 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLGStream: Dynamic Language-embedded Guassian Splatting for Open-vocabulary Enabled Free-viewpoint Video Streaming
Jun 27, 20263D Gaussian Splatting~(3DGS) has emerged as a promising paradigm for reconstructing streamable free-viewpoint video~(FVV) from multi-view videos. However, 3DGS-based FVVs typically lack user interaction and editing capabilities, which diminishes the immersive experience. Recent research has integrated language features from CLIP into 3DGS via distillation, enabling open-vocabulary queries and supporting many downstream applications. Nevertheless, the stringent requirements of FVV, low frame size and high FPS, make current language Gaussian representations unsuitable for language-embedded FVV. In this paper, we propose DLGStream, a novel language-embedded FVV representation that streams time-varying language features alongside Gaussian attributes to support 4D environment interaction, scene editing, and spatial intelligence. Specifically, we propose a dual-opacity dynamic language Gaussian representation, which maintains two opacity attributes for color and language features to deal with performance degradation that occurs when colors and features are jointly optimized. Furthermore, we introduce an interpolation-based deformation field to reduce temporal redundancy. This deformation field can also be used for 4D frame interpolation, boosting FVV sequences from low to high FPS. Experimental results demonstrate that DLGStream achieves superior performance in both on open-vocabulary segmentation and reconstruction quality with an average frame size of merely 43 KB. The code is available on \href{https://github.com/kkkzh/DLGStream}{https://github.com/kkkzh/DLGStream}.
CometNet: Contextual Motif-guided Long-term Time Series Forecasting
Nov 11, 2025



Long-term Time Series Forecasting is crucial across numerous critical domains, yet its accuracy remains fundamentally constrained by the receptive field bottleneck in existing models. Mainstream Transformer- and Multi-layer Perceptron (MLP)-based methods mainly rely on finite look-back windows, limiting their ability to model long-term dependencies and hurting forecasting performance. Naively extending the look-back window proves ineffective, as it not only introduces prohibitive computational complexity, but also drowns vital long-term dependencies in historical noise. To address these challenges, we propose CometNet, a novel Contextual Motif-guided Long-term Time Series Forecasting framework. CometNet first introduces a Contextual Motif Extraction module that identifies recurrent, dominant contextual motifs from complex historical sequences, providing extensive temporal dependencies far exceeding limited look-back windows; Subsequently, a Motif-guided Forecasting module is proposed, which integrates the extracted dominant motifs into forecasting. By dynamically mapping the look-back window to its relevant motifs, CometNet effectively harnesses their contextual information to strengthen long-term forecasting capability. Extensive experimental results on eight real-world datasets have demonstrated that CometNet significantly outperforms current state-of-the-art (SOTA) methods, particularly on extended forecast horizons.
StreamSTGS: Streaming Spatial and Temporal Gaussian Grids for Real-Time Free-Viewpoint Video
Nov 08, 2025Streaming free-viewpoint video~(FVV) in real-time still faces significant challenges, particularly in training, rendering, and transmission efficiency. Harnessing superior performance of 3D Gaussian Splatting~(3DGS), recent 3DGS-based FVV methods have achieved notable breakthroughs in both training and rendering. However, the storage requirements of these methods can reach up to $10$MB per frame, making stream FVV in real-time impossible. To address this problem, we propose a novel FVV representation, dubbed StreamSTGS, designed for real-time streaming. StreamSTGS represents a dynamic scene using canonical 3D Gaussians, temporal features, and a deformation field. For high compression efficiency, we encode canonical Gaussian attributes as 2D images and temporal features as a video. This design not only enables real-time streaming, but also inherently supports adaptive bitrate control based on network condition without any extra training. Moreover, we propose a sliding window scheme to aggregate adjacent temporal features to learn local motions, and then introduce a transformer-guided auxiliary training module to learn global motions. On diverse FVV benchmarks, StreamSTGS demonstrates competitive performance on all metrics compared to state-of-the-art methods. Notably, StreamSTGS increases the PSNR by an average of $1$dB while reducing the average frame size to just $170$KB. The code is publicly available on https://github.com/kkkzh/StreamSTGS.
TimeFormer: Capturing Temporal Relationships of Deformable 3D Gaussians for Robust Reconstruction
Nov 18, 2024Dynamic scene reconstruction is a long-term challenge in 3D vision. Recent methods extend 3D Gaussian Splatting to dynamic scenes via additional deformation fields and apply explicit constraints like motion flow to guide the deformation. However, they learn motion changes from individual timestamps independently, making it challenging to reconstruct complex scenes, particularly when dealing with violent movement, extreme-shaped geometries, or reflective surfaces. To address the above issue, we design a plug-and-play module called TimeFormer to enable existing deformable 3D Gaussians reconstruction methods with the ability to implicitly model motion patterns from a learning perspective. Specifically, TimeFormer includes a Cross-Temporal Transformer Encoder, which adaptively learns the temporal relationships of deformable 3D Gaussians. Furthermore, we propose a two-stream optimization strategy that transfers the motion knowledge learned from TimeFormer to the base stream during the training phase. This allows us to remove TimeFormer during inference, thereby preserving the original rendering speed. Extensive experiments in the multi-view and monocular dynamic scenes validate qualitative and quantitative improvement brought by TimeFormer. Project Page: https://patrickddj.github.io/TimeFormer/
DS-NeRV: Implicit Neural Video Representation with Decomposed Static and Dynamic Codes
Mar 23, 2024



Implicit neural representations for video (NeRV) have recently become a novel way for high-quality video representation. However, existing works employ a single network to represent the entire video, which implicitly confuse static and dynamic information. This leads to an inability to effectively compress the redundant static information and lack the explicitly modeling of global temporal-coherent dynamic details. To solve above problems, we propose DS-NeRV, which decomposes videos into sparse learnable static codes and dynamic codes without the need for explicit optical flow or residual supervision. By setting different sampling rates for two codes and applying weighted sum and interpolation sampling methods, DS-NeRV efficiently utilizes redundant static information while maintaining high-frequency details. Additionally, we design a cross-channel attention-based (CCA) fusion module to efficiently fuse these two codes for frame decoding. Our approach achieves a high quality reconstruction of 31.2 PSNR with only 0.35M parameters thanks to separate static and dynamic codes representation and outperforms existing NeRV methods in many downstream tasks. Our project website is at https://haoyan14.github.io/DS-NeRV.
TrustGNN: Graph Neural Network based Trust Evaluation via Learnable Propagative and Composable Nature
May 25, 2022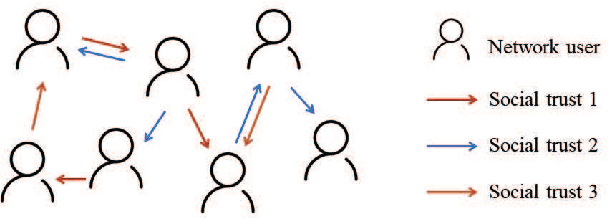
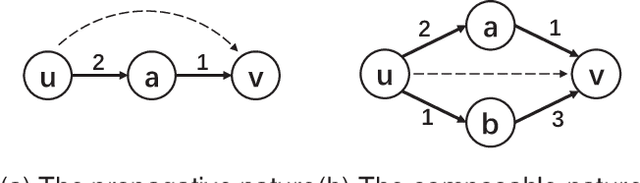
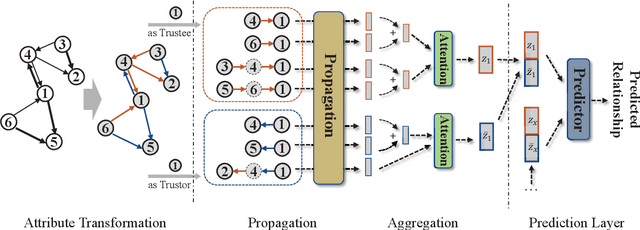
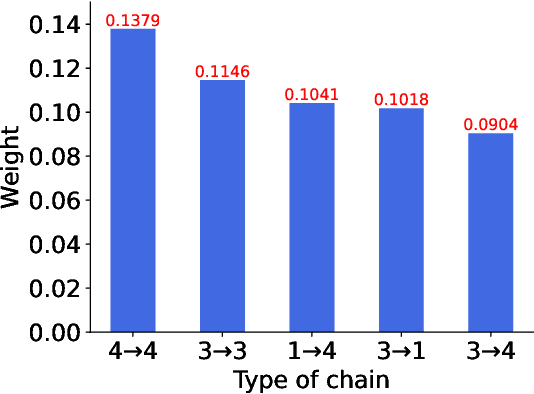
Trust evaluation is critical for many applications such as cyber security, social communication and recommender systems. Users and trust relationships among them can be seen as a graph. Graph neural networks (GNNs) show their powerful ability for analyzing graph-structural data. Very recently, existing work attempted to introduce the attributes and asymmetry of edges into GNNs for trust evaluation, while failed to capture some essential properties (e.g., the propagative and composable nature) of trust graphs. In this work, we propose a new GNN based trust evaluation method named TrustGNN, which integrates smartly the propagative and composable nature of trust graphs into a GNN framework for better trust evaluation. Specifically, TrustGNN designs specific propagative patterns for different propagative processes of trust, and distinguishes the contribution of different propagative processes to create new trust. Thus, TrustGNN can learn comprehensive node embeddings and predict trust relationships based on these embeddings. Experiments on some widely-used real-world datasets indicate that TrustGNN significantly outperforms the state-of-the-art methods. We further perform analytical experiments to demonstrate the effectiveness of the key designs in TrustGNN.
A Fast Ellipse Detector Using Projective Invariant Pruning
Aug 26, 2016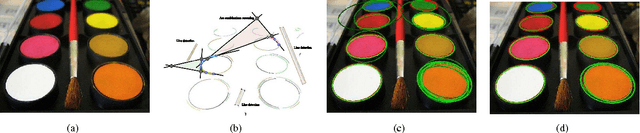
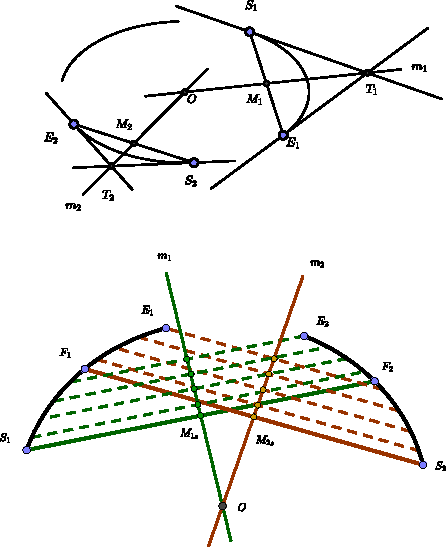
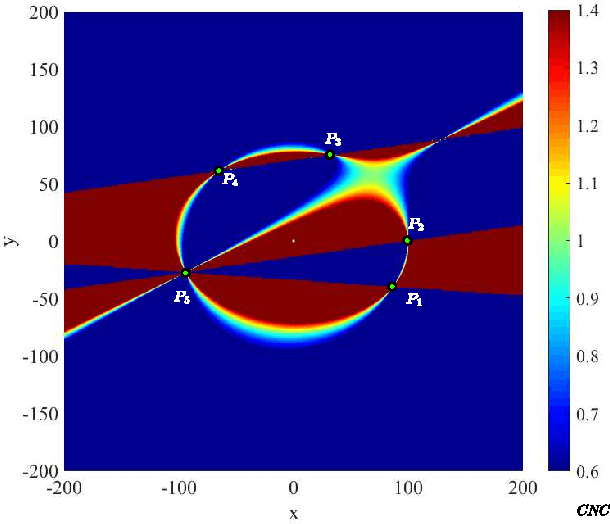
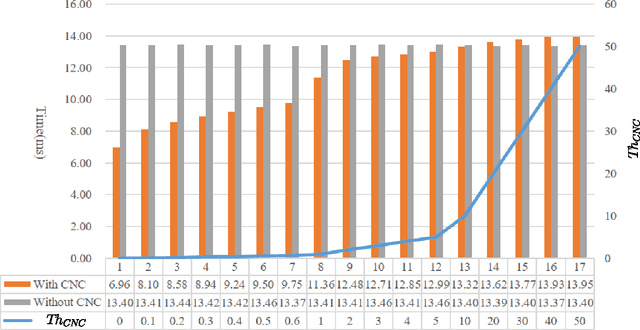
Detecting elliptical objects from an image is a central task in robot navigation and industrial diagnosis where the detection time is always a critical issue. Existing methods are hardly applicable to these real-time scenarios of limited hardware resource due to the huge number of fragment candidates (edges or arcs) for fitting ellipse equations. In this paper, we present a fast algorithm detecting ellipses with high accuracy. The algorithm leverage a newly developed projective invariant to significantly prune the undesired candidates and to pick out elliptical ones. The invariant is able to reflect the intrinsic geometry of a planar curve, giving the value of -1 on any three collinear points and +1 for any six points on an ellipse. Thus, we apply the pruning and picking by simply comparing these binary values. Moreover, the calculation of the invariant only involves the determinant of a 3*3 matrix. Extensive experiments on three challenging data sets with 650 images demonstrate that our detector runs 20%-50% faster than the state-of-the-art algorithms with the comparable or higher precision.