 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANE-GNN: Unifying Positive and Negative Edges in Graph Neural Networks for Recommendation
Jun 08, 2023



Recommender systems play a crucial role in addressing the issue of information overload by delivering personalized recommendations to users. In recent years, there has been a growing interest in leveraging graph neural networks (GNNs) for recommender systems, capitalizing on advancements in graph representation learning. These GNN-based models primarily focus on analyzing users' positive feedback while overlooking the valuable insights provided by their negative feedback. In this paper, we propose PANE-GNN, an innovative recommendation model that unifies Positive And Negative Edges in Graph Neural Networks for recommendation. By incorporating user preferences and dispreferences, our approach enhances the capability of recommender systems to offer personalized suggestions. PANE-GNN first partitions the raw rating graph into two distinct bipartite graphs based on positive and negative feedback. Subsequently, we employ two separate embeddings, the interest embedding and the disinterest embedding, to capture users' likes and dislikes, respectively. To facilitate effective information propagation, we design distinct message-passing mechanisms for positive and negative feedback. Furthermore, we introduce a distortion to the negative graph, which exclusively consists of negative feedback edges, for contrastive training. This distortion plays a crucial role in effectively denoising the negative feedback. The experimental results provide compelling evidence that PANE-GNN surpasses the existing state-of-the-art benchmark methods across four real-world datasets. These datasets include three commonly used recommender system datasets and one open-source short video recommendation dataset.
Knowledge Distillation based Contextual Relevance Matching for E-commerce Product Search
Oct 04, 2022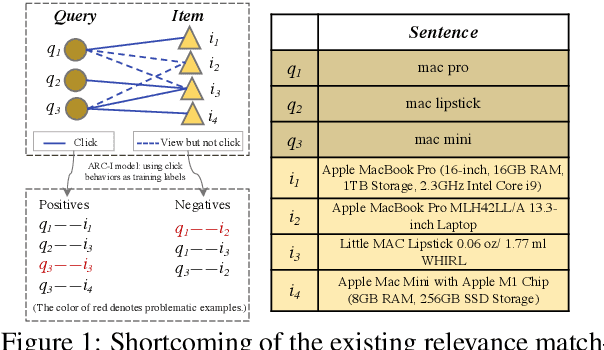
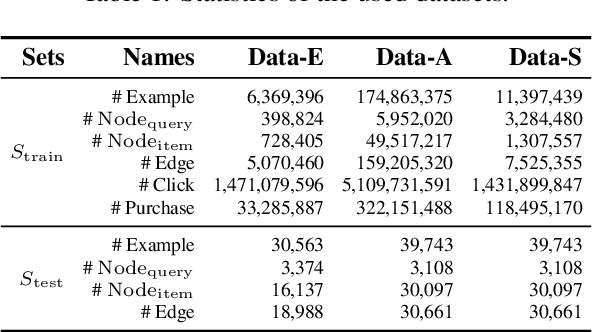
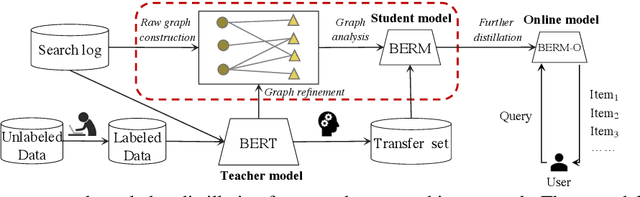
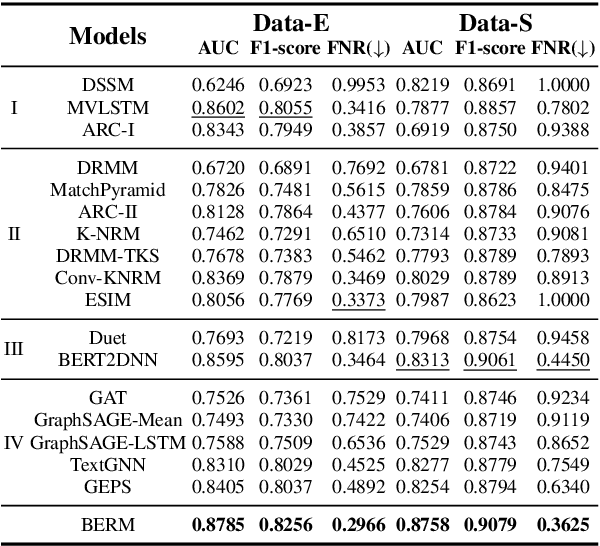
Online relevance matching is an essential task of e-commerce product search to boost the utility of search engines and ensure a smooth user experience. Previous work adopts either classical relevance matching models or Transformer-style models to address it. However, they ignore the inherent bipartite graph structures that are ubiquitous in e-commerce product search logs and are too inefficient to deploy online. In this paper, we design an efficient knowledge distillation framework for e-commerce relevance matching to integrate the respective advantages of Transformer-style models and classical relevance matching models. Especially for the core student model of the framework, we propose a novel method using $k$-order relevance modeling. The experimental results on large-scale real-world data (the size is 6$\sim$174 million) show that the proposed method significantly improves the prediction accuracy in terms of human relevance judgment. We deploy our method to the anonymous online search platform. The A/B testing results show that our method significantly improves 5.7% of UV-value under price sort mode.
TeKo: Text-Rich Graph Neural Networks with External Knowledge
Jun 15, 2022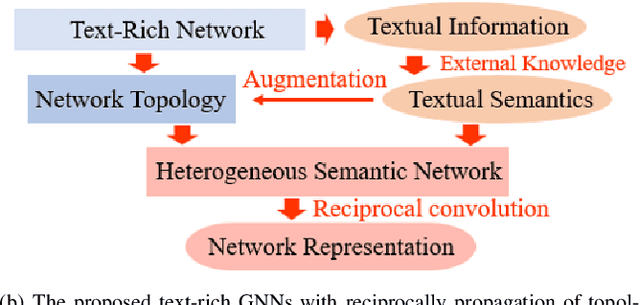
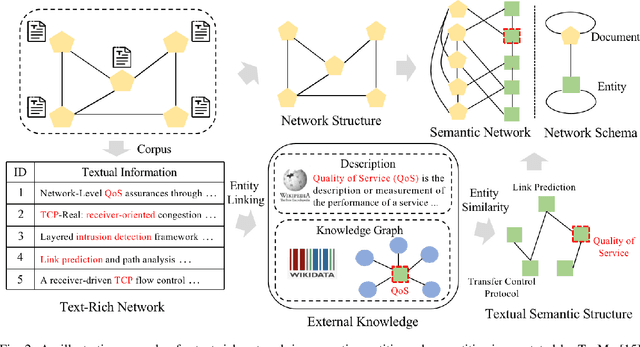
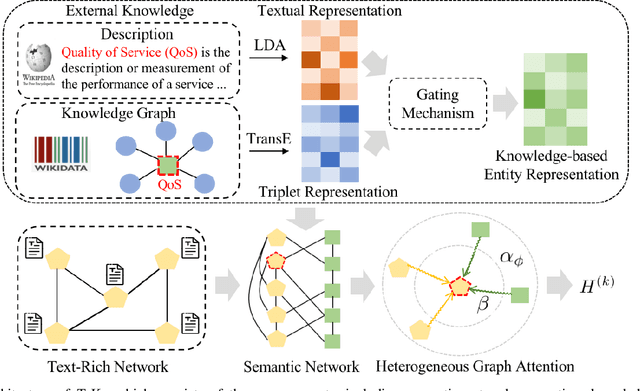

Graph Neural Networks (GNNs) have gained great popularity in tackling various analytical tasks on graph-structured data (i.e., networks). Typical GNNs and their variants follow a message-passing manner that obtains network representations by the feature propagation process along network topology, which however ignore the rich textual semantics (e.g., local word-sequence) that exist in many real-world networks. Existing methods for text-rich networks integrate textual semantics by mainly utilizing internal information such as topics or phrases/words, which often suffer from an inability to comprehensively mine the text semantics, limiting the reciprocal guidance between network structure and text semantics. To address these problems, we propose a novel text-rich graph neural network with external knowledge (TeKo), in order to take full advantage of both structural and textual information within text-rich networks. Specifically, we first present a flexible heterogeneous semantic network that incorporates high-quality entities and interactions among documents and entities. We then introduce two types of external knowledge, that is, structured triplets and unstructured entity description, to gain a deeper insight into textual semantics. We further design a reciprocal convolutional mechanism for the constructed heterogeneous semantic network, enabling network structure and textual semantics to collaboratively enhance each other and learn high-level network representations. Extensive experimental results on four public text-rich networks as well as a large-scale e-commerce searching dataset illustrate the superior performance of TeKo over state-of-the-art baselines.
RDU: A Region-based Approach to Form-style Document Understanding
Jun 14, 2022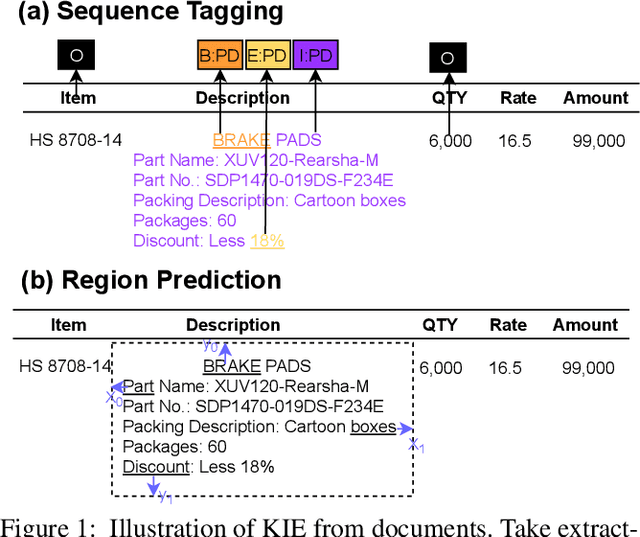
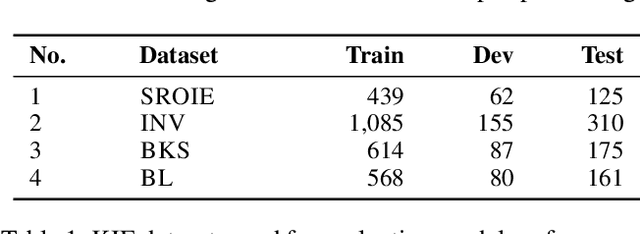
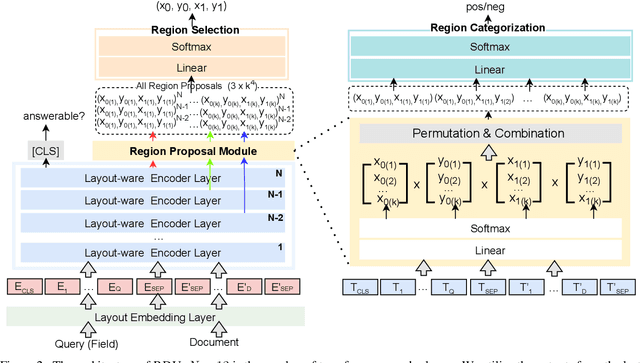
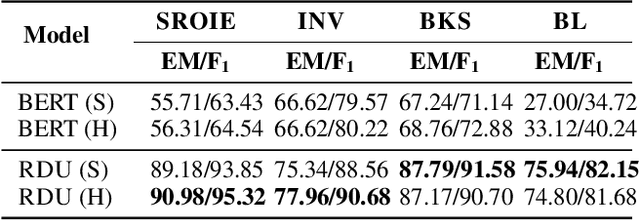
Key Information Extraction (KIE) is aimed at extracting structured information (e.g. key-value pairs) from form-style documents (e.g. invoices), which makes an important step towards intelligent document understanding. Previous approaches generally tackle KIE by sequence tagging, which faces difficulty to process non-flatten sequences, especially for table-text mixed documents. These approaches also suffer from the trouble of pre-defining a fixed set of labels for each type of documents, as well as the label imbalance issue. In this work, we assume Optical Character Recognition (OCR) has been applied to input documents, and reformulate the KIE task as a region prediction problem in the two-dimensional (2D) space given a target field. Following this new setup, we develop a new KIE model named Region-based Document Understanding (RDU) that takes as input the text content and corresponding coordinates of a document, and tries to predict the result by localizing a bounding-box-like region. Our RDU first applies a layout-aware BERT equipped with a soft layout attention masking and bias mechanism to incorporate layout information into the representations. Then, a list of candidate regions is generated from the representations via a Region Proposal Module inspired by computer vision models widely applied for object detection. Finally, a Region Categorization Module and a Region Selection Module are adopted to judge whether a proposed region is valid and select the one with the largest probability from all proposed regions respectively. Experiments on four types of form-style documents show that our proposed method can achieve impressive results. In addition, our RDU model can be trained with different document types seamlessly, which is especially helpful over low-resource documents.
DSRGAN: Detail Prior-Assisted Perceptual Single Image Super-Resolution via Generative Adversarial Networks
Dec 25, 2021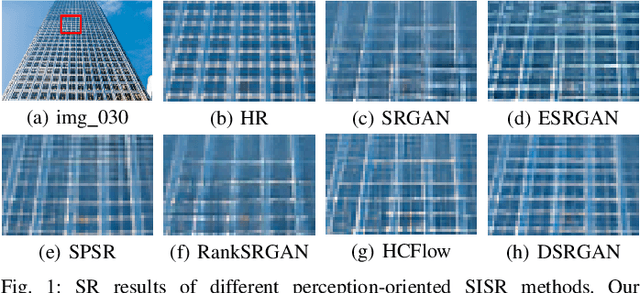
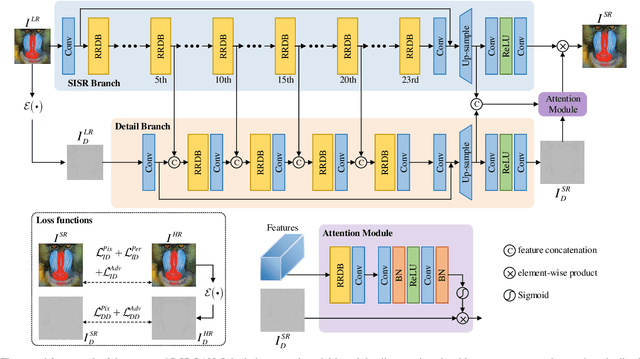


The generative adversarial network (GAN) is successfully applied to study the perceptual single image superresolution (SISR). However, the GAN often tends to generate images with high frequency details being inconsistent with the real ones. Inspired by conventional detail enhancement algorithms, we propose a novel prior knowledge, the detail prior, to assist the GAN in alleviating this problem and restoring more realistic details. The proposed method, named DSRGAN, includes a well designed detail extraction algorithm to capture the most important high frequency information from images. Then, two discriminators are utilized for supervision on image-domain and detail-domain restorations, respectively. The DSRGAN merges the restored detail into the final output via a detail enhancement manner. The special design of DSRGAN takes advantages from both the model-based conventional algorithm and the data-driven deep learning network. Experimental results demonstrate that the DSRGAN outperforms the state-of-the-art SISR methods on perceptual metrics and achieves comparable results in terms of fidelity metrics simultaneously. Following the DSRGAN, it is feasible to incorporate other conventional image processing algorithms into a deep learning network to form a model-based deep SISR.
FAMINet: Learning Real-time Semi-supervised Video Object Segmentation with Steepest Optimized Optical Flow
Nov 20, 2021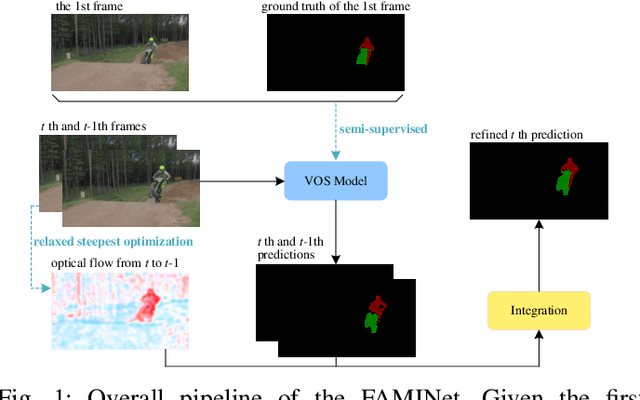

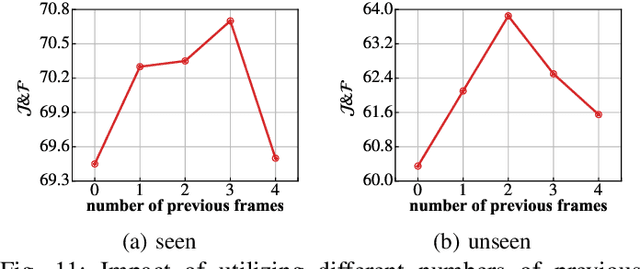
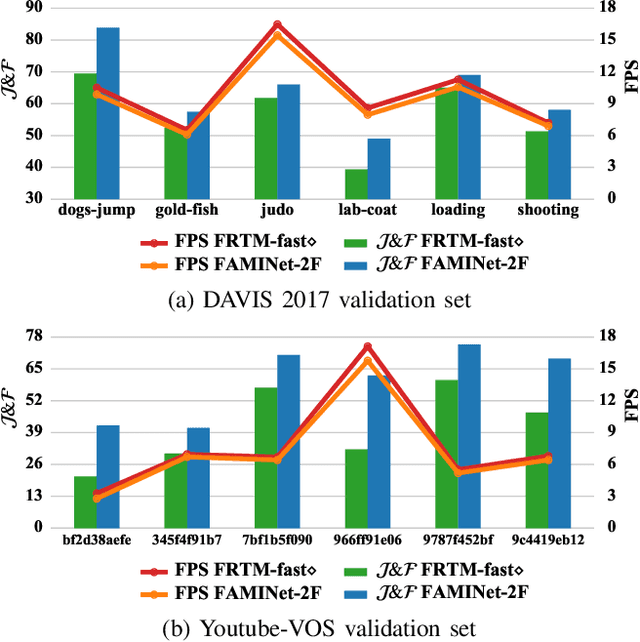
Semi-supervised video object segmentation (VOS) aims to segment a few moving objects in a video sequence, where these objects are specified by annotation of first frame. The optical flow has been considered in many existing semi-supervised VOS methods to improve the segmentation accuracy. However, the optical flow-based semi-supervised VOS methods cannot run in real time due to high complexity of optical flow estimation. A FAMINet, which consists of a feature extraction network (F), an appearance network (A), a motion network (M), and an integration network (I), is proposed in this study to address the abovementioned problem. The appearance network outputs an initial segmentation result based on static appearances of objects. The motion network estimates the optical flow via very few parameters, which are optimized rapidly by an online memorizing algorithm named relaxed steepest descent. The integration network refines the initial segmentation result using the optical flow. Extensive experiments demonstrate that the FAMINet outperforms other state-of-the-art semi-supervised VOS methods on the DAVIS and YouTube-VOS benchmarks, and it achieves a good trade-off between accuracy and efficiency. Our code is available at https://github.com/liuziyang123/FAMINet.
Deep Joint Demosaicing and High Dynamic Range Imaging within a Single Shot
Nov 14, 2021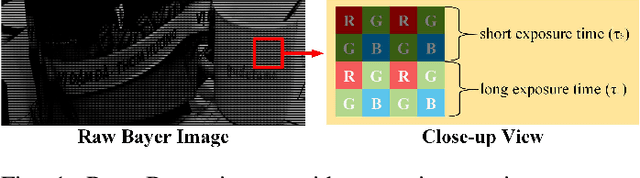
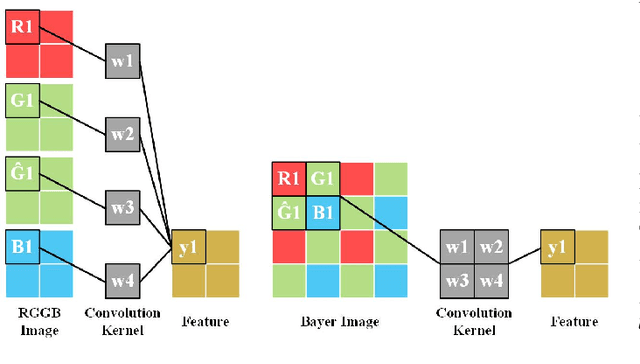


Spatially varying exposure (SVE) is a promising choice for high-dynamic-range (HDR) imaging (HDRI). The SVE-based HDRI, which is called single-shot HDRI, is an efficient solution to avoid ghosting artifacts. However, it is very challenging to restore a full-resolution HDR image from a real-world image with SVE because: a) only one-third of pixels with varying exposures are captured by camera in a Bayer pattern, b) some of the captured pixels are over- and under-exposed. For the former challenge, a spatially varying convolution (SVC) is designed to process the Bayer images carried with varying exposures. For the latter one, an exposure-guidance method is proposed against the interference from over- and under-exposed pixels. Finally, a joint demosaicing and HDRI deep learning framework is formalized to include the two novel components and to realize an end-to-end single-shot HDRI. Experiments indicate that the proposed end-to-end framework avoids the problem of cumulative errors and surpasses the related state-of-the-art methods.
Brain Age Estimation From MRI Using Cascade Networks with Ranking Loss
Jun 06, 2021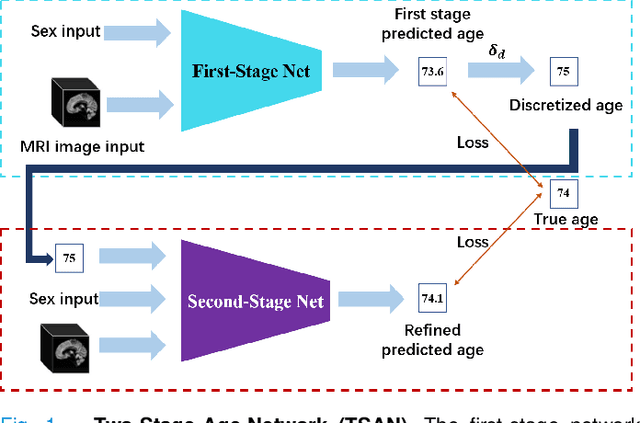
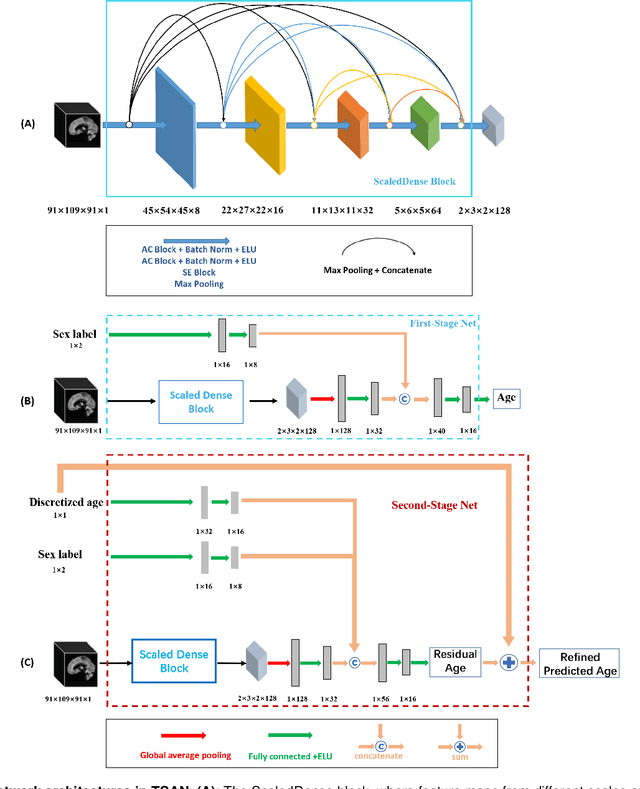
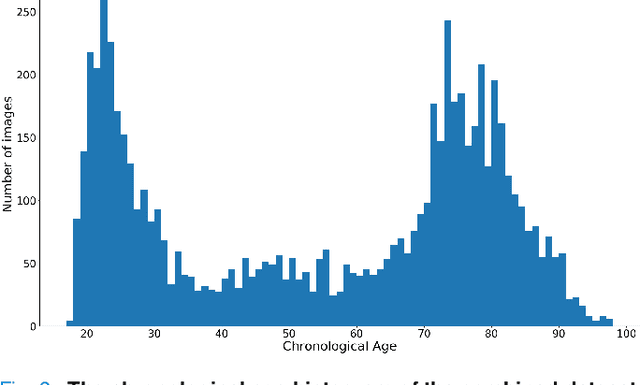
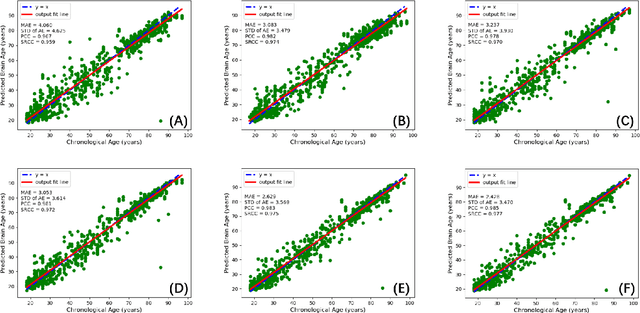
Chronological age of healthy people is able to be predicted accurately using deep neural networks from neuroimaging data, and the predicted brain age could serve as a biomarker for detecting aging-related diseases. In this paper, a novel 3D convolutional network, called two-stage-age-network (TSAN), is proposed to estimate brain age from T1-weighted MRI data. Compared with existing methods, TSAN has the following improvements. First, TSAN uses a two-stage cascade network architecture, where the first-stage network estimates a rough brain age, then the second-stage network estimates the brain age more accurately from the discretized brain age by the first-stage network. Second, to our knowledge, TSAN is the first work to apply novel ranking losses in brain age estimation, together with the traditional mean square error (MSE) loss. Third, densely connected paths are used to combine feature maps with different scales. The experiments with $6586$ MRIs showed that TSAN could provide accurate brain age estimation, yielding mean absolute error (MAE) of $2.428$ and Pearson's correlation coefficient (PCC) of $0.985$, between the estimated and chronological ages. Furthermore, using the brain age gap between brain age and chronological age as a biomarker, Alzheimer's disease (AD) and Mild Cognitive Impairment (MCI) can be distinguished from healthy control (HC) subjects by support vector machine (SVM). Classification AUC in AD/HC and MCI/HC was $0.904$ and $0.823$, respectively. It showed that brain age gap is an effective biomarker associated with risk of dementia, and has potential for early-stage dementia risk screening. The codes and trained models have been released on GitHub: https://github.com/Milan-BUAA/TSAN-brain-age-estimation.
Heterogeneous Network Embedding for Deep Semantic Relevance Match in E-commerce Search
Jan 13, 2021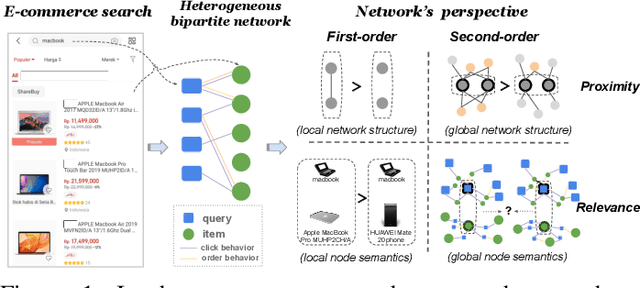
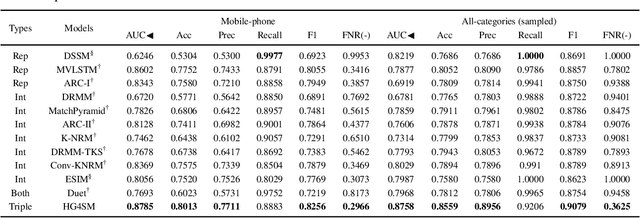
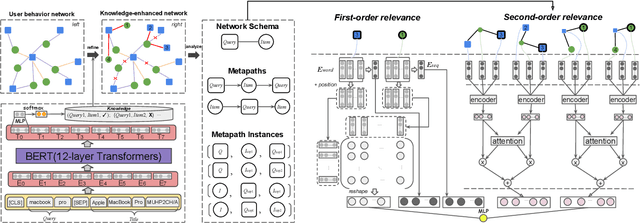
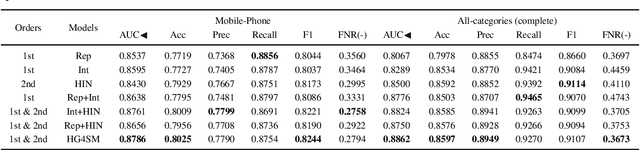
Result relevance prediction is an essential task of e-commerce search engines to boost the utility of search engines and ensure smooth user experience. The last few years eyewitnessed a flurry of research on the use of Transformer-style models and deep text-match models to improve relevance. However, these two types of models ignored the inherent bipartite network structures that are ubiquitous in e-commerce search logs, making these models ineffective. We propose in this paper a novel Second-order Relevance, which is fundamentally different from the previous First-order Relevance, to improve result relevance prediction. We design, for the first time, an end-to-end First-and-Second-order Relevance prediction model for e-commerce item relevance. The model is augmented by the neighborhood structures of bipartite networks that are built using the information of user behavioral feedback, including clicks and purchases. To ensure that edges accurately encode relevance information, we introduce external knowledge generated from BERT to refine the network of user behaviors. This allows the new model to integrate information from neighboring items and queries, which are highly relevant to the focus query-item pair under consideration. Results of offline experiments showed that the new model significantly improved the prediction accuracy in terms of human relevance judgment. An ablation study showed that the First-and-Second-order model gained a 4.3% average gain over the First-order model. Results of an online A/B test revealed that the new model derived more commercial benefits compared to the base model.
BiTe-GCN: A New GCN Architecture via BidirectionalConvolution of Topology and Features on Text-Rich Networks
Oct 23, 2020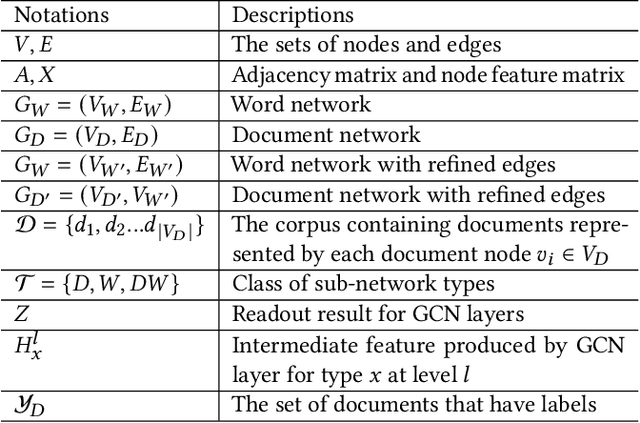
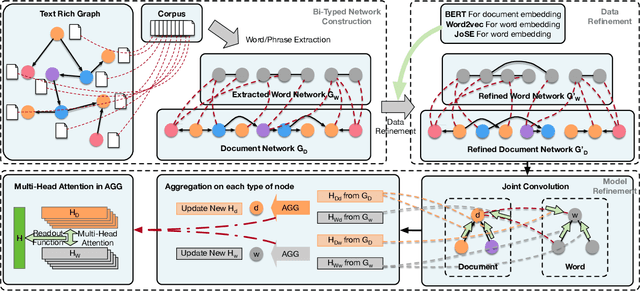
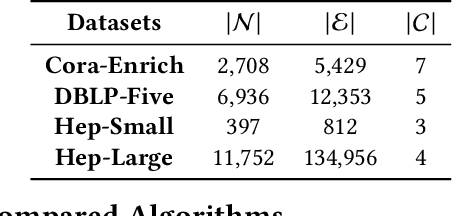
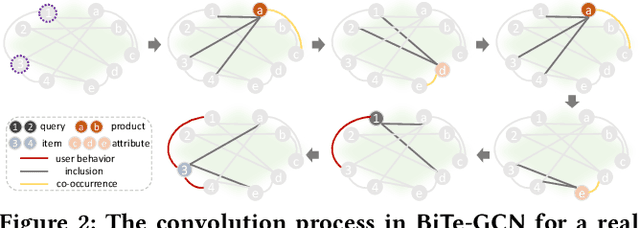
Graph convolutional networks (GCNs), aiming to integrate high-order neighborhood information through stacked graph convolution layers, have demonstrated remarkable power in many network analysis tasks. However, topological limitations, including over-smoothing and local topology homophily, limit its capability to represent networks. Existing studies only perform feature convolution on network topology, which inevitably introduces unbalance between topology and features. Considering that in real world, the information network consists of not only the node-level citation information but also the local text-sequence information. We propose BiTe-GCN, a novel GCN architecture with bidirectional convolution of both topology and features on text-rich networks to solve these limitations. We first transform the original text-rich network into an augmented bi-typed heterogeneous network, capturing both the global node-level information and the local text-sequence information from texts. We then introduce discriminative convolution mechanisms to performs convolutions of both topology and features simultaneously. Extensive experiments on text-rich networks demonstrate that our new architecture outperforms state-of-the-art by a breakout improvement. Moreover, this architecture can also be applied to several e-commerce searching scenes such as JD\ searching. The experiments on the JD dataset validate the superiority of the proposed architecture over the related methods.