 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mitigating Hallucination in Large Language Models via Self-Reflection
Oct 10, 2023



Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
Negative Object Presence Evaluation (NOPE) to Measure Object Hallucination in Vision-Language Models
Oct 09, 2023Object hallucination poses a significant challenge in vision-language (VL) models, often leading to the generation of nonsensical or unfaithful responses with non-existent objects. However, the absence of a general measurement for evaluating object hallucination in VL models has hindered our understanding and ability to mitigate this issue. In this work, we present NOPE (Negative Object Presence Evaluation), a novel benchmark designed to assess object hallucination in VL models through visual question answering (VQA). We propose a cost-effective and scalable approach utilizing large language models to generate 29.5k synthetic negative pronoun (NegP) data of high quality for NOPE. We extensively investigate the performance of 10 state-of-the-art VL models in discerning the non-existence of objects in visual questions, where the ground truth answers are denoted as NegP (e.g., "none"). Additionally, we evaluate their standard performance on visual questions on 9 other VQA datasets. Through our experiments, we demonstrate that no VL model is immune to the vulnerability of object hallucination, as all models achieve accuracy below 10\% on NegP. Furthermore, we uncover that lexically diverse visual questions, question types with large scopes, and scene-relevant objects capitalize the risk of object hallucination in VL models.
Think before you speak: Training Language Models With Pause Tokens
Oct 03, 2023Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $\textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $\textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18\%$ EM score on the QA task of SQuAD, $8\%$ on CommonSenseQA and $1\%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
Improving Query-Focused Meeting Summarization with Query-Relevant Knowledge
Sep 05, 2023Query-Focused Meeting Summarization (QFMS) aims to generate a summary of a given meeting transcript conditioned upon a query. The main challenges for QFMS are the long input text length and sparse query-relevant information in the meeting transcript. In this paper, we propose a knowledge-enhanced two-stage framework called Knowledge-Aware Summarizer (KAS) to tackle the challenges. In the first stage, we introduce knowledge-aware scores to improve the query-relevant segment extraction. In the second stage, we incorporate query-relevant knowledge in the summary generation. Experimental results on the QMSum dataset show that our approach achieves state-of-the-art performance. Further analysis proves the competency of our methods in generating relevant and faithful summaries.
Diverse and Faithful Knowledge-Grounded Dialogue Generation via Sequential Posterior Inference
Jun 01, 2023



The capability to generate responses with diversity and faithfulness using factual knowledge is paramount for creating a human-like, trustworthy dialogue system. Common strategies either adopt a two-step paradigm, which optimizes knowledge selection and response generation separately, and may overlook the inherent correlation between these two tasks, or leverage conditional variational method to jointly optimize knowledge selection and response generation by employing an inference network. In this paper, we present an end-to-end learning framework, termed Sequential Posterior Inference (SPI), capable of selecting knowledge and generating dialogues by approximately sampling from the posterior distribution. Unlike other methods, SPI does not require the inference network or assume a simple geometry of the posterior distribution. This straightforward and intuitive inference procedure of SPI directly queries the response generation model, allowing for accurate knowledge selection and generation of faithful responses. In addition to modeling contributions, our experimental results on two common dialogue datasets (Wizard of Wikipedia and Holl-E) demonstrate that SPI outperforms previous strong baselines according to both automatic and human evaluation metrics.
Depth Dependence of $μ$P Learning Rates in ReLU MLPs
May 13, 2023In this short note we consider random fully connected ReLU networks of width $n$ and depth $L$ equipped with a mean-field weight initialization. Our purpose is to study the dependence on $n$ and $L$ of the maximal update ($\mu$P) learning rate, the largest learning rate for which the mean squared change in pre-activations after one step of gradient descent remains uniformly bounded at large $n,L$. As in prior work on $\mu$P of Yang et. al., we find that this maximal update learning rate is independent of $n$ for all but the first and last layer weights. However, we find that it has a non-trivial dependence of $L$, scaling like $L^{-3/2}.$
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity
Feb 28, 2023



This paper proposes a framework for quantitatively evaluating interactive LLMs such as ChatGPT using publicly available data sets. We carry out an extensive technical evaluation of ChatGPT using 23 data sets covering 8 different common NLP application tasks. We evaluate the multitask, multilingual and multi-modal aspects of ChatGPT based on these data sets and a newly designed multimodal dataset. We find that ChatGPT outperforms LLMs with zero-shot learning on most tasks and even outperforms fine-tuned models on some tasks. We find that it is better at understanding non-Latin script languages than generating them. It is able to generate multimodal content from textual prompts, via an intermediate code generation step. Moreover, we find that ChatGPT is 63.41% accurate on average in 10 different reasoning categories under logical reasoning, non-textual reasoning, and commonsense reasoning, hence making it an unreliable reasoner. It is, for example, better at deductive than inductive reasoning. ChatGPT suffers from hallucination problems like other LLMs and it generates more extrinsic hallucinations from its parametric memory as it does not have access to an external knowledge base. Finally, the interactive feature of ChatGPT enables human collaboration with the underlying LLM to improve its performance, i.e, 8% ROUGE-1 on summarization and 2% ChrF++ on machine translation, in a multi-turn "prompt engineering" fashion. We also release codebase for evaluation set extraction.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
RHO ($ρ$): Reducing Hallucination in Open-domain Dialogues with Knowledge Grounding
Dec 03, 2022



Dialogue systems can leverage large pre-trained language models and knowledge to generate fluent and informative responses. However, these models are still prone to produce hallucinated responses not supported by the input source, which greatly hinders their application. The heterogeneity between external knowledge and dialogue context challenges representation learning and source integration, and further contributes to unfaithfulness. To handle this challenge and generate more faithful responses, this paper presents RHO ($\rho$) utilizing the representations of linked entities and relation predicates from a knowledge graph (KG). We propose (1) local knowledge grounding to combine textual embeddings with the corresponding KG embeddings; and (2) global knowledge grounding to equip RHO with multi-hop reasoning abilities via the attention mechanism. In addition, we devise a response re-ranking technique based on walks over KG sub-graphs for better conversational reasoning. Experimental results on OpenDialKG show that our approach significantly outperforms state-of-the-art methods on both automatic and human evaluation by a large margin, especially in hallucination reduction (17.54% in FeQA).
Plausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Oct 14, 2022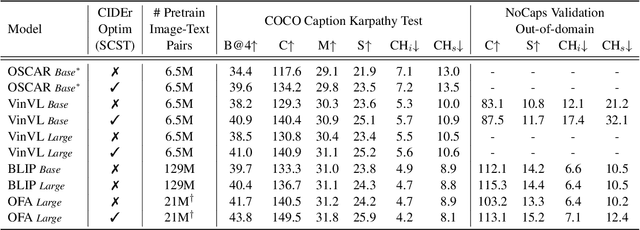

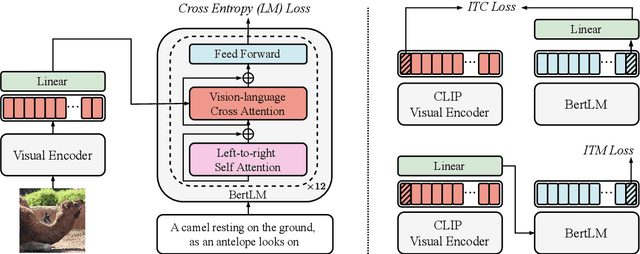
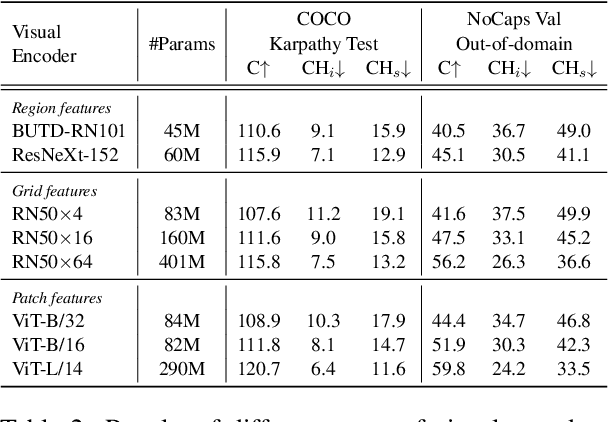
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.