 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Sep 21, 2023



We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference. On the other hand, we revisit the parameter-efficient fine-tuning regime for context expansion. Notably, we find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on LLaMA2 models from 7B/13B to 70B. LongLoRA adopts LLaMA2 7B from 4k context to 100k, or LLaMA2 70B to 32k on a single 8x A100 machine. LongLoRA extends models' context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2. In addition, to make LongLoRA practical, we collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
MapPrior: Bird's-Eye View Map Layout Estimation with Generative Models
Aug 24, 2023Despite tremendous advancements in bird's-eye view (BEV) perception, existing models fall short in generating realistic and coherent semantic map layouts, and they fail to account for uncertainties arising from partial sensor information (such as occlusion or limited coverage). In this work, we introduce MapPrior, a novel BEV perception framework that combines a traditional discriminative BEV perception model with a learned generative model for semantic map layouts. Our MapPrior delivers predictions with better accuracy, realism, and uncertainty awareness. We evaluate our model on the large-scale nuScenes benchmark. At the time of submission, MapPrior outperforms the strongest competing method, with significantly improved MMD and ECE scores in camera- and LiDAR-based BEV perception.
CA-CentripetalNet: A novel anchor-free deep learning framework for hardhat wearing detection
Jul 09, 2023Automatic hardhat wearing detection can strengthen the safety management in construction sites, which is still challenging due to complicated video surveillance scenes. To deal with the poor generalization of previous deep learning based methods, a novel anchor-free deep learning framework called CA-CentripetalNet is proposed for hardhat wearing detection. Two novel schemes are proposed to improve the feature extraction and utilization ability of CA-CentripetalNet, which are vertical-horizontal corner pooling and bounding constrained center attention. The former is designed to realize the comprehensive utilization of marginal features and internal features. The latter is designed to enforce the backbone to pay attention to internal features, which is only used during the training rather than during the detection. Experimental results indicate that the CA-CentripetalNet achieves better performance with the 86.63% mAP (mean Average Precision) with less memory consumption at a reasonable speed than the existing deep learning based methods, especially in case of small-scale hardhats and non-worn-hardhats.
* It has been accepted for the journal of Signal, Image and Video Processing, which is a complete version. It is noted that it has been deleted for future publishing
SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer
Mar 30, 2023



High-resolution images enable neural networks to learn richer visual representations. However, this improved performance comes at the cost of growing computational complexity, hindering their usage in latency-sensitive applications. As not all pixels are equal, skipping computations for less-important regions offers a simple and effective measure to reduce the computation. This, however, is hard to be translated into actual speedup for CNNs since it breaks the regularity of the dense convolution workload. In this paper, we introduce SparseViT that revisits activation sparsity for recent window-based vision transformers (ViTs). As window attentions are naturally batched over blocks, actual speedup with window activation pruning becomes possible: i.e., ~50% latency reduction with 60% sparsity. Different layers should be assigned with different pruning ratios due to their diverse sensitivities and computational costs. We introduce sparsity-aware adaptation and apply the evolutionary search to efficiently find the optimal layerwise sparsity configuration within the vast search space. SparseViT achieves speedups of 1.5x, 1.4x, and 1.3x compared to its dense counterpart in monocular 3D object detection, 2D instance segmentation, and 2D semantic segmentation, respectively, with negligible to no loss of accuracy.
FlatFormer: Flattened Window Attention for Efficient Point Cloud Transformer
Jan 20, 2023



Transformer, as an alternative to CNN, has been proven effective in many modalities (e.g., texts and images). For 3D point cloud transformers, existing efforts focus primarily on pushing their accuracy to the state-of-the-art level. However, their latency lags behind sparse convolution-based models (3x slower), hindering their usage in resource-constrained, latency-sensitive applications (such as autonomous driving). This inefficiency comes from point clouds' sparse and irregular nature, whereas transformers are designed for dense, regular workloads. This paper presents FlatFormer to close this latency gap by trading spatial proximity for better computational regularity. We first flatten the point cloud with window-based sorting and partition points into groups of equal sizes rather than windows of equal shapes. This effectively avoids expensive structuring and padding overheads. We then apply self-attention within groups to extract local features, alternate sorting axis to gather features from different directions, and shift windows to exchange features across groups. FlatFormer delivers state-of-the-art accuracy on Waymo Open Dataset with 4.6x speedup over (transformer-based) SST and 1.4x speedup over (sparse convolutional) CenterPoint. This is the first point cloud transformer that achieves real-time performance on edge GPUs and is faster than sparse convolutional methods while achieving on-par or even superior accuracy on large-scale benchmarks. Code to reproduce our results will be made publicly available.
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
May 26, 2022
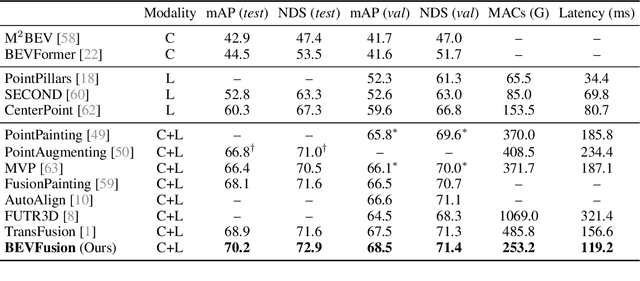
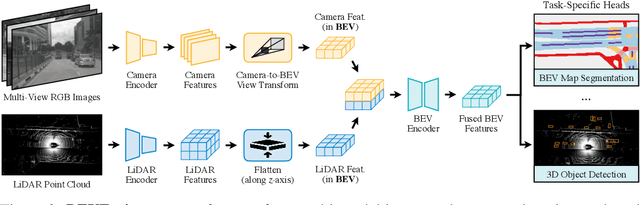
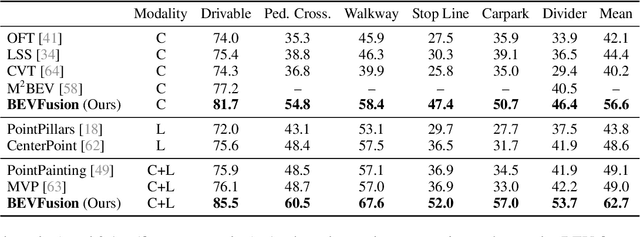
Multi-sensor fusion is essential for an accurate and reliable autonomous driving system. Recent approaches are based on point-level fusion: augmenting the LiDAR point cloud with camera features. However, the camera-to-LiDAR projection throws away the semantic density of camera features, hindering the effectiveness of such methods, especially for semantic-oriented tasks (such as 3D scene segmentation). In this paper, we break this deeply-rooted convention with BEVFusion, an efficient and generic multi-task multi-sensor fusion framework. It unifies multi-modal features in the shared bird's-eye view (BEV) representation space, which nicely preserves both geometric and semantic information. To achieve this, we diagnose and lift key efficiency bottlenecks in the view transformation with optimized BEV pooling, reducing latency by more than 40x. BEVFusion is fundamentally task-agnostic and seamlessly supports different 3D perception tasks with almost no architectural changes. It establishes the new state of the art on nuScenes, achieving 1.3% higher mAP and NDS on 3D object detection and 13.6% higher mIoU on BEV map segmentation, with 1.9x lower computation cost.
PVNAS: 3D Neural Architecture Search with Point-Voxel Convolution
Apr 26, 2022
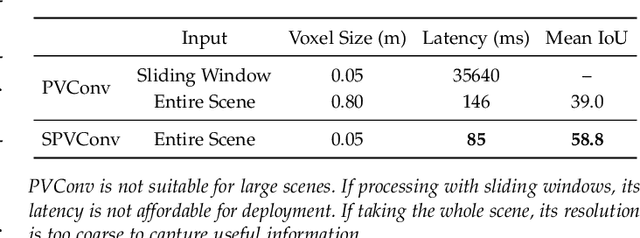
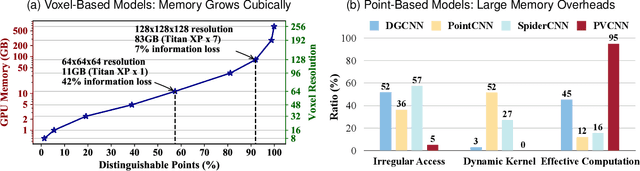
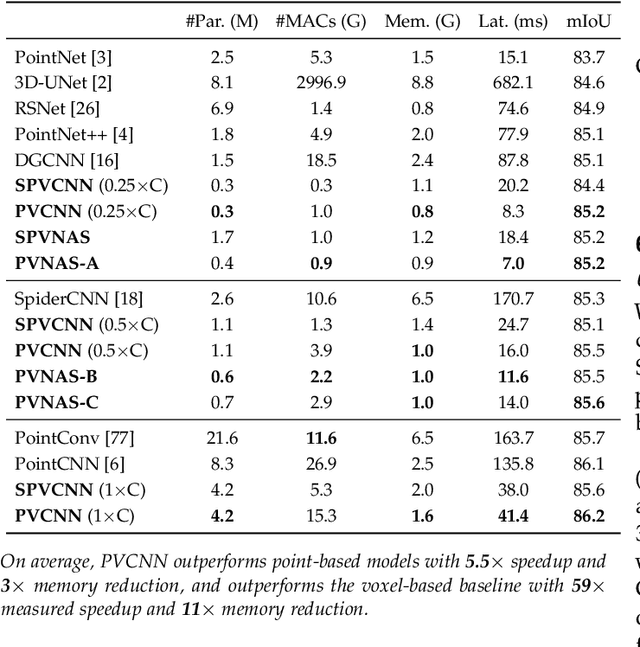
3D neural networks are widely used in real-world applications (e.g., AR/VR headsets, self-driving cars). They are required to be fast and accurate; however, limited hardware resources on edge devices make these requirements rather challenging. Previous work processes 3D data using either voxel-based or point-based neural networks, but both types of 3D models are not hardware-efficient due to the large memory footprint and random memory access. In this paper, we study 3D deep learning from the efficiency perspective. We first systematically analyze the bottlenecks of previous 3D methods. We then combine the best from point-based and voxel-based models together and propose a novel hardware-efficient 3D primitive, Point-Voxel Convolution (PVConv). We further enhance this primitive with the sparse convolution to make it more effective in processing large (outdoor) scenes. Based on our designed 3D primitive, we introduce 3D Neural Architecture Search (3D-NAS) to explore the best 3D network architecture given a resource constraint. We evaluate our proposed method on six representative benchmark datasets, achieving state-of-the-art performance with 1.8-23.7x measured speedup. Furthermore, our method has been deployed to the autonomous racing vehicle of MIT Driverless, achieving larger detection range, higher accuracy and lower latency.
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022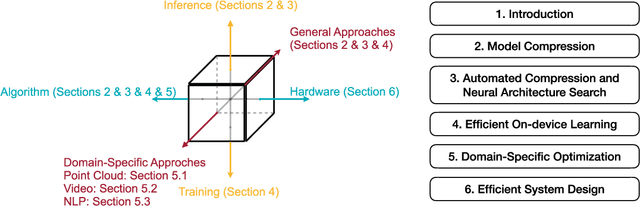
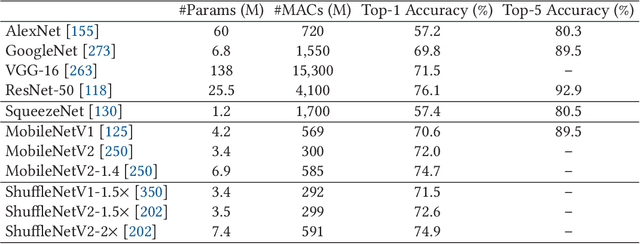
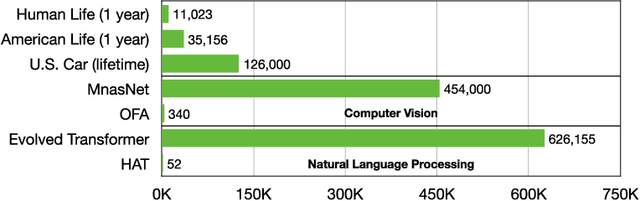
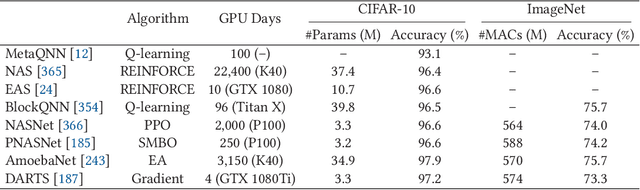
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order
TorchSparse: Efficient Point Cloud Inference Engine
Apr 21, 2022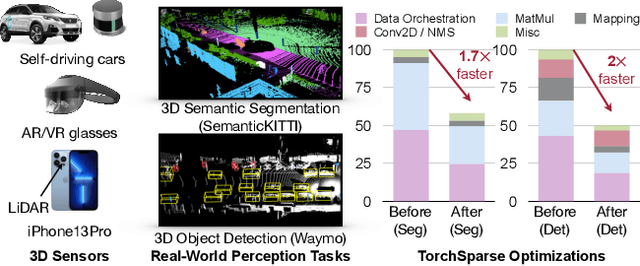

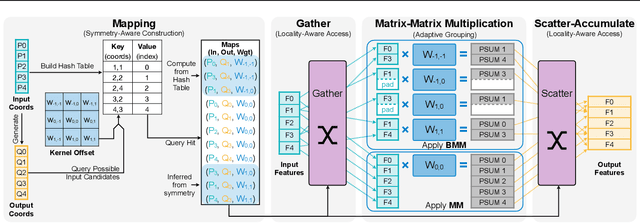

Deep learning on point clouds has received increased attention thanks to its wide applications in AR/VR and autonomous driving. These applications require low latency and high accuracy to provide real-time user experience and ensure user safety. Unlike conventional dense workloads, the sparse and irregular nature of point clouds poses severe challenges to running sparse CNNs efficiently on the general-purpose hardware. Furthermore, existing sparse acceleration techniques for 2D images do not translate to 3D point clouds. In this paper, we introduce TorchSparse, a high-performance point cloud inference engine that accelerates the sparse convolution computation on GPUs. TorchSparse directly optimizes the two bottlenecks of sparse convolution: irregular computation and data movement. It applies adaptive matrix multiplication grouping to trade computation for better regularity, achieving 1.4-1.5x speedup for matrix multiplication. It also optimizes the data movement by adopting vectorized, quantized and fused locality-aware memory access, reducing the memory movement cost by 2.7x. Evaluated on seven representative models across three benchmark datasets, TorchSparse achieves 1.6x and 1.5x measured end-to-end speedup over the state-of-the-art MinkowskiEngine and SpConv, respectively.
VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
Nov 23, 2021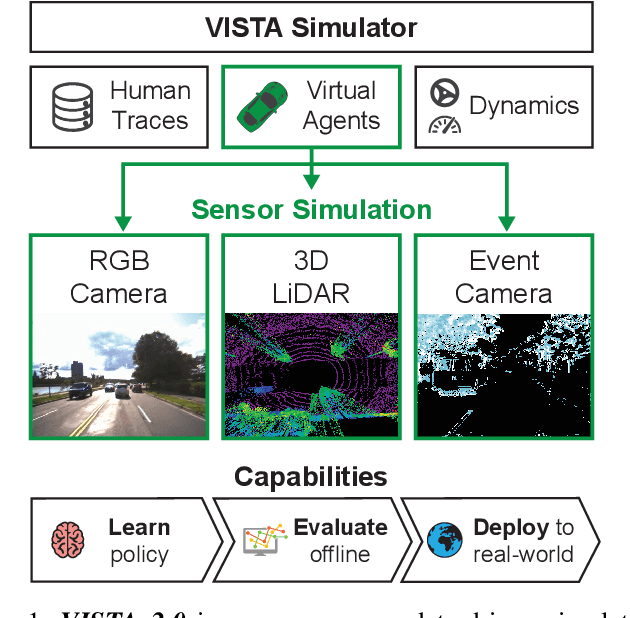
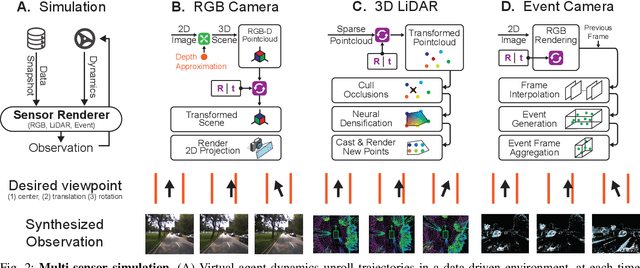
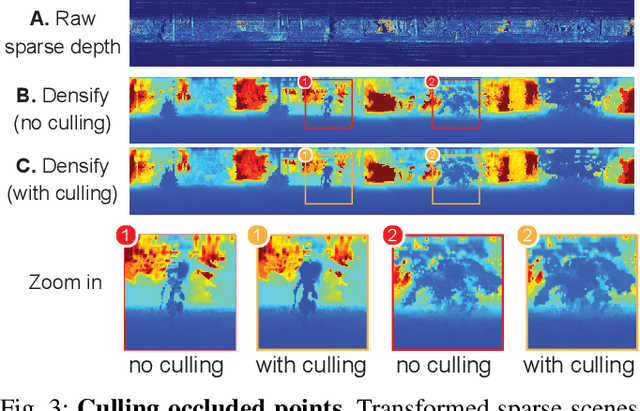

Simulation has the potential to transform the development of robust algorithms for mobile agents deployed in safety-critical scenarios. However, the poor photorealism and lack of diverse sensor modalities of existing simulation engines remain key hurdles towards realizing this potential. Here, we present VISTA, an open source, data-driven simulator that integrates multiple types of sensors for autonomous vehicles. Using high fidelity, real-world datasets, VISTA represents and simulates RGB cameras, 3D LiDAR, and event-based cameras, enabling the rapid generation of novel viewpoints in simulation and thereby enriching the data available for policy learning with corner cases that are difficult to capture in the physical world. Using VISTA, we demonstrate the ability to train and test perception-to-control policies across each of the sensor types and showcase the power of this approach via deployment on a full scale autonomous vehicle. The policies learned in VISTA exhibit sim-to-real transfer without modification and greater robustness than those trained exclusively on real-world data.