 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
Sep 27, 2021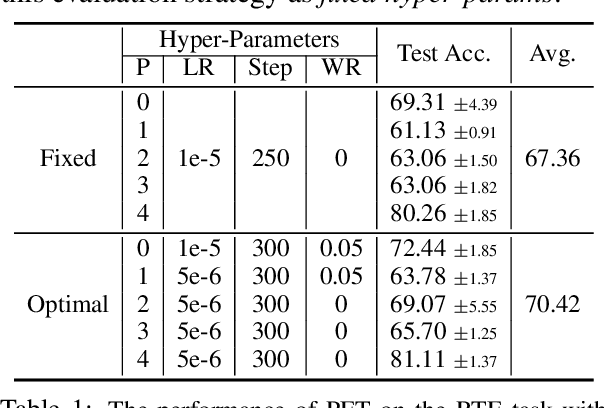
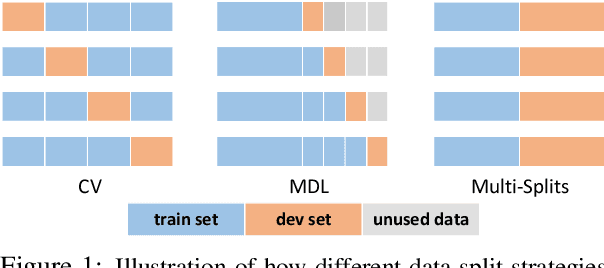
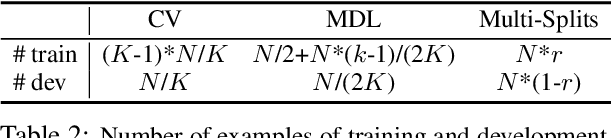
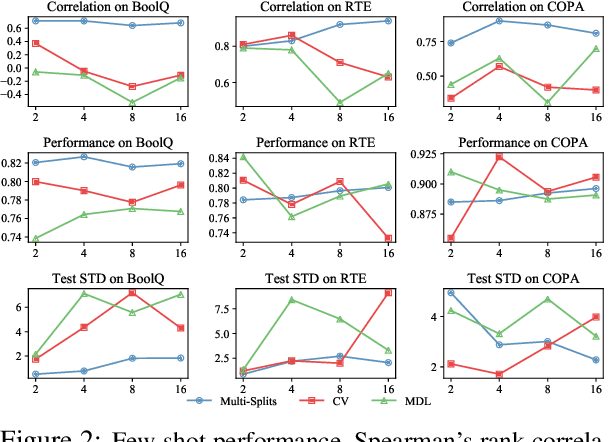
The few-shot natural language understanding (NLU) task has attracted much recent attention. However, prior methods have been evaluated under a disparate set of protocols, which hinders fair comparison and measuring progress of the field. To address this issue, we introduce an evaluation framework that improves previous evaluation procedures in three key aspects, i.e., test performance, dev-test correlation, and stability. Under this new evaluation framework, we re-evaluate several state-of-the-art few-shot methods for NLU tasks. Our framework reveals new insights: (1) both the absolute performance and relative gap of the methods were not accurately estimated in prior literature; (2) no single method dominates most tasks with consistent performance; (3) improvements of some methods diminish with a larger pretrained model; and (4) gains from different methods are often complementary and the best combined model performs close to a strong fully-supervised baseline. We open-source our toolkit, FewNLU, that implements our evaluation framework along with a number of state-of-the-art methods.
FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning
Aug 13, 2021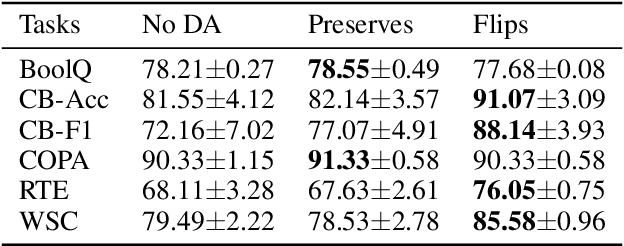
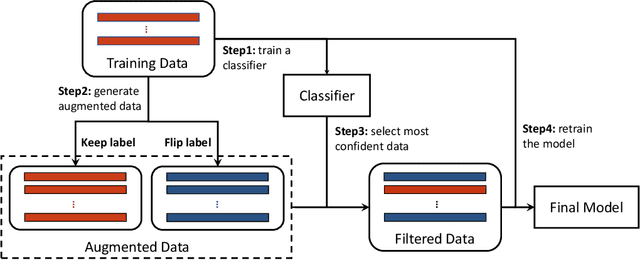

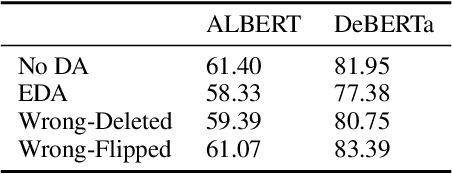
Most previous methods for text data augmentation are limited to simple tasks and weak baselines. We explore data augmentation on hard tasks (i.e., few-shot natural language understanding) and strong baselines (i.e., pretrained models with over one billion parameters). Under this setting, we reproduced a large number of previous augmentation methods and found that these methods bring marginal gains at best and sometimes degrade the performance much. To address this challenge, we propose a novel data augmentation method FlipDA that jointly uses a generative model and a classifier to generate label-flipped data. Central to the idea of FlipDA is the discovery that generating label-flipped data is more crucial to the performance than generating label-preserved data. Experiments show that FlipDA achieves a good tradeoff between effectiveness and robustness---it substantially improves many tasks while not negatively affecting the others.
Distribution Matching for Rationalization
Jun 01, 2021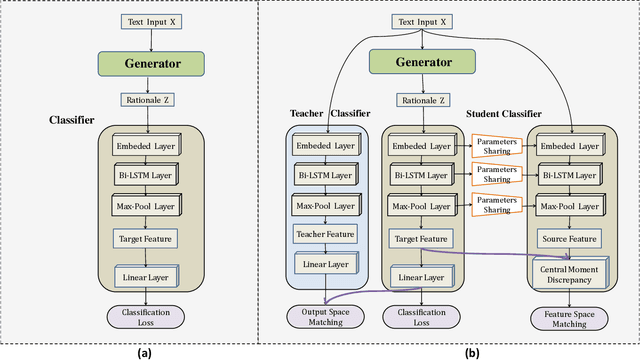
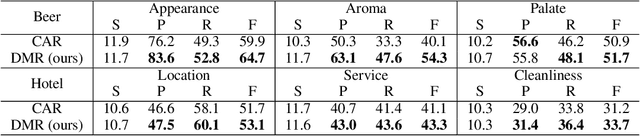
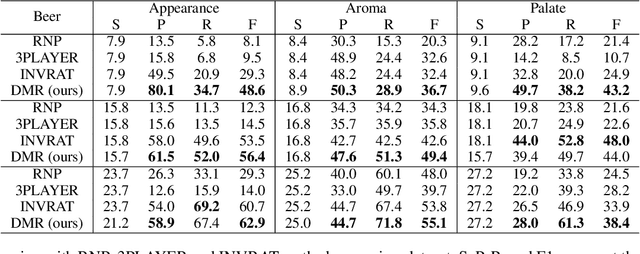
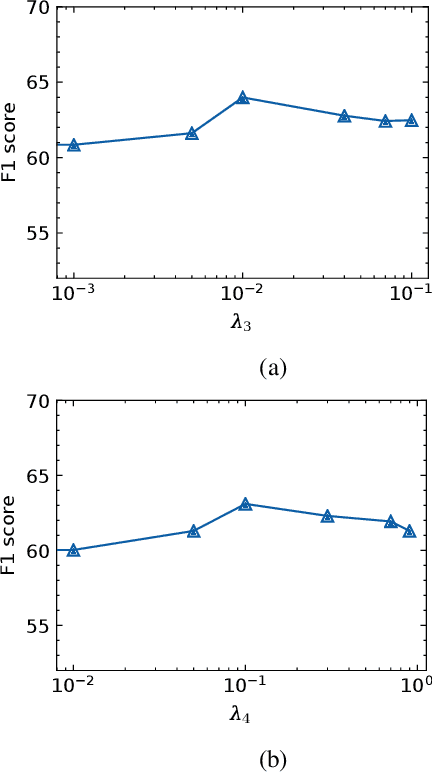
The task of rationalization aims to extract pieces of input text as rationales to justify neural network predictions on text classification tasks. By definition, rationales represent key text pieces used for prediction and thus should have similar classification feature distribution compared to the original input text. However, previous methods mainly focused on maximizing the mutual information between rationales and labels while neglecting the relationship between rationales and input text. To address this issue, we propose a novel rationalization method that matches the distributions of rationales and input text in both the feature space and output space. Empirically, the proposed distribution matching approach consistently outperforms previous methods by a large margin. Our data and code are available.
* Accepted by AAAI2021
VeniBot: Towards Autonomous Venipuncture with Automatic Puncture Area and Angle Regression from NIR Images
May 27, 2021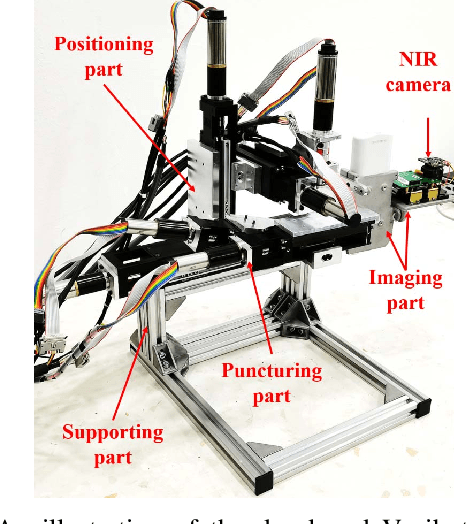
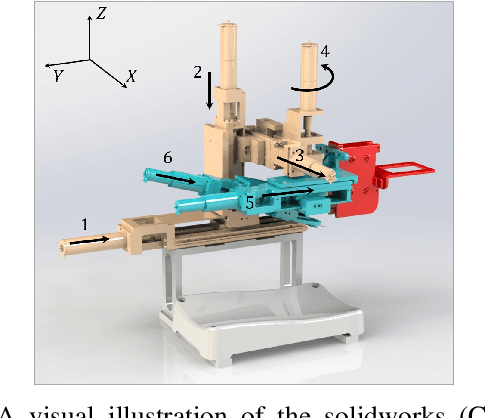
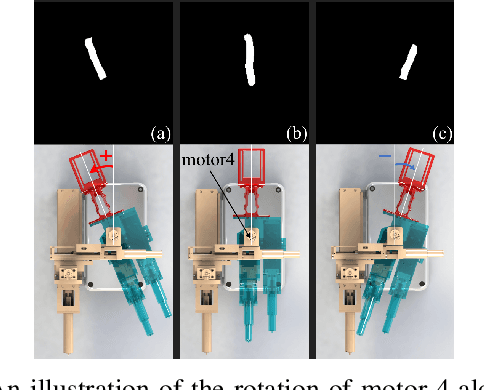
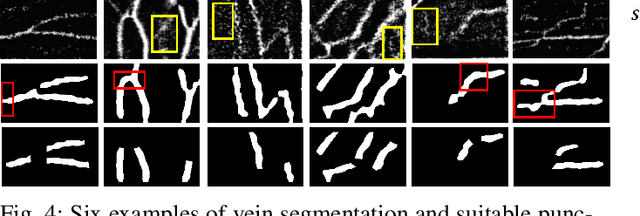
Venipucture is a common step in clinical scenarios, and is with highly practical value to be automated with robotics. Nowadays, only a few on-shelf robotic systems are developed, however, they can not fulfill practical usage due to varied reasons. In this paper, we develop a compact venipucture robot -- VeniBot, with four parts, six motors and two imaging devices. For the automation, we focus on the positioning part and propose a Dual-In-Dual-Out network based on two-step learning and two-task learning, which can achieve fully automatic regression of the suitable puncture area and angle from near-infrared(NIR) images. The regressed suitable puncture area and angle can further navigate the positioning part of VeniBot, which is an important step towards a fully autonomous venipucture robot. Validation on 30 VeniBot-collected volunteers shows a high mean dice coefficient(DSC) of 0.7634 and a low angle error of 15.58{\deg} on suitable puncture area and angle regression respectively, indicating its potentially wide and practical application in the future.
FastMoE: A Fast Mixture-of-Expert Training System
Mar 24, 2021



Mixture-of-Expert (MoE) presents a strong potential in enlarging the size of language model to trillions of parameters. However, training trillion-scale MoE requires algorithm and system co-design for a well-tuned high performance distributed training system. Unfortunately, the only existing platform that meets the requirements strongly depends on Google's hardware (TPU) and software (Mesh Tensorflow) stack, and is not open and available to the public, especially GPU and PyTorch communities. In this paper, we present FastMoE, a distributed MoE training system based on PyTorch with common accelerators. The system provides a hierarchical interface for both flexible model design and easy adaption to different applications, such as Transformer-XL and Megatron-LM. Different from direct implementation of MoE models using PyTorch, the training speed is highly optimized in FastMoE by sophisticated high-performance acceleration skills. The system supports placing different experts on multiple GPUs across multiple nodes, enabling enlarging the number of experts linearly against the number of GPUs. The source of FastMoE is available at https://github.com/laekov/fastmoe under Apache-2 license.
Controllable Generation from Pre-trained Language Models via Inverse Prompting
Mar 19, 2021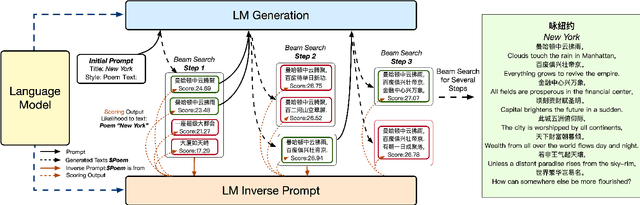
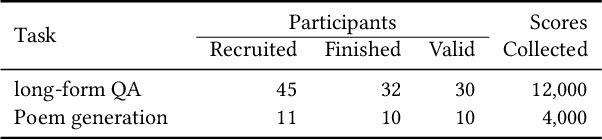

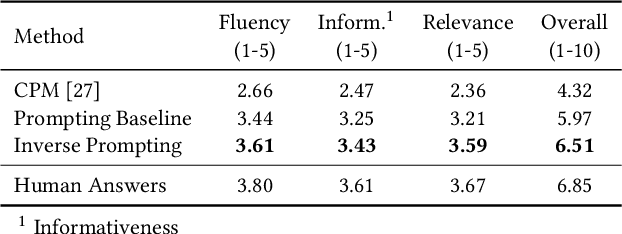
Large-scale pre-trained language models have demonstrated strong capabilities of generating realistic text. However, it remains challenging to control the generation results. Previous approaches such as prompting are far from sufficient, which limits the usage of language models. To tackle this challenge, we propose an innovative method, inverse prompting, to better control text generation. The core idea of inverse prompting is to use generated text to inversely predict the prompt during beam search, which enhances the relevance between the prompt and the generated text and provides better controllability. Empirically, we pre-train a large-scale Chinese language model to perform a systematic study using human evaluation on the tasks of open-domain poem generation and open-domain long-form question answering. Our results show that our proposed method substantially outperforms the baselines and that our generation quality is close to human performance on some of the tasks. Narrators can try our poem generation demo at https://pretrain.aminer.cn/apps/poetry.html, while our QA demo can be found at https://pretrain.aminer.cn/app/qa. For researchers, the code is provided in https://github.com/THUDM/InversePrompting.
GPT Understands, Too
Mar 18, 2021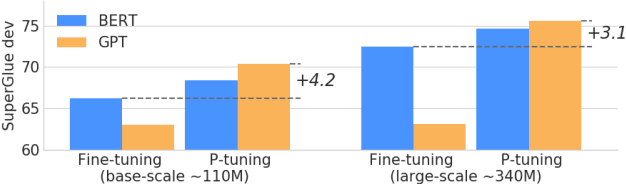

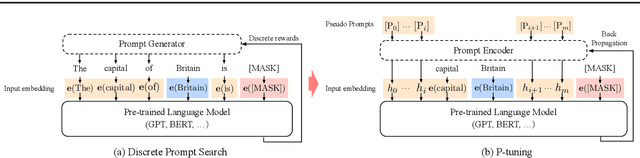

While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning -- which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64\% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, we find that P-tuning also improves BERTs' performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.
All NLP Tasks Are Generation Tasks: A General Pretraining Framework
Mar 18, 2021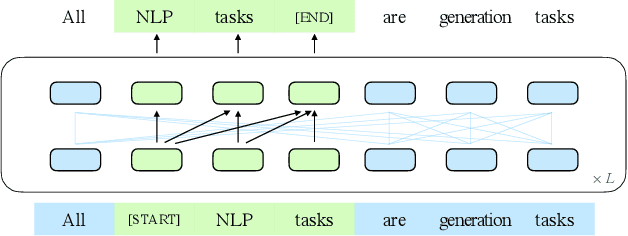
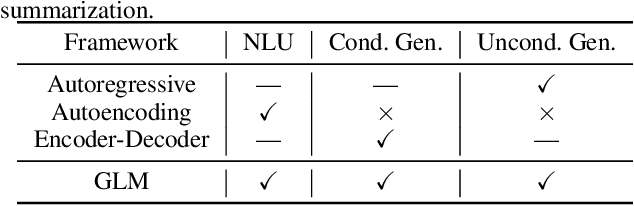
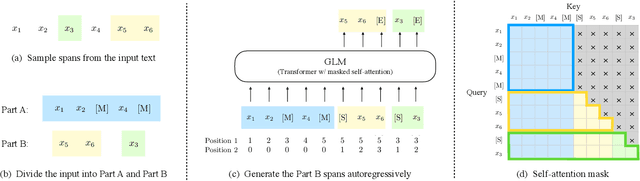
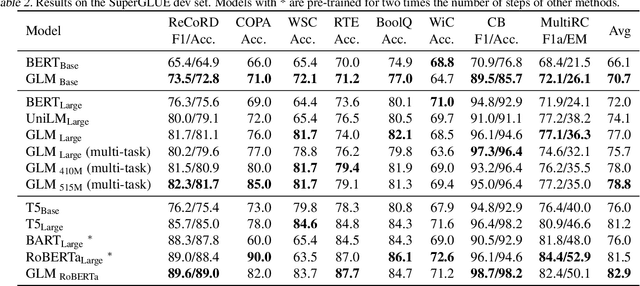
There have been various types of pretraining architectures including autoregressive models (e.g., GPT), autoencoding models (e.g., BERT), and encoder-decoder models (e.g., T5). On the other hand, NLP tasks are different in nature, with three main categories being classification, unconditional generation, and conditional generation. However, none of the pretraining frameworks performs the best for all tasks, which introduces inconvenience for model development and selection. We propose a novel pretraining framework GLM (General Language Model) to address this challenge. Compared to previous work, our architecture has three major benefits: (1) it performs well on classification, unconditional generation, and conditional generation tasks with one single pretrained model; (2) it outperforms BERT-like models on classification due to improved pretrain-finetune consistency; (3) it naturally handles variable-length blank filling which is crucial for many downstream tasks. Empirically, GLM substantially outperforms BERT on the SuperGLUE natural language understanding benchmark with the same amount of pre-training data. Moreover, GLM with 1.25x parameters of BERT-Large achieves the best performance in NLU, conditional and unconditional generation at the same time, which demonstrates its generalizability to different downstream tasks.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Jun 19, 2019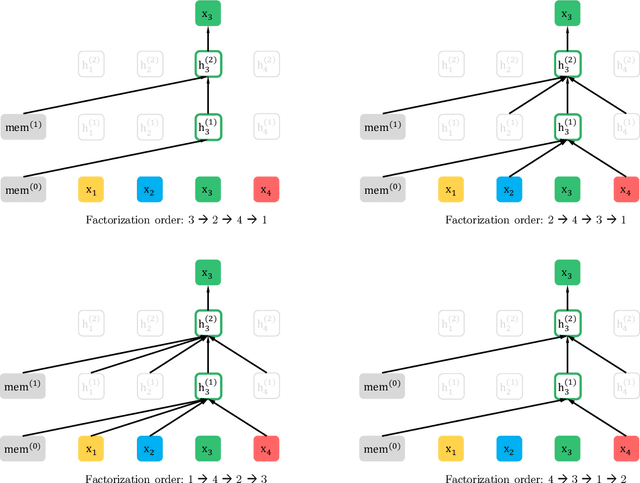
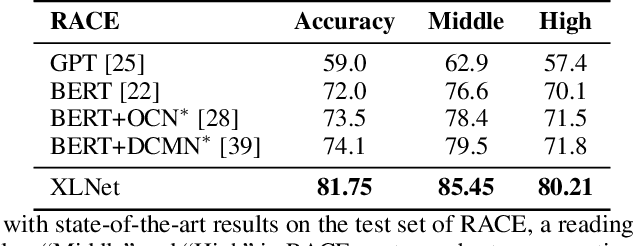
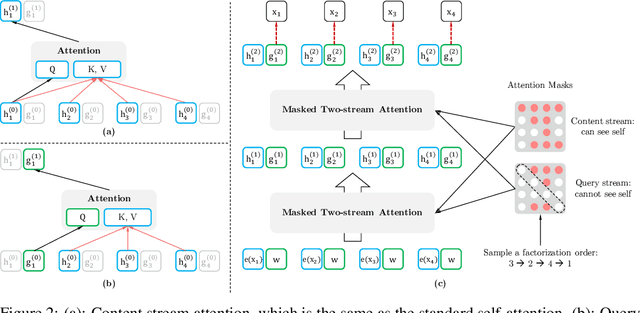

With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, XLNet outperforms BERT on 20 tasks, often by a large margin, and achieves state-of-the-art results on 18 tasks including question answering, natural language inference, sentiment analysis, and document ranking.
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Jan 18, 2019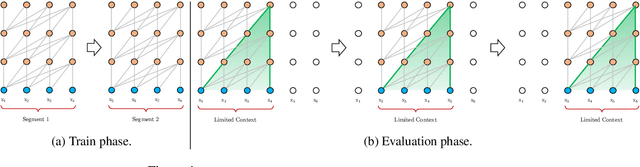
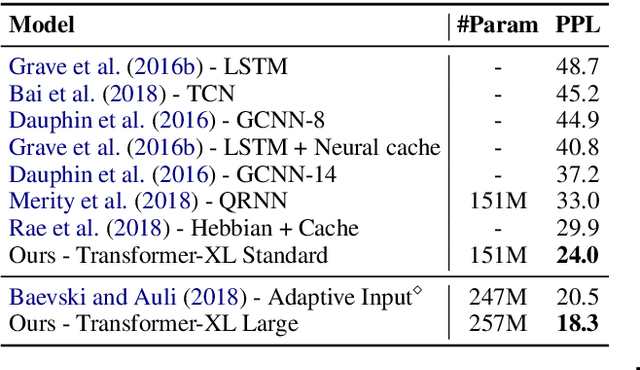
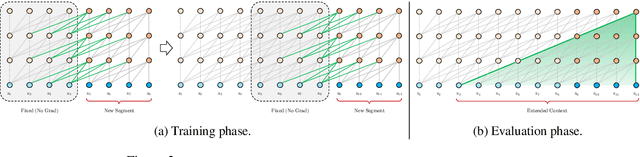
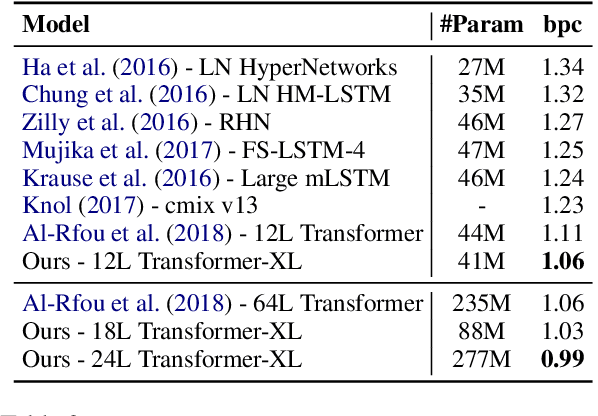
Transformer networks have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling. As a solution, we propose a novel neural architecture, Transformer-XL, that enables Transformer to learn dependency beyond a fixed length without disrupting temporal coherence. Concretely, it consists of a segment-level recurrence mechanism and a novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the problem of context fragmentation. As a result, Transformer-XL learns dependency that is about 80% longer than RNNs and 450% longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+ times faster than vanilla Transformer during evaluation. Additionally, we improve the state-of-the-art (SoTA) results of bpc/perplexity from 1.06 to 0.99 on enwiki8, from 1.13 to 1.08 on text8, from 20.5 to 18.3 on WikiText-103, from 23.7 to 21.8 on One Billion Word, and from 55.3 to 54.5 on Penn Treebank (without finetuning). Our code, pretrained models, and hyperparameters are available in both Tensorflow and PyTorch.