 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Latent Reasoning with Decoupled Policy Optimization
Apr 22, 2026Chain-of-Thought (CoT) reasoning significantly elevates the complex problem-solving capabilities of multimodal large language models (MLLMs). However, adapting CoT to vision typically discretizes signals to fit LLM inputs, causing early semantic collapse and discarding fine-grained details. While external tools can mitigate this, they introduce a rigid bottleneck, confining reasoning to predefined operations. Although recent latent reasoning paradigms internalize visual states to overcome these limitations, optimizing the resulting hybrid discrete-continuous action space remains challenging. In this work, we propose HyLaR (Hybrid Latent Reasoning), a framework that seamlessly interleaves discrete text generation with continuous visual latent representations. Specifically, following an initial cold-start supervised fine-tuning (SFT), we introduce DePO (Decoupled Policy Optimization) to enable effective reinforcement learning within this hybrid space. DePO decomposes the policy gradient objective, applying independent trust-region constraints to the textual and latent components, alongside an exact closed-form von Mises-Fisher (vMF) KL regularizer. Extensive experiments demonstrate that HyLaR outperforms standard MLLMs and state-of-the-art latent reasoning approaches across fine-grained perception and general multimodal understanding benchmarks. Code is available at https://github.com/EthenCheng/HyLaR.
Omni IIE Bench: Benchmarking the Practical Capabilities of Image Editing Models
Mar 16, 2026While Instruction-based Image Editing (IIE) has achieved significant progress, existing benchmarks pursue task breadth via mixed evaluations. This paradigm obscures a critical failure mode crucial in professional applications: the inconsistent performance of models across tasks of varying semantic scales. To address this gap, we introduce Omni IIE Bench, a high-quality, human-annotated benchmark specifically designed to diagnose the editing consistency of IIE models in practical application scenarios. Omni IIE Bench features an innovative dual-track diagnostic design: (1) Single-turn Consistency, comprising shared-context task pairs of attribute modification and entity replacement; and (2) Multi-turn Coordination, involving continuous dialogue tasks that traverse semantic scales. The benchmark is constructed via an exceptionally rigorous multi-stage human filtering process, incorporating a quality standard enforced by computer vision graduate students and an industry relevance review conducted by professional designers. We perform a comprehensive evaluation of 8 mainstream IIE models using Omni IIE Bench. Our analysis quantifies, for the first time, a prevalent performance gap: nearly all models exhibit a significant performance degradation when transitioning from low-semantic-scale to high-semantic-scale tasks. Omni IIE Bench provides critical diagnostic tools and insights for the development of next-generation, more reliable, and stable IIE models.
Beyond Closed-Pool Video Retrieval: A Benchmark and Agent Framework for Real-World Video Search and Moment Localization
Feb 10, 2026Traditional video retrieval benchmarks focus on matching precise descriptions to closed video pools, failing to reflect real-world searches characterized by fuzzy, multi-dimensional memories on the open web. We present \textbf{RVMS-Bench}, a comprehensive system for evaluating real-world video memory search. It consists of \textbf{1,440 samples} spanning \textbf{20 diverse categories} and \textbf{four duration groups}, sourced from \textbf{real-world open-web videos}. RVMS-Bench utilizes a hierarchical description framework encompassing \textbf{Global Impression, Key Moment, Temporal Context, and Auditory Memory} to mimic realistic multi-dimensional search cues, with all samples strictly verified via a human-in-the-loop protocol. We further propose \textbf{RACLO}, an agentic framework that employs abductive reasoning to simulate the human ``Recall-Search-Verify'' cognitive process, effectively addressing the challenge of searching for videos via fuzzy memories in the real world. Experiments reveal that existing MLLMs still demonstrate insufficient capabilities in real-world Video Retrieval and Moment Localization based on fuzzy memories. We believe this work will facilitate the advancement of video retrieval robustness in real-world unstructured scenarios.
VDE Bench: Evaluating The Capability of Image Editing Models to Modify Visual Documents
Jan 27, 2026In recent years, multimodal image editing models have achieved substantial progress, enabling users to manipulate visual content through natural language in a flexible and interactive manner. Nevertheless, an important yet insufficiently explored research direction remains visual document image editing, which involves modifying textual content within images while faithfully preserving the original text style and background context. Existing approaches, including AnyText, GlyphControl, and TextCtrl, predominantly focus on English-language scenarios and documents with relatively sparse textual layouts, thereby failing to adequately address dense, structurally complex documents or non-Latin scripts such as Chinese. To bridge this gap, we propose \textbf{V}isual \textbf{D}oc \textbf{E}dit Bench(VDE Bench), a rigorously human-annotated and evaluated benchmark specifically designed to assess image editing models on multilingual and complex visual document editing tasks. The benchmark comprises a high-quality dataset encompassing densely textual documents in both English and Chinese, including academic papers, posters, presentation slides, examination materials, and newspapers. Furthermore, we introduce a decoupled evaluation framework that systematically quantifies editing performance at the OCR parsing level, enabling fine-grained assessment of text modification accuracy. Based on this benchmark, we conduct a comprehensive evaluation of representative state-of-the-art image editing models. Manual verification demonstrates a strong consistency between human judgments and automated evaluation metrics. VDE Bench constitutes the first systematic benchmark for evaluating image editing models on multilingual and densely textual visual documents.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Mulco: Recognizing Chinese Nested Named Entities Through Multiple Scopes
Nov 20, 2022



Nested Named Entity Recognition (NNER) has been a long-term challenge to researchers as an important sub-area of Named Entity Recognition. NNER is where one entity may be part of a longer entity, and this may happen on multiple levels, as the term nested suggests. These nested structures make traditional sequence labeling methods unable to properly recognize all entities. While recent researches focus on designing better recognition methods for NNER in a variety of languages, the Chinese NNER (CNNER) still lacks attention, where a free-for-access, CNNER-specialized benchmark is absent. In this paper, we aim to solve CNNER problems by providing a Chinese dataset and a learning-based model to tackle the issue. To facilitate the research on this task, we release ChiNesE, a CNNER dataset with 20,000 sentences sampled from online passages of multiple domains, containing 117,284 entities failing in 10 categories, where 43.8 percent of those entities are nested. Based on ChiNesE, we propose Mulco, a novel method that can recognize named entities in nested structures through multiple scopes. Each scope use a designed scope-based sequence labeling method, which predicts an anchor and the length of a named entity to recognize it. Experiment results show that Mulco has outperformed several baseline methods with the different recognizing schemes on ChiNesE. We also conduct extensive experiments on ACE2005 Chinese corpus, where Mulco has achieved the best performance compared with the baseline methods.
TAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Oct 24, 2021
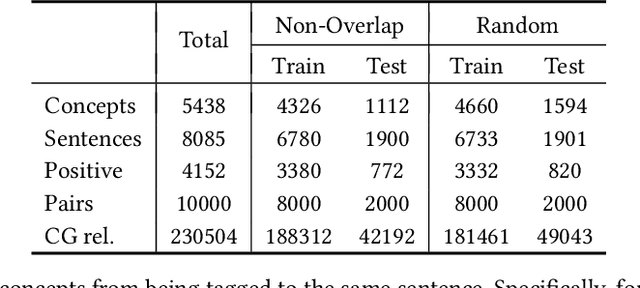

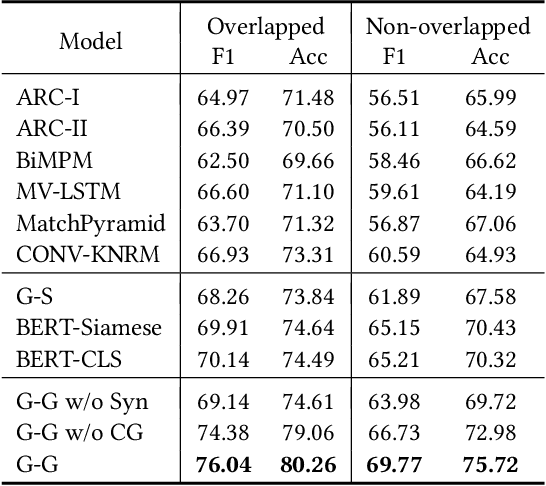
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.
LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization
Aug 03, 2021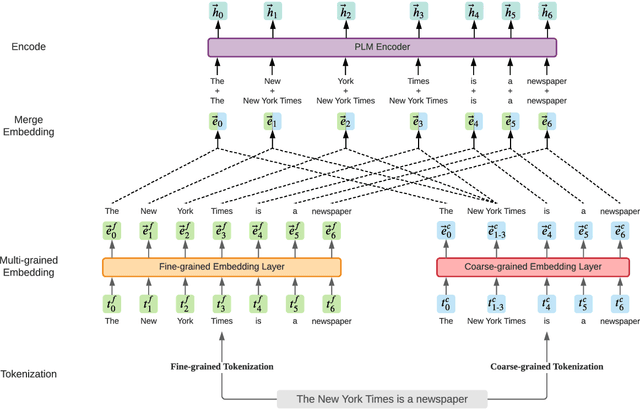
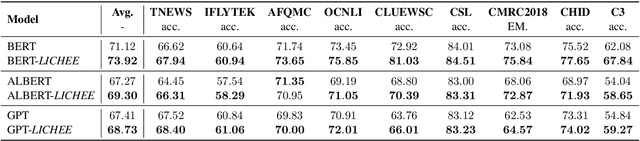
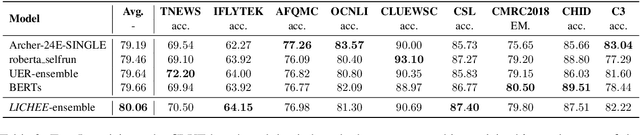
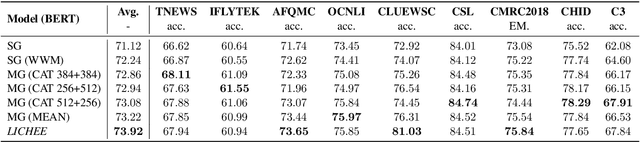
Language model pre-training based on large corpora has achieved tremendous success in terms of constructing enriched contextual representations and has led to significant performance gains on a diverse range of Natural Language Understanding (NLU) tasks. Despite the success, most current pre-trained language models, such as BERT, are trained based on single-grained tokenization, usually with fine-grained characters or sub-words, making it hard for them to learn the precise meaning of coarse-grained words and phrases. In this paper, we propose a simple yet effective pre-training method named LICHEE to efficiently incorporate multi-grained information of input text. Our method can be applied to various pre-trained language models and improve their representation capability. Extensive experiments conducted on CLUE and SuperGLUE demonstrate that our method achieves comprehensive improvements on a wide variety of NLU tasks in both Chinese and English with little extra inference cost incurred, and that our best ensemble model achieves the state-of-the-art performance on CLUE benchmark competition.
GIANT: Scalable Creation of a Web-scale Ontology
Apr 05, 2020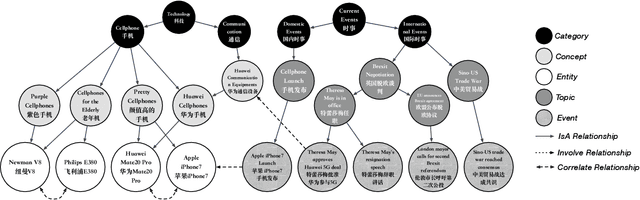

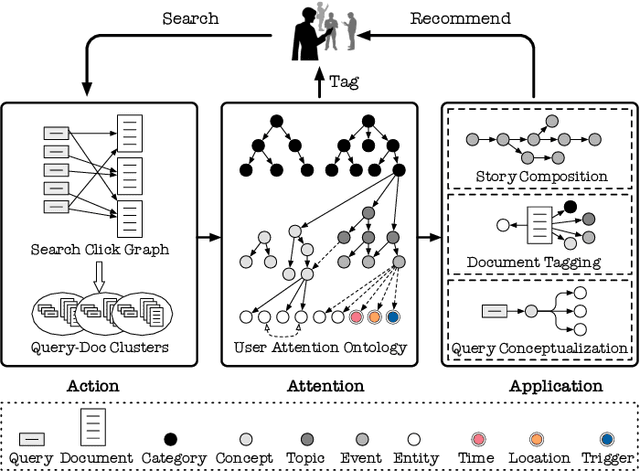
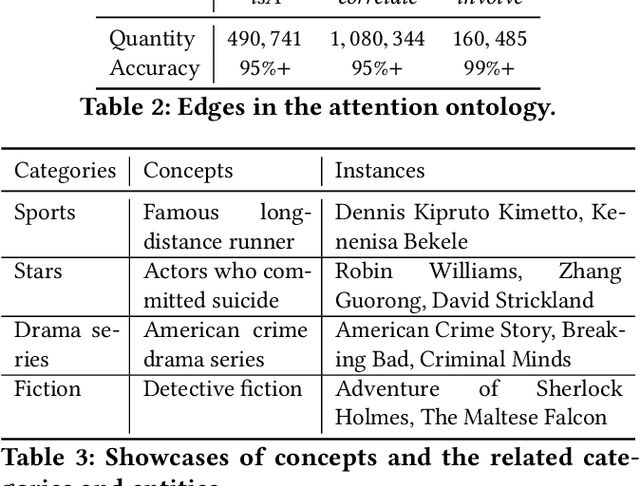
Understanding what online users may pay attention to is key to content recommendation and search services. These services will benefit from a highly structured and web-scale ontology of entities, concepts, events, topics and categories. While existing knowledge bases and taxonomies embody a large volume of entities and categories, we argue that they fail to discover properly grained concepts, events and topics in the language style of online population. Neither is a logically structured ontology maintained among these notions. In this paper, we present GIANT, a mechanism to construct a user-centered, web-scale, structured ontology, containing a large number of natural language phrases conforming to user attentions at various granularities, mined from a vast volume of web documents and search click graphs. Various types of edges are also constructed to maintain a hierarchy in the ontology. We present our graph-neural-network-based techniques used in GIANT, and evaluate the proposed methods as compared to a variety of baselines. GIANT has produced the Attention Ontology, which has been deployed in various Tencent applications involving over a billion users. Online A/B testing performed on Tencent QQ Browser shows that Attention Ontology can significantly improve click-through rates in news recommendation.