 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Wireless Communications: From PHY Intelligence to Network Autonomy
Jun 04, 20266G networks will introduce unprecedented complexity, which calls for a paradigm shift in network optimization and management. Artificial intelligence (AI)-based solutions, especially those enabled by the recently developed foundation models, have been recognized as promising candidates. Foundation models are large-scale AI models with general-purpose feature extraction capabilities, and once trained on massive amounts of data, they can be adapted to solve a wide range of downstream tasks, either in a zero-shot manner or with few-shot fine-tuning. This article provides a comprehensive overview of how foundation models are reshaping physical-layer processing and wireless resource management across three progressive paradigms. First, we examine the adaptation of off-the-shelf pre-trained foundation models to various wireless tasks. Second, we explore wireless-native foundation models, built from scratch on wireless data to bridge cross-domain modality gaps and capture universal wireless-domain physical characteristics. Third, we highlight agentic foundation models, which elevate static data processing into autonomous, reasoning-driven network orchestration. Furthermore, we discuss the impact of applying foundation models to emerging 6G frontiers, including integrated sensing and communications (ISAC), new multiple-input multiple-output (MIMO) architectures, semantic communications, and system-level network autonomy. Finally, we identify critical open challenges and opportunities, charting a promising path toward fully intelligent and adaptive wireless networks.
A Graph Foundation Model for Wireless Resource Allocation
Apr 08, 2026The aggressive densification of modern wireless networks necessitates judicious resource allocation to mitigate severe mutual interference. However, classical iterative algorithms remain computationally prohibitive for real-time applications requiring rapid responsiveness. While recent deep learning-based methods show promise, they typically function as task-specific solvers lacking the flexibility to adapt to different objectives and scenarios without expensive retraining. To address these limitations, we propose a graph foundation model for resource allocation (GFM-RA) based on a pre-training and fine-tuning paradigm to extract unified representations, thereby enabling rapid adaptation to different objectives and scenarios. Specifically, we introduce an interference-aware Transformer architecture with a bias projector that injects interference topologies into global attention mechanisms. Furthermore, we develop a hybrid self-supervised pre-training strategy that synergizes masked edge prediction with negative-free Teacher-Student contrastive learning, enabling the model to capture transferable structural representations from massive unlabeled datasets. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art performance and scales effectively with increased model capacity. Crucially, leveraging its unified representations, the foundation model exhibits exceptional sample efficiency, enabling robust few-shot adaptation to diverse and unsupervised downstream objectives in out-of-distribution (OOD) scenarios. These results demonstrate the promise of pre-trained foundation models for adaptable wireless resource allocation and provide a strong foundation for future research on generalizable learning-based wireless optimization.
Beam Prediction Based on Multimodal Large Language Models
Mar 16, 2026Accurate beam prediction is a key enabler for next-generation wireless communication systems. In this paper, we propose a multimodal large language model (LLM)-based beam prediction framework that effectively utilizes contextual information, provided by sensory data including RGB camera images and LiDAR point clouds. To effectively fuse heterogeneous modalities, we design specialized modality encoders together with a beam-guided attention masking mechanism and a high-frequency temporal alignment strategy, enabling robust cross-modal feature integration under dynamic environments. Furthermore, we construct a large-scale multimodal dataset for communication, named Multimodal-Wireless, which covers diverse weather and traffic conditions with high-fidelity ray-tracing labels. Extensive simulation results demonstrate that the proposed approach significantly reduces the reliance on oracle angle-of-departure knowledge and consistently outperforms state-of-the-art multimodal LLM-based beam prediction methods in terms of beam accuracy and communication performance, improving the average Top-1 accuracy to 80.8% and the average normalized gain to 89.1%.
Improving Channel Estimation via Multimodal Diffusion Models with Flow Matching
Mar 13, 2026Deep generative models offer a powerful alternative to conventional channel estimation by learning complex channel distributions. By integrating the rich environmental information available in modern sensing-aided networks, this paper proposes MultiCE-Flow, a multimodal channel estimation framework based on flow matching and diffusion transformer (DiT). We design a specialized multimodal perception module that fuses LiDAR, camera, and location data into a semantic condition, while treating sparse pilots as a structural condition. These conditions guide a DiT backbone to reconstruct high-fidelity channels. Unlike standard diffusion models, we employ flow matching to learn a linear trajectory from noise to data, enabling efficient one-step sampling. By leveraging environmental semantics, our method mitigates the ill-posed nature of estimation with sparse pilots. Extensive experiments demonstrate that MultiCE-Flow consistently outperforms traditional baselines and existing generative models. Notably, it exhibits superior robustness to out-of-distribution scenarios and varying pilot densities, making it suitable for environment-aware communication systems.
Wireless Power Control Based on Large Language Models
Feb 28, 2026This paper investigates the power control problem in wireless networks by repurposing pre-trained large language models (LLMs) as relational reasoning backbones. In hyper-connected interference environments, traditional optimization methods face high computational cost, while standard message passing neural networks suffer from aggregation bottlenecks that can obscure critical high-interference structures. In response, we propose PC-LLM, a physics-informed framework that augments a pre-trained Transformer with an interference-aware attention bias. The proposed bias tuning mechanism injects the physical channel gain matrix directly into the self-attention logits, enabling explicit fusion of wireless topology with pre-trained relational priors without retraining the backbone from scratch. Extensive experiments demonstrate that PC-LLM consistently outperforms both traditional optimization methods and state-of-the-art graph neural network baselines, while exhibiting exceptional zero-shot generalization to unseen environments. We further observe a structural-semantic decoupling phenomenon: Topology-relevant relational reasoning is concentrated in shallow layers, whereas deeper layers encode task-irrelevant semantic noise. Motivated by this finding, we develop a lightweight adaptation strategy that reduces model depth by 50\%, significantly lowering inference cost while preserving state-of-the-art spectral efficiency.
AoI-Driven Queue Management and Power Control in V2V Networks: A GNN-Enhanced MARL Approach
Jan 27, 2026Queue management and resource allocation play a critical role in enabling cooperative status awareness in vehicular networks. This paper investigates the problem of age of information (AoI)-aware status updates in vehicle-to-vehicle (V2V) communication, where each vehicle's status is represented by multiple interdependent packets. To enable fine-grained queue management at the packet level under resource constraints, we formulate a joint optimization problem that simultaneously learns active packet dropping and transmit power control strategies. A hybrid action space is designed to support both discrete dropping decisions and continuous power control. To exploit the graph-structured interference inherent in V2V topology, a graph neural network (GNN) is introduced to aggregate slowly varying large-scale fading, allowing agents to capture topological dependencies implicitly without frequent message exchange. The overall framework is built upon multi-agent proximal policy optimization (MAPPO), with centralized training and decentralized execution (CTDE). Simulations demonstrate that the proposed method significantly reduces average AoI across a wide range of network densities, channel conditions, and traffic loads, consistently outperforming several baselines.
CoDS: Collaborative Perception via Digital Semantic Communication
Dec 27, 2025Semantic communication has been introduced into collaborative perception systems for autonomous driving, offering a promising approach to enhancing data transmission efficiency and robustness. Despite its potential, existing semantic communication approaches predominantly rely on analog transmission models, rendering these systems fundamentally incompatible with the digital architecture of modern vehicle-to-everything (V2X) networks and posing a significant barrier to real-world deployment. To bridge this critical gap, we propose CoDS, a novel collaborative perception framework based on digital semantic communication, designed to realize semantic-level transmission efficiency within practical digital communication systems. Specifically, we develop a semantic compression codec that extracts and compresses task-oriented semantic features while preserving downstream perception accuracy. Building on this, we propose a novel semantic analog-to-digital converter that converts these continuous semantic features into a discrete bitstream, ensuring integration with existing digital communication pipelines. Furthermore, we develop an uncertainty-aware network (UAN) that assesses the reliability of each received feature and discards those corrupted by decoding failures, thereby mitigating the cliff effect of conventional channel coding schemes under low signal-to-noise ratio (SNR) conditions. Extensive experiments demonstrate that CoDS significantly outperforms existing semantic communication and traditional digital communication schemes, achieving state-of-the-art perception performance while ensuring compatibility with practical digital V2X systems.
Reducing Pilots in Channel Estimation With Predictive Foundation Models
Dec 17, 2025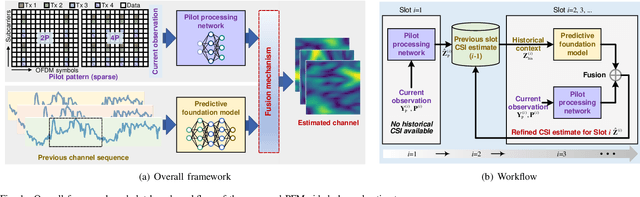
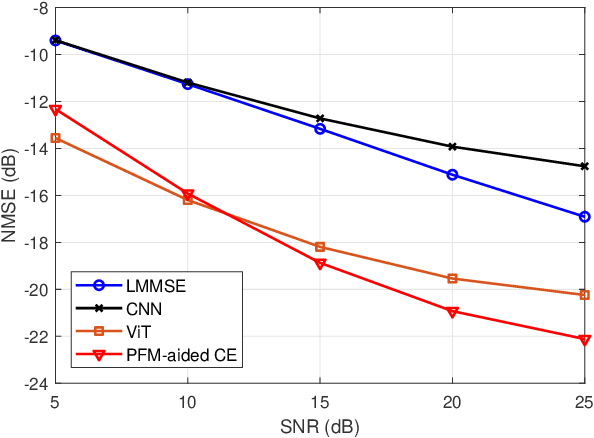
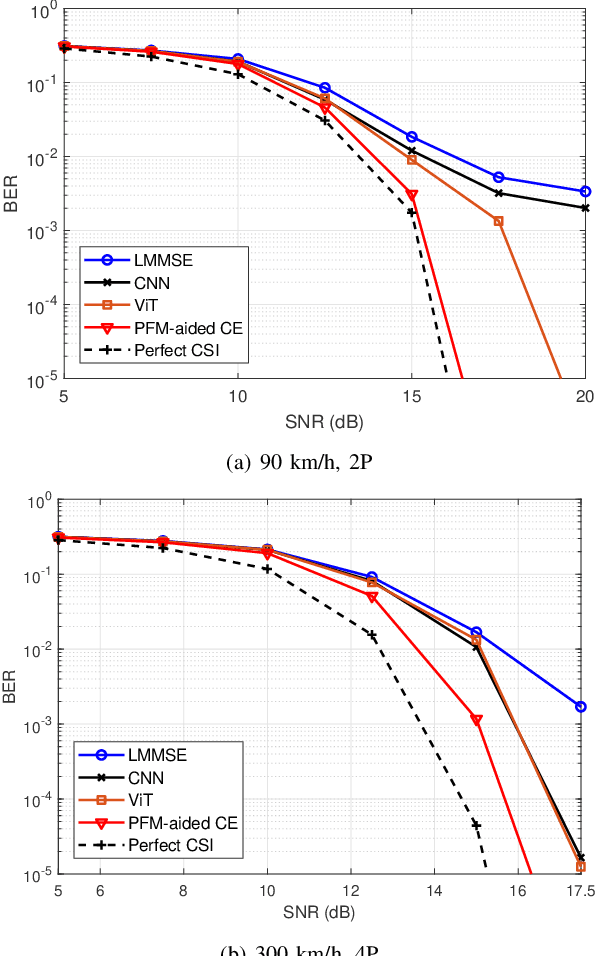
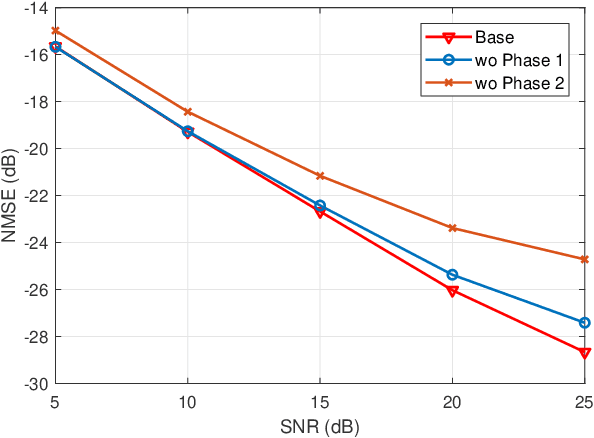
Accurate channel state information (CSI) acquisition is essential for modern wireless systems, which becomes increasingly difficult under large antenna arrays, strict pilot overhead constraints, and diverse deployment environments. Existing artificial intelligence-based solutions often lack robustness and fail to generalize across scenarios. To address this limitation, this paper introduces a predictive-foundation-model-based channel estimation framework that enables accurate, low-overhead, and generalizable CSI acquisition. The proposed framework employs a predictive foundation model trained on large-scale cross-domain CSI data to extract universal channel representations and provide predictive priors with strong cross-scenario transferability. A pilot processing network based on a vision transformer architecture is further designed to capture spatial, temporal, and frequency correlations from pilot observations. An efficient fusion mechanism integrates predictive priors with real-time measurements, enabling reliable CSI reconstruction even under sparse or noisy conditions. Extensive evaluations across diverse configurations demonstrate that the proposed estimator significantly outperforms both classical and data-driven baselines in accuracy, robustness, and generalization capability.
Next-Generation AI-Native Wireless Communications: MCMC-Based Receiver Architectures for Unified Processing
Oct 02, 2025The multiple-input multiple-output (MIMO) receiver processing is a key technology for current and next-generation wireless communications. However, it faces significant challenges related to complexity and scalability as the number of antennas increases. Artificial intelligence (AI), a cornerstone of next-generation wireless networks, offers considerable potential for addressing these challenges. This paper proposes an AI-driven, universal MIMO receiver architecture based on Markov chain Monte Carlo (MCMC) techniques. Unlike existing AI-based methods that treat receiver processing as a black box, our MCMC-based approach functions as a generic Bayesian computing engine applicable to various processing tasks, including channel estimation, symbol detection, and channel decoding. This method enhances the interpretability, scalability, and flexibility of receivers in diverse scenarios. Furthermore, the proposed approach integrates these tasks into a unified probabilistic framework, thereby enabling overall performance optimization. This unified framework can also be seamlessly combined with data-driven learning methods to facilitate the development of fully intelligent communication receivers.
SComCP: Task-Oriented Semantic Communication for Collaborative Perception
Jul 01, 2025Reliable detection of surrounding objects is critical for the safe operation of connected automated vehicles (CAVs). However, inherent limitations such as the restricted perception range and occlusion effects compromise the reliability of single-vehicle perception systems in complex traffic environments. Collaborative perception has emerged as a promising approach by fusing sensor data from surrounding CAVs with diverse viewpoints, thereby improving environmental awareness. Although collaborative perception holds great promise, its performance is bottlenecked by wireless communication constraints, as unreliable and bandwidth-limited channels hinder the transmission of sensor data necessary for real-time perception. To address these challenges, this paper proposes SComCP, a novel task-oriented semantic communication framework for collaborative perception. Specifically, SComCP integrates an importance-aware feature selection network that selects and transmits semantic features most relevant to the perception task, significantly reducing communication overhead without sacrificing accuracy. Furthermore, we design a semantic codec network based on a joint source and channel coding (JSCC) architecture, which enables bidirectional transformation between semantic features and noise-tolerant channel symbols, thereby ensuring stable perception under adverse wireless conditions. Extensive experiments demonstrate the effectiveness of the proposed framework. In particular, compared to existing approaches, SComCP can maintain superior perception performance across various channel conditions, especially in low signal-to-noise ratio (SNR) scenarios. In addition, SComCP exhibits strong generalization capability, enabling the framework to maintain high performance across diverse channel conditions, even when trained with a specific channel model.