 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG2DP: Diffusion Planning with Spatio-Temporal Grid Guidance
Jun 25, 2026In autonomous driving, diffusion-based planners have emerged as a promising paradigm for robust motion planning in dense and interactive traffic, as they can effectively model diverse driving behaviors. However, their inherent stochasticity often requires explicit guidance during denoising to ensure safety and route adherence for robust closed-loop execution. Existing guidance typically relies on sparse, entity-centric geometric queries or post-hoc refinement, yielding limited situational awareness and fragile performance in interactive scenes. To address this issue, we propose G2DP (Grid-Guided Diffusion Planning), a diffusion-based planner that directly enforces dense environmental constraints through inference-time guidance. Specifically, G2DP constructs a differentiable spatio-temporal cost volume by fusing probabilistic future occupancy distributions with a route-progress map. By formulating this volume as a continuous safety energy functional, it injects dense gradients directly into the denoising loop, actively steering trajectory generation toward collision-free and progress-optimal regions. Extensive closed-loop evaluations show that G2DP achieves state-of-the-art performance on nuPlan, outperforming the strongest imitation-learning baseline by +7.2 points in reactive score. It further maintains top scores in zero-shot transfers to interPlan and DeepScenario benchmarks, with collision avoidance improving by +10.15 over the unguided approach on interPlan. These results demonstrate that spatio-temporal cost grids serve as an effective representation for robust guidance in diffusion-based planning.
A specialized reasoning large language model for accelerating rare disease diagnosis: a randomized AI physician assistance trial
Jun 23, 2026Rare diseases affect millions of individuals worldwide, yet timely diagnosis remains a major public health challenge due to scarcity of specialized clinical expertise. While large language models (LLMs) show promise to support rare disease diagnosis, current models are constrained by insufficient clinical deployability, limited clinically grounded evidence, and scarcity of training data. Here we present RaDaR (Rare Disease navigatoR), an open-source, compact reasoning LLM (32B parameters) for rare disease diagnosis. RaDaR was trained with 49,170 publicly available free-text cases and 104,666 synthetic cases with reasoning-enhanced training. RaDaR showed the strongest performance among evaluated open-source models, including the 671B DeepSeek-R1, across public benchmarks and four external validation centers. In a retrospective cohort, RaDaR prioritized the final diagnosis before documented clinical suspicion in 61.06 percent of cases, corresponding to a potential lead time of 1.87 months and 50.18 percent of the within-center interval. In a randomized physician-assistance trial, RaDaR assistance improved physicians' rare-disease diagnostic accuracy by 21.44 percentage points compared with internet search alone. Synthetic-data ablations suggested that phenotype-anchored narratives provide useful training signal for long-tail rare diseases, with a monotonic scaling trend within the tested data range. Together, RaDaR and its development and validation framework provide a deployable rare-disease reasoning model and a reproducible development framework for diagnostic AI under data scarcity.
MemSlides: A Hierarchical Memory Driven Agent Framework for Personalized Slide Generation with Multi-turn Local Revision
Jun 15, 2026Personalized presentation generation requires more than conditioning on a current prompt or template: agents must preserve stable user preferences across tasks, retain newly introduced preferences and constraints during multi-turn revision, and carry out local edits reliably. We propose MemSlides, a hierarchical memory framework for personalized presentation agents that separates long-term memory from working memory and further divides long-term memory into user profile memory and tool memory. User profile memory stores intent-conditioned profiles for round-0 personalization, working memory carries active preferences and session constraints across revision rounds, and tool memory stores reusable execution experience for reliable localized editing. MemSlides pairs this memory design with scoped slide-local revision, so targeted updates act on the smallest affected region instead of repeatedly regenerating the full deck. In controlled experiments, user profile memory improves persona-alignment judgments on a multi-persona, multi-intent profile bank, tool-memory injection improves closed-loop modify behavior in diagnostic matched-pair settings, and qualitative cases illustrate working memory's ability to carryover preferences. Taken together, these results suggest that effective personalization in presentation authoring depends on separating persistent user profiles, session-level working memory, and reusable execution experience across generation and localized revision.
Co-Director: Agentic Generative Video Storytelling
Apr 27, 2026While diffusion models generate high-fidelity video clips, transforming them into coherent storytelling engines remains challenging. Current agentic pipelines automate this via chained modules but suffer from semantic drift and cascading failures due to independent, handcrafted prompting. We present Co-Director, a hierarchical multi-agent framework formalizing video storytelling as a global optimization problem. To ensure semantic coherence, we introduce hierarchical parameterization: a multi-armed bandit globally identifies promising creative directions, while a local multimodal self-refinement loop mitigates identity drift and ensures sequence-level consistency. This balances the exploration of novel narrative strategies with the exploitation of effective creative configurations. For evaluation, we introduce GenAD-Bench, a 400-scenario dataset of fictional products for personalized advertising. Experiments demonstrate that Co-Director significantly outperforms state-of-the-art baselines, offering a principled approach that seamlessly generalizes to broader cinematic narratives. Project Page: https://co-director-agent.github.io/
RareAgents: Autonomous Multi-disciplinary Team for Rare Disease Diagnosis and Treatment
Dec 17, 2024



Rare diseases, despite their low individual incidence, collectively impact around 300 million people worldwide due to the huge number of diseases. The complexity of symptoms and the shortage of specialized doctors with relevant experience make diagnosing and treating rare diseases more challenging than common diseases. Recently, agents powered by large language models (LLMs) have demonstrated notable improvements across various domains. In the medical field, some agent methods have outperformed direct prompts in question-answering tasks from medical exams. However, current agent frameworks lack adaptation for real-world clinical scenarios, especially those involving the intricate demands of rare diseases. To address these challenges, we present RareAgents, the first multi-disciplinary team of LLM-based agents tailored to the complex clinical context of rare diseases. RareAgents integrates advanced planning capabilities, memory mechanisms, and medical tools utilization, leveraging Llama-3.1-8B/70B as the base model. Experimental results show that RareAgents surpasses state-of-the-art domain-specific models, GPT-4o, and existing agent frameworks in both differential diagnosis and medication recommendation for rare diseases. Furthermore, we contribute a novel dataset, MIMIC-IV-Ext-Rare, derived from MIMIC-IV, to support further advancements in this field.
DLM-VMTL:A Double Layer Mapper for heterogeneous data video Multi-task prompt learning
Aug 29, 2024



In recent years, the parameters of backbones of Video Understanding tasks continue to increase and even reach billion-level. Whether fine-tuning a specific task on the Video Foundation Model or pre-training the model designed for the specific task, incurs a lot of overhead. How to make these models play other values than their own tasks becomes a worthy question. Multi-Task Learning(MTL) makes the visual task acquire the rich shareable knowledge from other tasks while joint training. It is fully explored in Image Recognition tasks especially dense predict tasks. Nevertheless, it is rarely used in video domain due to the lack of multi-labels video data. In this paper, a heterogenous data video multi-task prompt learning (VMTL) method is proposed to address above problem. It's different from it in image domain, a Double-Layers Mapper(DLM) is proposed to extract the shareable knowledge into visual promptS and align it with representation of primary task. Extensive experiments prove that our DLM-VMTL performs better than baselines on 6 different video understanding tasks and 11 datasets.
Synchronous Multi-modal Semantic CommunicationSystem with Packet-level Coding
Aug 08, 2024



Although the semantic communication with joint semantic-channel coding design has shown promising performance in transmitting data of different modalities over physical layer channels, the synchronization and packet-level forward error correction of multimodal semantics have not been well studied. Due to the independent design of semantic encoders, synchronizing multimodal features in both the semantic and time domains is a challenging problem. In this paper, we take the facial video and speech transmission as an example and propose a Synchronous Multimodal Semantic Communication System (SyncSC) with Packet-Level Coding. To achieve semantic and time synchronization, 3D Morphable Mode (3DMM) coefficients and text are transmitted as semantics, and we propose a semantic codec that achieves similar quality of reconstruction and synchronization with lower bandwidth, compared to traditional methods. To protect semantic packets under the erasure channel, we propose a packet-Level Forward Error Correction (FEC) method, called PacSC, that maintains a certain visual quality performance even at high packet loss rates. Particularly, for text packets, a text packet loss concealment module, called TextPC, based on Bidirectional Encoder Representations from Transformers (BERT) is proposed, which significantly improves the performance of traditional FEC methods. The simulation results show that our proposed SyncSC reduce transmission overhead and achieve high-quality synchronous transmission of video and speech over the packet loss network.
Query Expansion for Patent Searching using Word Embedding and Professional Crowdsourcing
Nov 14, 2019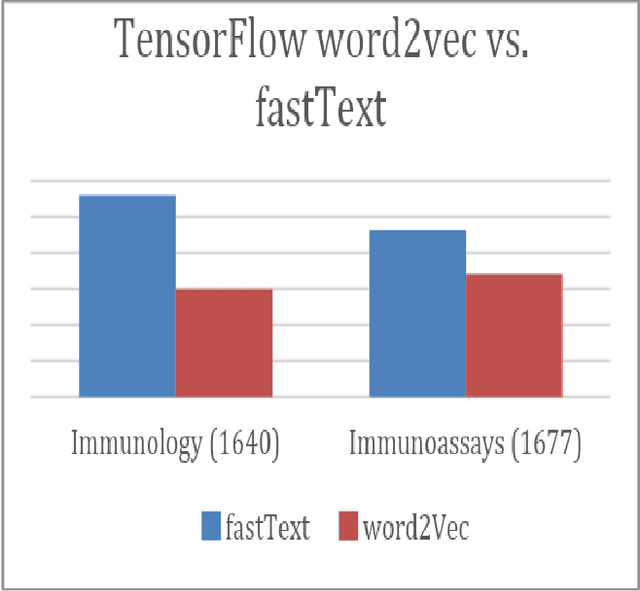
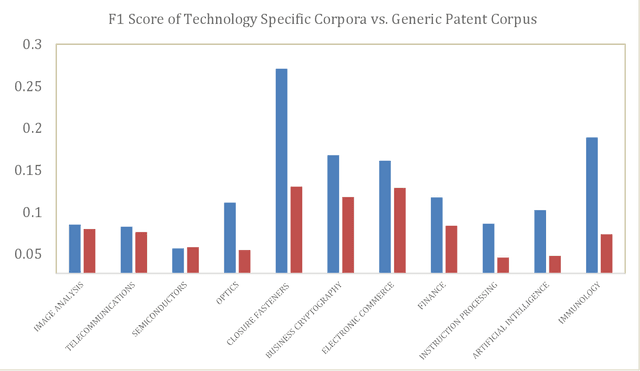
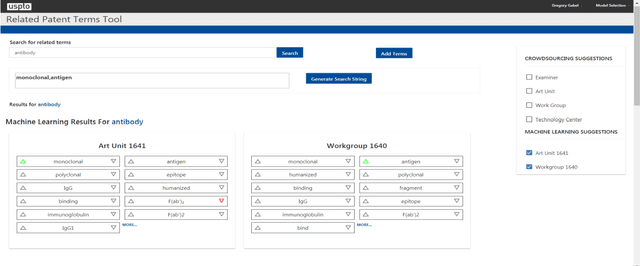
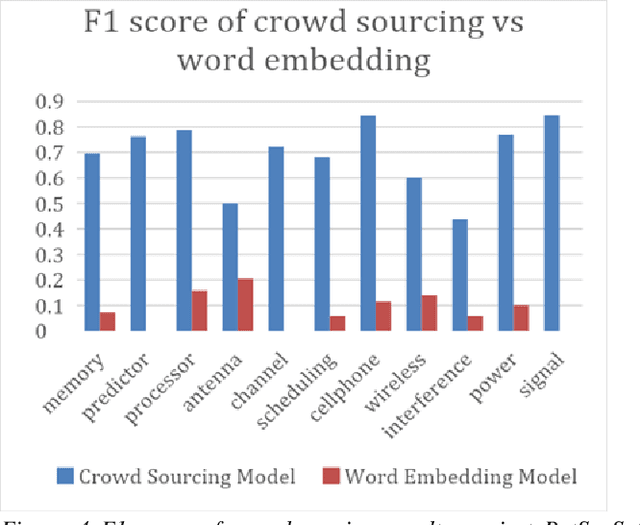
The patent examination process includes a search of previous work to verify that a patent application describes a novel invention. Patent examiners primarily use keyword-based searches to uncover prior art. A critical part of keyword searching is query expansion, which is the process of including alternate terms such as synonyms and other related words, since the same concepts are often described differently in the literature. Patent terminology is often domain specific. By curating technology-specific corpora and training word embedding models based on these corpora, we are able to automatically identify the most relevant expansions of a given word or phrase. We compare the performance of several automated query expansion techniques against expert specified expansions. Furthermore, we explore a novel mechanism to extract related terms not just based on one input term but several terms in conjunction by computing their centroid and identifying the nearest neighbors to this centroid. Highly skilled patent examiners are often the best and most reliable source of identifying related terms. By designing a user interface that allows examiners to interact with the word embedding suggestions, we are able to use these interactions to power crowdsourced modes of related terms. Learning from users allows us to overcome several challenges such as identifying words that are bleeding edge and have not been published in the corpus yet. This paper studies the effectiveness of word embedding and crowdsourced models across 11 disparate technical areas.