 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic-Channel Coding and Modulation for Token Communications
Nov 19, 2025In recent years, the Transformer architecture has achieved outstanding performance across a wide range of tasks and modalities. Token is the unified input and output representation in Transformer-based models, which has become a fundamental information unit. In this work, we consider the problem of token communication, studying how to transmit tokens efficiently and reliably. Point cloud, a prevailing three-dimensional format which exhibits a more complex spatial structure compared to image or video, is chosen to be the information source. We utilize the set abstraction method to obtain point tokens. Subsequently, to get a more informative and transmission-friendly representation based on tokens, we propose a joint semantic-channel and modulation (JSCCM) scheme for the token encoder, mapping point tokens to standard digital constellation points (modulated tokens). Specifically, the JSCCM consists of two parallel Point Transformer-based encoders and a differential modulator which combines the Gumel-softmax and soft quantization methods. Besides, the rate allocator and channel adapter are developed, facilitating adaptive generation of high-quality modulated tokens conditioned on both semantic information and channel conditions. Extensive simulations demonstrate that the proposed method outperforms both joint semantic-channel coding and traditional separate coding, achieving over 1dB gain in reconstruction and more than 6x compression ratio in modulated symbols.
Multi-Task Semantic Communications via Large Models
Mar 28, 2025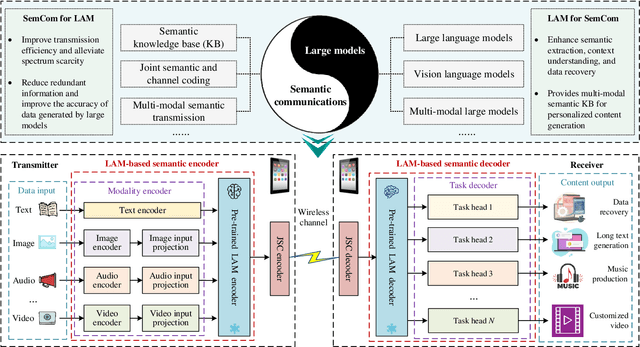
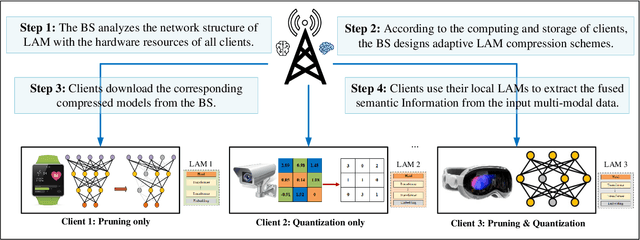
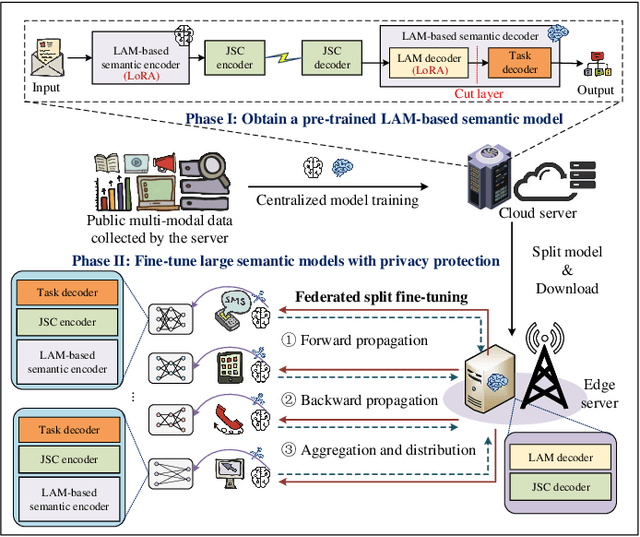
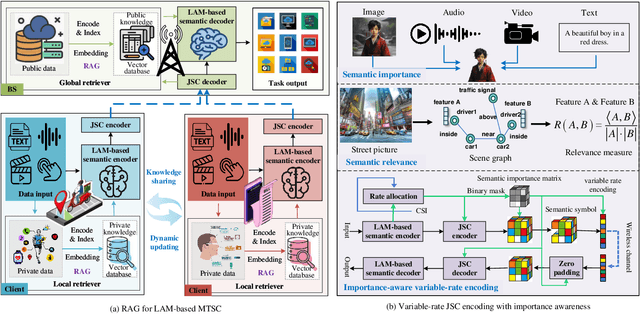
Artificial intelligence (AI) promises to revolutionize the design, optimization and management of next-generation communication systems. In this article, we explore the integration of large AI models (LAMs) into semantic communications (SemCom) by leveraging their multi-modal data processing and generation capabilities. Although LAMs bring unprecedented abilities to extract semantics from raw data, this integration entails multifaceted challenges including high resource demands, model complexity, and the need for adaptability across diverse modalities and tasks. To overcome these challenges, we propose a LAM-based multi-task SemCom (MTSC) architecture, which includes an adaptive model compression strategy and a federated split fine-tuning approach to facilitate the efficient deployment of LAM-based semantic models in resource-limited networks. Furthermore, a retrieval-augmented generation scheme is implemented to synthesize the most recent local and global knowledge bases to enhance the accuracy of semantic extraction and content generation, thereby improving the inference performance. Finally, simulation results demonstrate the efficacy of the proposed LAM-based MTSC architecture, highlighting the performance enhancements across various downstream tasks under varying channel conditions.
SpikACom: A Neuromorphic Computing Framework for Green Communications
Feb 24, 2025The ever-growing power consumption of wireless communication systems necessitates more energy-efficient algorithms. This paper introduces SpikACom ({Spik}ing {A}daptive {Com}munication), a neuromorphic computing-based framework for power-intensive wireless communication tasks. SpikACom leverages brain-inspired spiking neural networks (SNNs) for efficient signal processing. It is designed for dynamic wireless environments, helping to mitigate catastrophic forgetting and facilitate adaptation to new circumstances. Moreover, SpikACom is customizable, allowing flexibly integration of domain knowledge to enhance it interpretability and efficacy. We validate its performance on fundamental wireless communication tasks, including task-oriented semantic communication, multiple-input multiple-output (MIMO) beamforming, and orthogonal frequency-division multiplexing (OFDM) channel estimation. The simulation results show that SpikACom significantly reduces power consumption while matching or exceeding the performance of conventional algorithms. This study highlights the potential of SNNs for enabling greener and smarter wireless communication systems.
Adaptive Sampling and Joint Semantic-Channel Coding under Dynamic Channel Environment
Feb 11, 2025Deep learning enabled semantic communications are attracting extensive attention. However, most works normally ignore the data acquisition process and suffer from robustness issues under dynamic channel environment. In this paper, we propose an adaptive joint sampling-semantic-channel coding (Adaptive-JSSCC) framework. Specifically, we propose a semantic-aware sampling and reconstruction method to optimize the number of samples dynamically for each region of the images. According to semantic significance, we optimize sampling matrices for each region of the most individually and obtain a semantic sampling ratio distribution map shared with the receiver. Through the guidance of the map, high-quality reconstruction is achieved. Meanwhile, attention-based channel adaptive module (ACAM) is designed to overcome the neural network model mismatch between the training and testing channel environment during sampling-reconstruction and encoding-decoding. To this end, signal-to-noise ratio (SNR) is employed as an extra parameter input to integrate and reorganize intermediate characteristics. Simulation results show that the proposed Adaptive-JSSCC effectively reduces the amount of data acquisition without degrading the reconstruction performance in comparison to the state-of-the-art, and it is highly adaptable and adjustable to dynamic channel environments.
On Privacy, Security, and Trustworthiness in Distributed Wireless Large AI Models (WLAM)
Dec 04, 2024



Combining wireless communication with large artificial intelligence (AI) models can open up a myriad of novel application scenarios. In sixth generation (6G) networks, ubiquitous communication and computing resources allow large AI models to serve democratic large AI models-related services to enable real-time applications like autonomous vehicles, smart cities, and Internet of Things (IoT) ecosystems. However, the security considerations and sustainable communication resources limit the deployment of large AI models over distributed wireless networks. This paper provides a comprehensive overview of privacy, security, and trustworthy for distributed wireless large AI model (WLAM). In particular, a detailed privacy and security are analysis for distributed WLAM is fist revealed. The classifications and theoretical findings about privacy and security in distributed WLAM are discussed. Then the trustworthy and ethics for implementing distributed WLAM are described. Finally, the comprehensive applications of distributed WLAM are presented in the context of electromagnetic signal processing.
On the Privacy, Security, and Trustworthy for Distributed Wireless Large AI Model (WLAM)
Dec 03, 2024Combining wireless communication with large artificial intelligence (AI) models can open up a myriad of novel application scenarios. In sixth generation (6G) networks, ubiquitous communication and computing resources allow large AI models to serve democratic large AI models-related services to enable real-time applications like autonomous vehicles, smart cities, and Internet of Things (IoT) ecosystems. However, the security considerations and sustainable communication resources limit the deployment of large AI models over distributed wireless networks. This paper provides a comprehensive overview of privacy, security, and trustworthy for distributed wireless large AI model (WLAM). In particular, the detailed privacy and security are analysis for distributed WLAM is fist revealed. The classifications and theoretical findings about privacy and security in distributed WLAM are discussed. Then the trustworthy and ethics for implementing distributed WLAM are described. Finally, the comprehensive applications of distributed WLAM is provided in the aspect of electromagnetic signal processing.
IRS-Enhanced Secure Semantic Communication Networks: Cross-Layer and Context-Awared Resource Allocation
Nov 04, 2024



Learning-task oriented semantic communication is pivotal in optimizing transmission efficiency by extracting and conveying essential semantics tailored to specific tasks, such as image reconstruction and classification. Nevertheless, the challenge of eavesdropping poses a formidable threat to semantic privacy due to the open nature of wireless communications. In this paper, intelligent reflective surface (IRS)-enhanced secure semantic communication (IRS-SSC) is proposed to guarantee the physical layer security from a task-oriented semantic perspective. Specifically, a multi-layer codebook is exploited to discretize continuous semantic features and describe semantics with different numbers of bits, thereby meeting the need for hierarchical semantic representation and further enhancing the transmission efficiency. Novel semantic security metrics, i.e., secure semantic rate (S-SR) and secure semantic spectrum efficiency (S-SSE), are defined to map the task-oriented security requirements at the application layer into the physical layer. To achieve artificial intelligence (AI)-native secure communication, we propose a noise disturbance enhanced hybrid deep reinforcement learning (NdeHDRL)-based resource allocation scheme. This scheme dynamically maximizes the S-SSE by jointly optimizing the bits for semantic representations, reflective coefficients of the IRS, and the subchannel assignment. Moreover, we propose a novel semantic context awared state space (SCA-SS) to fusion the high-dimensional semantic space and the observable system state space, which enables the agent to perceive semantic context and solves the dimensional catastrophe problem. Simulation results demonstrate the efficiency of our proposed schemes in both enhancing the security performance and the S-SSE compared to several benchmark schemes.
Synchronous Multi-modal Semantic CommunicationSystem with Packet-level Coding
Aug 08, 2024



Although the semantic communication with joint semantic-channel coding design has shown promising performance in transmitting data of different modalities over physical layer channels, the synchronization and packet-level forward error correction of multimodal semantics have not been well studied. Due to the independent design of semantic encoders, synchronizing multimodal features in both the semantic and time domains is a challenging problem. In this paper, we take the facial video and speech transmission as an example and propose a Synchronous Multimodal Semantic Communication System (SyncSC) with Packet-Level Coding. To achieve semantic and time synchronization, 3D Morphable Mode (3DMM) coefficients and text are transmitted as semantics, and we propose a semantic codec that achieves similar quality of reconstruction and synchronization with lower bandwidth, compared to traditional methods. To protect semantic packets under the erasure channel, we propose a packet-Level Forward Error Correction (FEC) method, called PacSC, that maintains a certain visual quality performance even at high packet loss rates. Particularly, for text packets, a text packet loss concealment module, called TextPC, based on Bidirectional Encoder Representations from Transformers (BERT) is proposed, which significantly improves the performance of traditional FEC methods. The simulation results show that our proposed SyncSC reduce transmission overhead and achieve high-quality synchronous transmission of video and speech over the packet loss network.
A Secure and Efficient Distributed Semantic Communication System for Heterogeneous Internet of Things Devices
Jul 19, 2024Semantic communications have emerged as a promising solution to address the challenge of efficient communication in rapidly evolving and increasingly complex Internet of Things (IoT) networks. However, protecting the security of semantic communication systems within the distributed and heterogeneous IoT networks is critical issues that need to be addressed. We develop a secure and efficient distributed semantic communication system in IoT scenarios, focusing on three aspects: secure system maintenance, efficient system update, and privacy-preserving system usage. Firstly, we propose a blockchain-based interaction framework that ensures the integrity, authentication, and availability of interactions among IoT devices to securely maintain system. This framework includes a novel digital signature verification mechanism designed for semantic communications, enabling secure and efficient interactions with semantic communications. Secondly, to improve the efficiency of interactions, we develop a flexible semantic communication scheme that leverages compressed semantic knowledge bases. This scheme reduces the data exchange required for system update and is adapt to dynamic task requirements and the diversity of device capabilities. Thirdly, we exploit the integration of differential privacy into semantic communications. We analyze the implementation of differential privacy taking into account the lossy nature of semantic communications and wireless channel distortions. An joint model-channel noise mechanism is introduced to achieve differential privacy preservation in semantic communications without compromising the system's functionality. Experiments show that the system is able to achieve integrity, availability, efficiency and the preservation of privacy.
Hybrid Digital-Analog Semantic Communications
May 21, 2024



Digital and analog semantic communications (SemCom) face inherent limitations such as data security concerns in analog SemCom, as well as leveling-off and cliff-edge effects in digital SemCom. In order to overcome these challenges, we propose a novel SemCom framework and a corresponding system called HDA-DeepSC, which leverages a hybrid digital-analog approach for multimedia transmission. This is achieved through the introduction of digital-analog allocation and fusion modules. To strike a balance between data rate and distortion, we design new loss functions that take into account long-distance dependencies in the semantic distortion constraint, essential information recovery in the channel distortion constraint, and optimal bit stream generation in the rate constraint. Additionally, we propose denoising diffusion-based signal detection techniques, which involve carefully designed variance schedules and sampling algorithms to refine transmitted signals. Through extensive numerical experiments, we will demonstrate that HDA-DeepSC exhibits robustness to channel variations and is capable of supporting various communication scenarios. Our proposed framework outperforms existing benchmarks in terms of peak signal-to-noise ratio and multi-scale structural similarity, showcasing its superiority in semantic communication quality.