 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Refocus with Video Diffusion Models
Dec 24, 2025



Focus is a cornerstone of photography, yet autofocus systems often fail to capture the intended subject, and users frequently wish to adjust focus after capture. We introduce a novel method for realistic post-capture refocusing using video diffusion models. From a single defocused image, our approach generates a perceptually accurate focal stack, represented as a video sequence, enabling interactive refocusing and unlocking a range of downstream applications. We release a large-scale focal stack dataset acquired under diverse real-world smartphone conditions to support this work and future research. Our method consistently outperforms existing approaches in both perceptual quality and robustness across challenging scenarios, paving the way for more advanced focus-editing capabilities in everyday photography. Code and data are available at https://learn2refocus.github.io
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024



Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
DriveTrack: A Benchmark for Long-Range Point Tracking in Real-World Videos
Dec 15, 2023



This paper presents DriveTrack, a new benchmark and data generation framework for long-range keypoint tracking in real-world videos. DriveTrack is motivated by the observation that the accuracy of state-of-the-art trackers depends strongly on visual attributes around the selected keypoints, such as texture and lighting. The problem is that these artifacts are especially pronounced in real-world videos, but these trackers are unable to train on such scenes due to a dearth of annotations. DriveTrack bridges this gap by building a framework to automatically annotate point tracks on autonomous driving datasets. We release a dataset consisting of 1 billion point tracks across 24 hours of video, which is seven orders of magnitude greater than prior real-world benchmarks and on par with the scale of synthetic benchmarks. DriveTrack unlocks new use cases for point tracking in real-world videos. First, we show that fine-tuning keypoint trackers on DriveTrack improves accuracy on real-world scenes by up to 7%. Second, we analyze the sensitivity of trackers to visual artifacts in real scenes and motivate the idea of running assistive keypoint selectors alongside trackers.
Fast View Synthesis of Casual Videos
Dec 04, 2023Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
Unsupervised Semantic Segmentation by Distilling Feature Correspondences
Mar 16, 2022



Unsupervised semantic segmentation aims to discover and localize semantically meaningful categories within image corpora without any form of annotation. To solve this task, algorithms must produce features for every pixel that are both semantically meaningful and compact enough to form distinct clusters. Unlike previous works which achieve this with a single end-to-end framework, we propose to separate feature learning from cluster compactification. Empirically, we show that current unsupervised feature learning frameworks already generate dense features whose correlations are semantically consistent. This observation motivates us to design STEGO ($\textbf{S}$elf-supervised $\textbf{T}$ransformer with $\textbf{E}$nergy-based $\textbf{G}$raph $\textbf{O}$ptimization), a novel framework that distills unsupervised features into high-quality discrete semantic labels. At the core of STEGO is a novel contrastive loss function that encourages features to form compact clusters while preserving their relationships across the corpora. STEGO yields a significant improvement over the prior state of the art, on both the CocoStuff ($\textbf{+14 mIoU}$) and Cityscapes ($\textbf{+9 mIoU}$) semantic segmentation challenges.
Differentiable Surface Rendering via Non-Differentiable Sampling
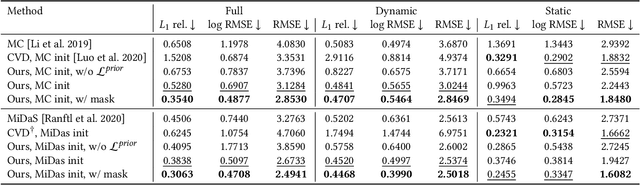
Aug 10, 2021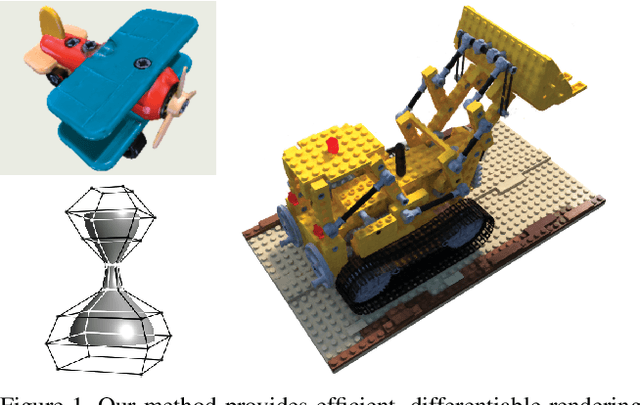

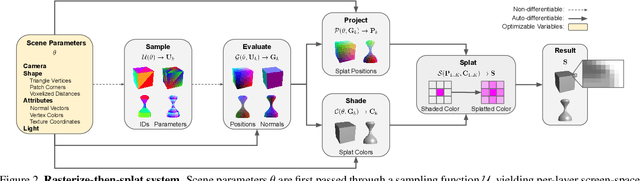
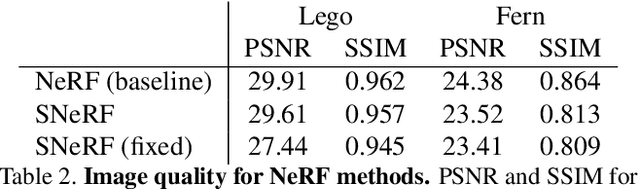
We present a method for differentiable rendering of 3D surfaces that supports both explicit and implicit representations, provides derivatives at occlusion boundaries, and is fast and simple to implement. The method first samples the surface using non-differentiable rasterization, then applies differentiable, depth-aware point splatting to produce the final image. Our approach requires no differentiable meshing or rasterization steps, making it efficient for large 3D models and applicable to isosurfaces extracted from implicit surface definitions. We demonstrate the effectiveness of our method for implicit-, mesh-, and parametric-surface-based inverse rendering and neural-network training applications. In particular, we show for the first time efficient, differentiable rendering of an isosurface extracted from a neural radiance field (NeRF), and demonstrate surface-based, rather than volume-based, rendering of a NeRF.
Consistent Depth of Moving Objects in Video
Aug 02, 2021
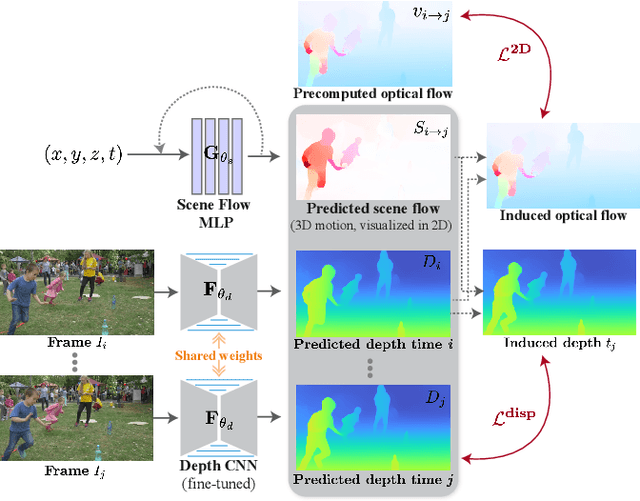
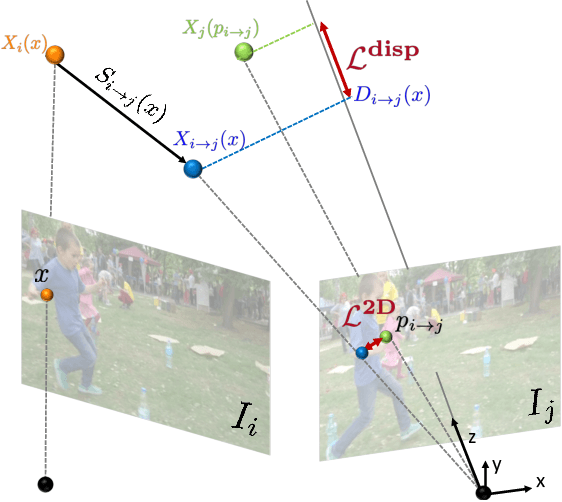
We present a method to estimate depth of a dynamic scene, containing arbitrary moving objects, from an ordinary video captured with a moving camera. We seek a geometrically and temporally consistent solution to this underconstrained problem: the depth predictions of corresponding points across frames should induce plausible, smooth motion in 3D. We formulate this objective in a new test-time training framework where a depth-prediction CNN is trained in tandem with an auxiliary scene-flow prediction MLP over the entire input video. By recursively unrolling the scene-flow prediction MLP over varying time steps, we compute both short-range scene flow to impose local smooth motion priors directly in 3D, and long-range scene flow to impose multi-view consistency constraints with wide baselines. We demonstrate accurate and temporally coherent results on a variety of challenging videos containing diverse moving objects (pets, people, cars), as well as camera motion. Our depth maps give rise to a number of depth-and-motion aware video editing effects such as object and lighting insertion.
* Published at SIGGRAPH 2021
Editing Conditional Radiance Fields
Jun 04, 2021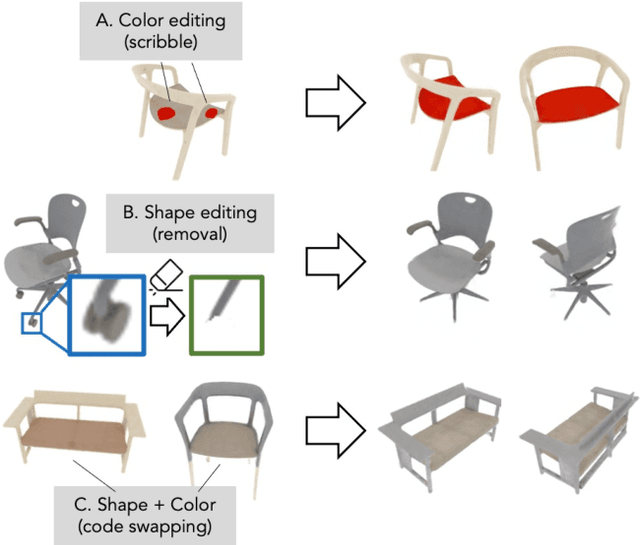

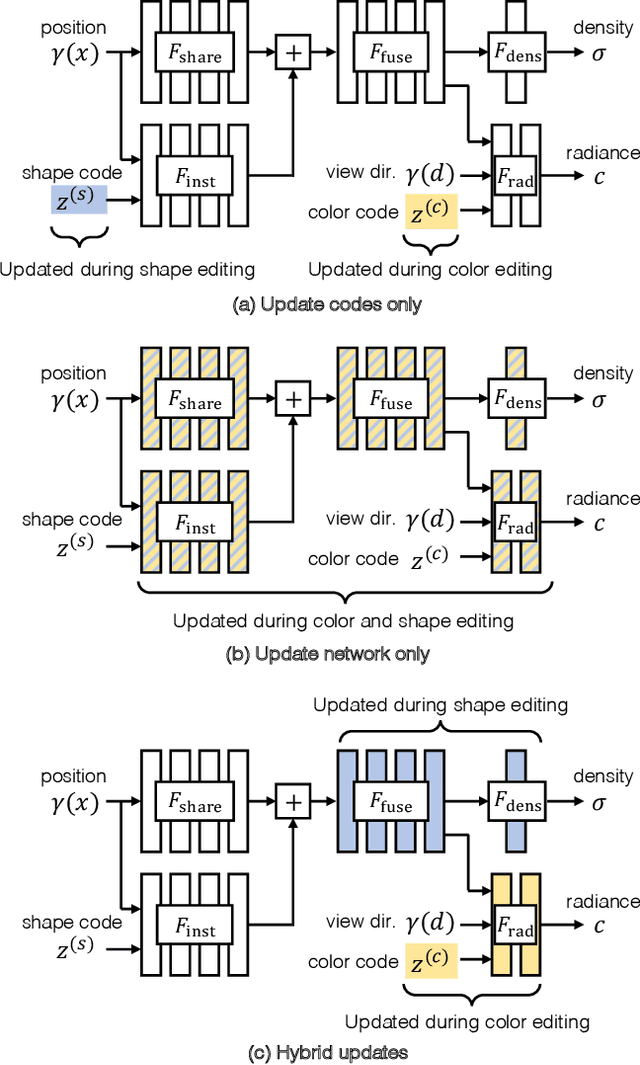

A neural radiance field (NeRF) is a scene model supporting high-quality view synthesis, optimized per scene. In this paper, we explore enabling user editing of a category-level NeRF - also known as a conditional radiance field - trained on a shape category. Specifically, we introduce a method for propagating coarse 2D user scribbles to the 3D space, to modify the color or shape of a local region. First, we propose a conditional radiance field that incorporates new modular network components, including a shape branch that is shared across object instances. Observing multiple instances of the same category, our model learns underlying part semantics without any supervision, thereby allowing the propagation of coarse 2D user scribbles to the entire 3D region (e.g., chair seat). Next, we propose a hybrid network update strategy that targets specific network components, which balances efficiency and accuracy. During user interaction, we formulate an optimization problem that both satisfies the user's constraints and preserves the original object structure. We demonstrate our approach on various editing tasks over three shape datasets and show that it outperforms prior neural editing approaches. Finally, we edit the appearance and shape of a real photograph and show that the edit propagates to extrapolated novel views.
End-to-End Optimization of Scene Layout
Jul 23, 2020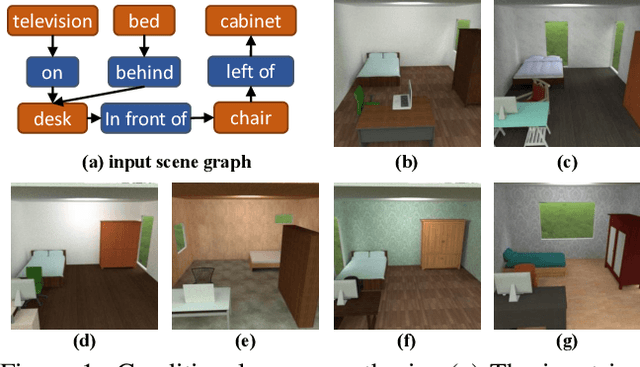
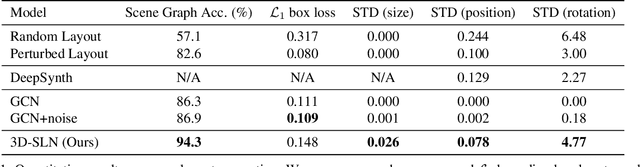
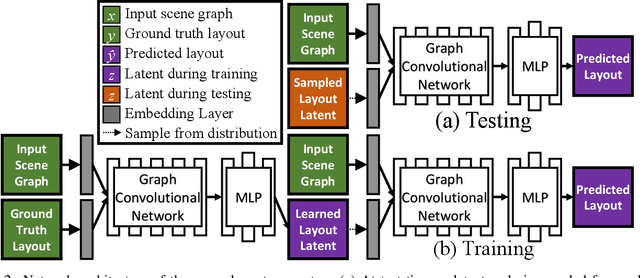
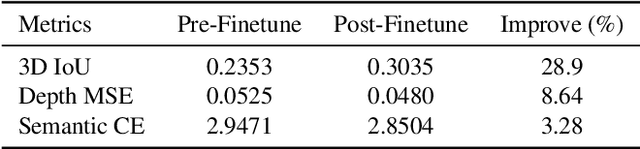
We propose an end-to-end variational generative model for scene layout synthesis conditioned on scene graphs. Unlike unconditional scene layout generation, we use scene graphs as an abstract but general representation to guide the synthesis of diverse scene layouts that satisfy relationships included in the scene graph. This gives rise to more flexible control over the synthesis process, allowing various forms of inputs such as scene layouts extracted from sentences or inferred from a single color image. Using our conditional layout synthesizer, we can generate various layouts that share the same structure of the input example. In addition to this conditional generation design, we also integrate a differentiable rendering module that enables layout refinement using only 2D projections of the scene. Given a depth and a semantics map, the differentiable rendering module enables optimizing over the synthesized layout to fit the given input in an analysis-by-synthesis fashion. Experiments suggest that our model achieves higher accuracy and diversity in conditional scene synthesis and allows exemplar-based scene generation from various input forms.