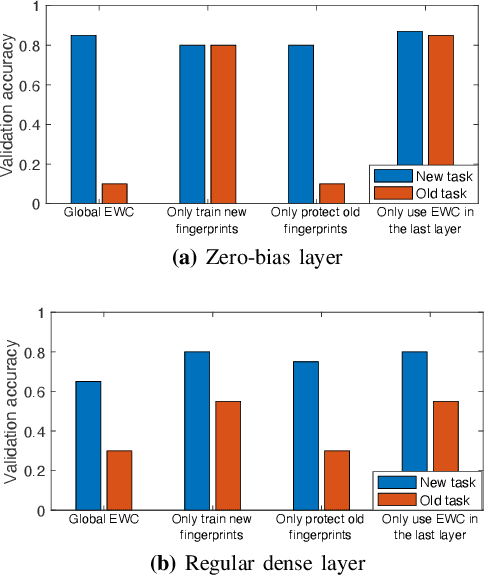
The Internet of Things (IoT) is reshaping modern society by allowing a decent number of RF devices to connect and share information through RF channels. However, such an open nature also brings obstacles to surveillance. For alleviation, a surveillance oracle, or a cognitive communication entity needs to identify and confirm the appearance of known or unknown signal sources in real-time. In this paper, we provide a deep learning framework for RF signal surveillance. Specifically, we jointly integrate the Deep Neural Networks (DNNs) and Quickest Detection (QD) to form a sequential signal surveillance scheme. We first analyze the latent space characteristic of neural network classification models, and then we leverage the response characteristics of DNN classifiers and propose a novel method to transform existing DNN classifiers into performance-assured binary abnormality detectors. In this way, we seamlessly integrate the DNNs with the parametric quickest detection. Finally, we propose an enhanced Elastic Weight Consolidation (EWC) algorithm with better numerical stability for DNNs in signal surveillance systems to evolve incrementally, we demonstrate that the zero-bias DNN is superior to regular DNN models considering incremental learning and decision fairness. We evaluated the proposed framework using real signal datasets and we believe this framework is helpful in developing a trustworthy IoT ecosystem.
Class-Incremental Learning for Wireless Device Identification in IoT
May 08, 2021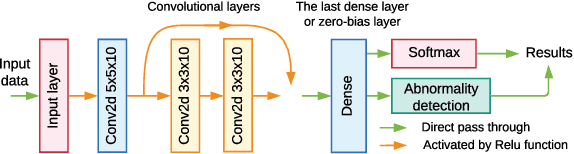
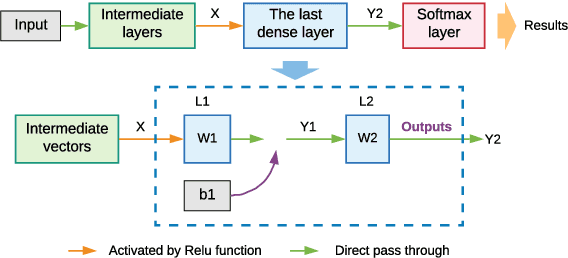
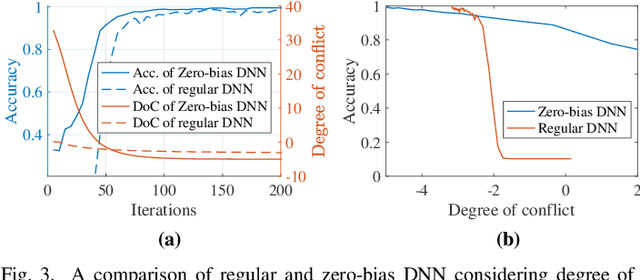
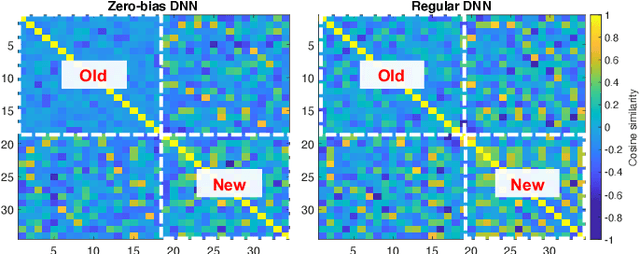
Deep Learning (DL) has been utilized pervasively in the Internet of Things (IoT). One typical application of DL in IoT is device identification from wireless signals, namely Non-cryptographic Device Identification (NDI). However, learning components in NDI systems have to evolve to adapt to operational variations, such a paradigm is termed as Incremental Learning (IL). Various IL algorithms have been proposed and many of them require dedicated space to store the increasing amount of historical data, and therefore, they are not suitable for IoT or mobile applications. However, conventional IL schemes can not provide satisfying performance when historical data are not available. In this paper, we address the IL problem in NDI from a new perspective, firstly, we provide a new metric to measure the degree of topological maturity of DNN models from the degree of conflict of class-specific fingerprints. We discover that an important cause for performance degradation in IL enabled NDI is owing to the conflict of devices' fingerprints. Second, we also show that the conventional IL schemes can lead to low topological maturity of DNN models in NDI systems. Thirdly, we propose a new Channel Separation Enabled Incremental Learning (CSIL) scheme without using historical data, in which our strategy can automatically separate devices' fingerprints in different learning stages and avoid potential conflict. Finally, We evaluated the effectiveness of the proposed framework using real data from ADS-B (Automatic Dependent Surveillance-Broadcast), an application of IoT in aviation. The proposed framework has the potential to be applied to accurate identification of IoT devices in a variety of IoT applications and services. Data and code available at IEEE Dataport (DOI: 10.21227/1bxc-ke87) and \url{https://github.com/pcwhy/CSIL}}
Machine Learning for the Detection and Identification of Internet of Things (IoT) Devices: A Survey
Jan 25, 2021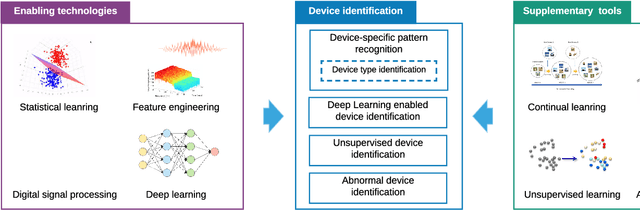
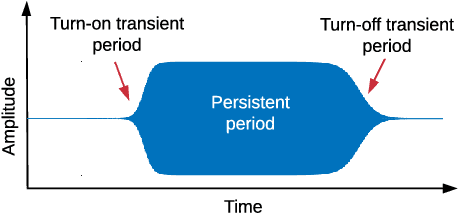
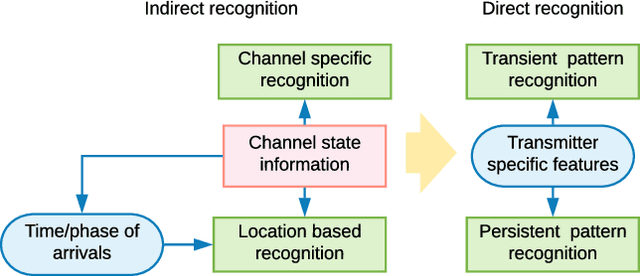
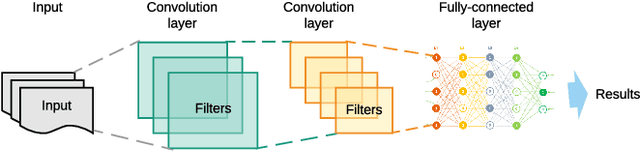
The Internet of Things (IoT) is becoming an indispensable part of everyday life, enabling a variety of emerging services and applications. However, the presence of rogue IoT devices has exposed the IoT to untold risks with severe consequences. The first step in securing the IoT is detecting rogue IoT devices and identifying legitimate ones. Conventional approaches use cryptographic mechanisms to authenticate and verify legitimate devices' identities. However, cryptographic protocols are not available in many systems. Meanwhile, these methods are less effective when legitimate devices can be exploited or encryption keys are disclosed. Therefore, non-cryptographic IoT device identification and rogue device detection become efficient solutions to secure existing systems and will provide additional protection to systems with cryptographic protocols. Non-cryptographic approaches require more effort and are not yet adequately investigated. In this paper, we provide a comprehensive survey on machine learning technologies for the identification of IoT devices along with the detection of compromised or falsified ones from the viewpoint of passive surveillance agents or network operators. We classify the IoT device identification and detection into four categories: device-specific pattern recognition, Deep Learning enabled device identification, unsupervised device identification, and abnormal device detection. Meanwhile, we discuss various ML-related enabling technologies for this purpose. These enabling technologies include learning algorithms, feature engineering on network traffic traces and wireless signals, continual learning, and abnormality detection.