 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Mapping of the Best-Suited DNN Pruning Schemes for Real-Time Mobile Acceleration
Nov 22, 2021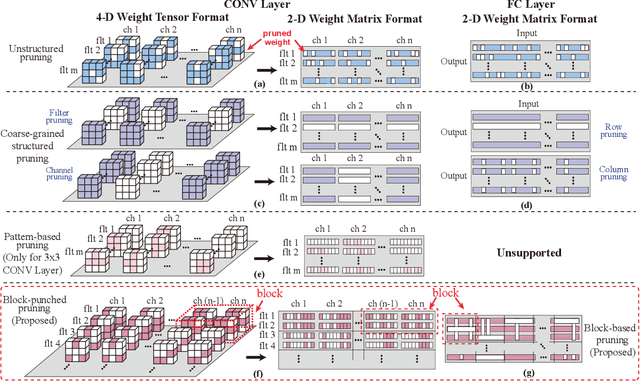

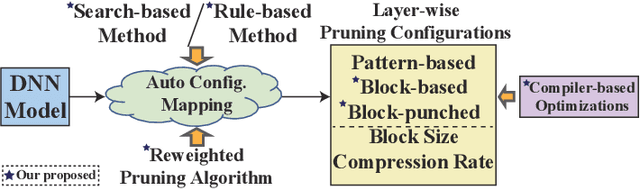
Weight pruning is an effective model compression technique to tackle the challenges of achieving real-time deep neural network (DNN) inference on mobile devices. However, prior pruning schemes have limited application scenarios due to accuracy degradation, difficulty in leveraging hardware acceleration, and/or restriction on certain types of DNN layers. In this paper, we propose a general, fine-grained structured pruning scheme and corresponding compiler optimizations that are applicable to any type of DNN layer while achieving high accuracy and hardware inference performance. With the flexibility of applying different pruning schemes to different layers enabled by our compiler optimizations, we further probe into the new problem of determining the best-suited pruning scheme considering the different acceleration and accuracy performance of various pruning schemes. Two pruning scheme mapping methods, one is search-based and the other is rule-based, are proposed to automatically derive the best-suited pruning regularity and block size for each layer of any given DNN. Experimental results demonstrate that our pruning scheme mapping methods, together with the general fine-grained structured pruning scheme, outperform the state-of-the-art DNN optimization framework with up to 2.48$\times$ and 1.73$\times$ DNN inference acceleration on CIFAR-10 and ImageNet dataset without accuracy loss.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021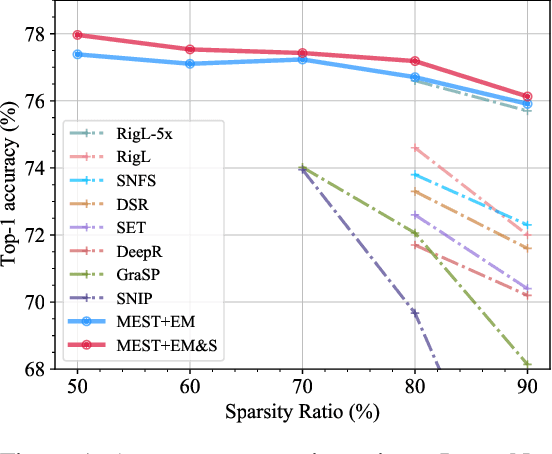
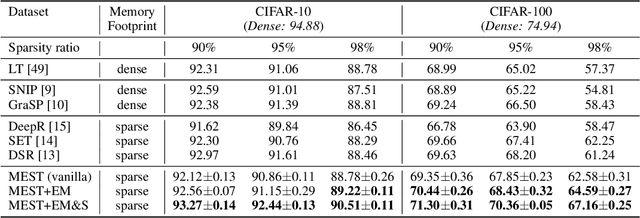
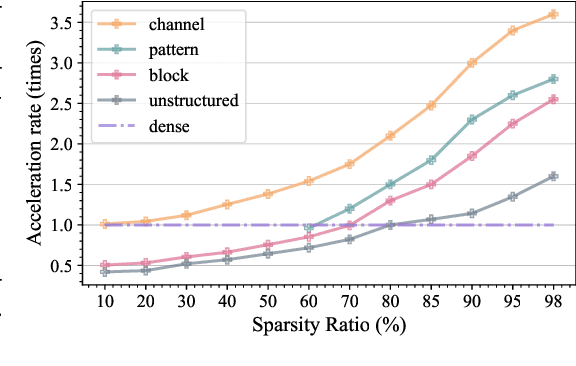
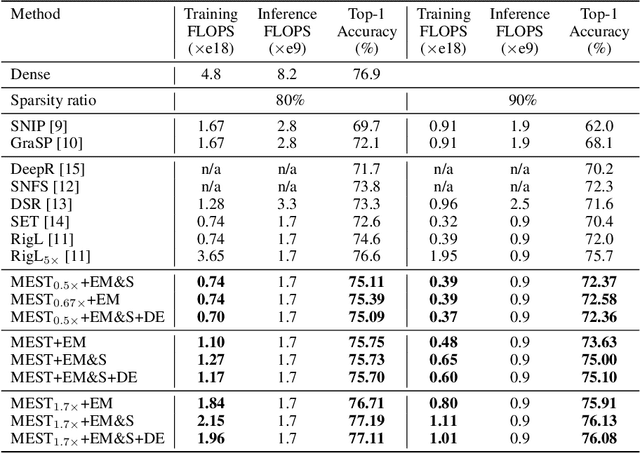
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
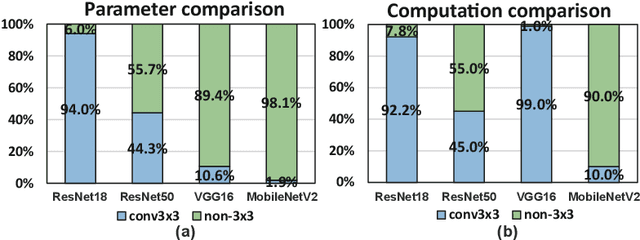
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021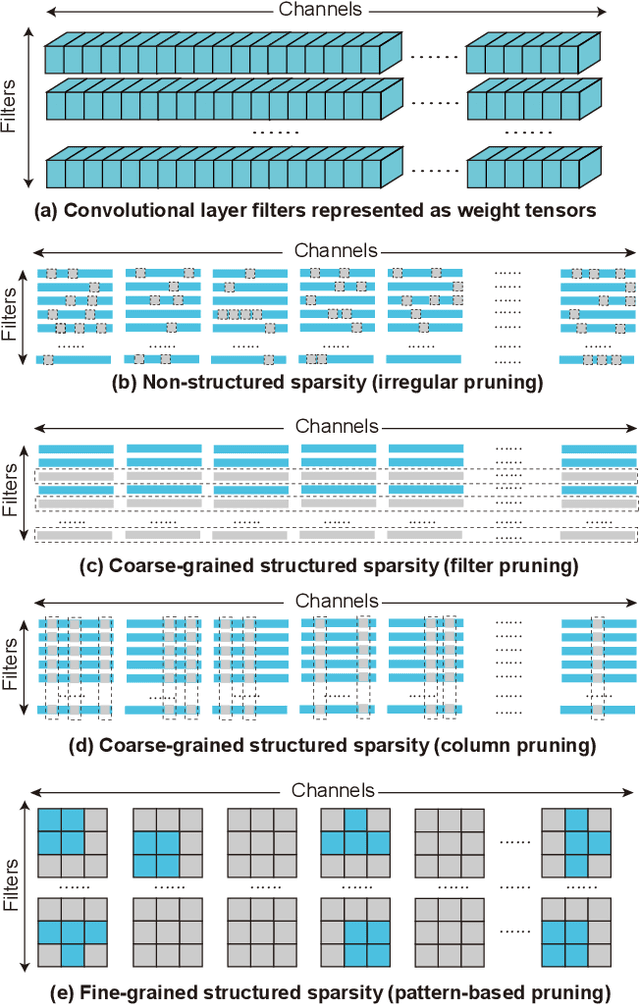
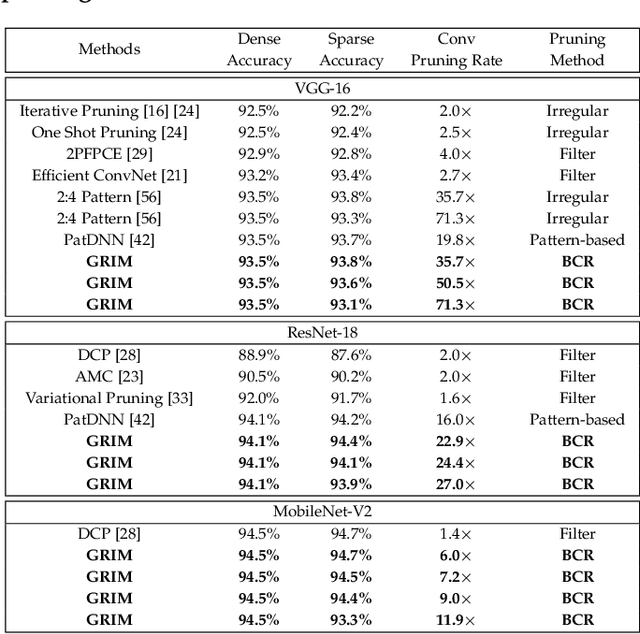
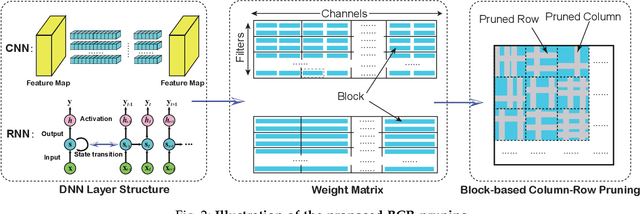
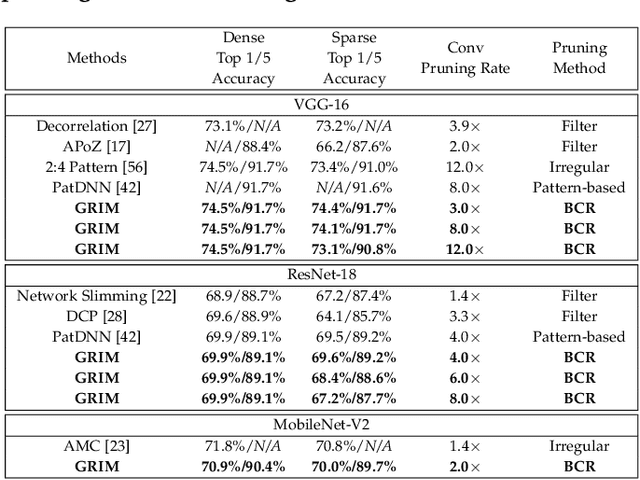
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
Improving DNN Fault Tolerance using Weight Pruning and Differential Crossbar Mapping for ReRAM-based Edge AI
Jun 18, 2021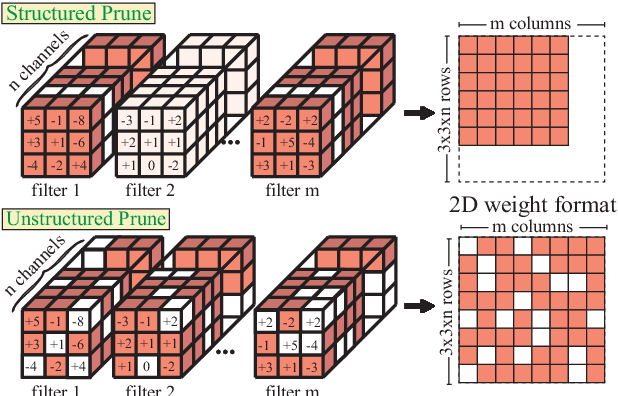
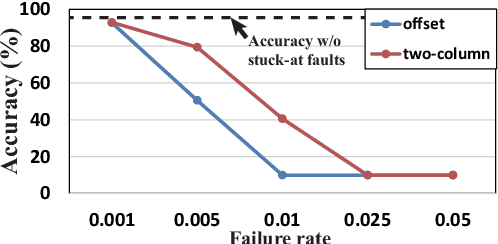
Recent research demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in deep neural networks (DNNs). However, hardware failure, such as stuck-at-fault defects, is one of the main concerns that impedes the ReRAM devices to be a feasible solution for real implementations. The existing solutions to address this issue usually require an optimization to be conducted for each individual device, which is impractical for mass-produced products (e.g., IoT devices). In this paper, we rethink the value of weight pruning in ReRAM-based DNN design from the perspective of model fault tolerance. And a differential mapping scheme is proposed to improve the fault tolerance under a high stuck-on fault rate. Our method can tolerate almost an order of magnitude higher failure rate than the traditional two-column method in representative DNN tasks. More importantly, our method does not require extra hardware cost compared to the traditional two-column mapping scheme. The improvement is universal and does not require the optimization process for each individual device.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021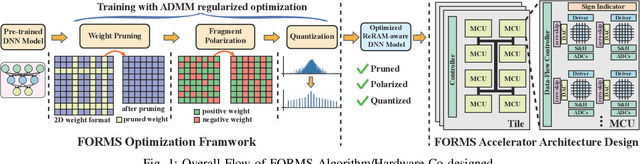
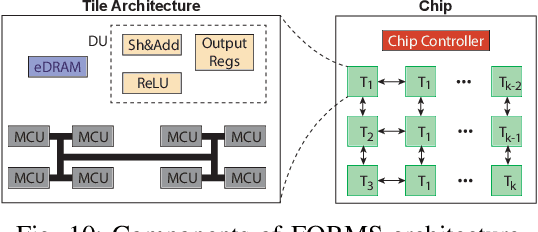
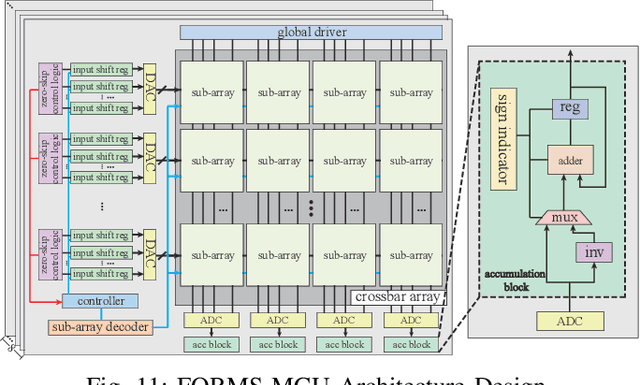

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.
Towards Fast and Accurate Multi-Person Pose Estimation on Mobile Devices
Jun 06, 2021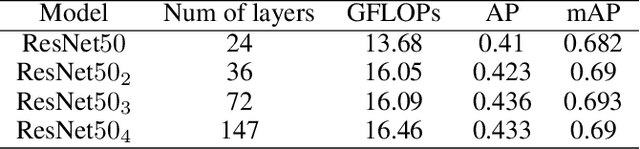


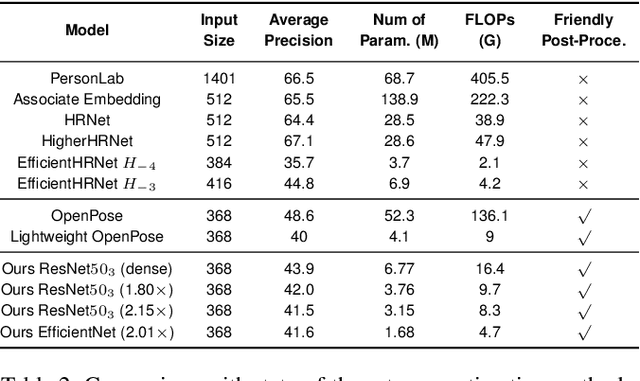
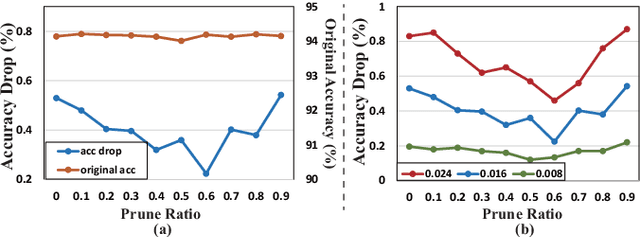
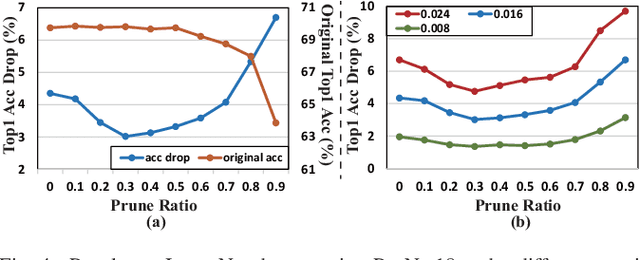
The rapid development of autonomous driving, abnormal behavior detection, and behavior recognition makes an increasing demand for multi-person pose estimation-based applications, especially on mobile platforms. However, to achieve high accuracy, state-of-the-art methods tend to have a large model size and complex post-processing algorithm, which costs intense computation and long end-to-end latency. To solve this problem, we propose an architecture optimization and weight pruning framework to accelerate inference of multi-person pose estimation on mobile devices. With our optimization framework, we achieve up to 2.51x faster model inference speed with higher accuracy compared to representative lightweight multi-person pose estimator.
6.7ms on Mobile with over 78% ImageNet Accuracy: Unified Network Pruning and Architecture Search for Beyond Real-Time Mobile Acceleration
Dec 01, 2020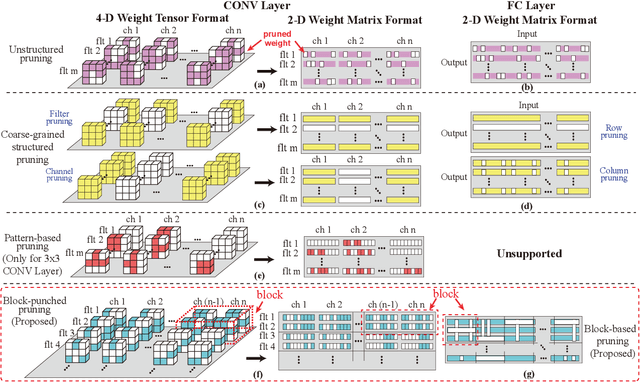
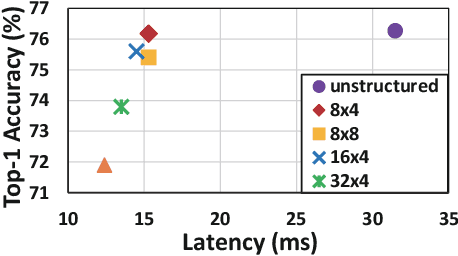
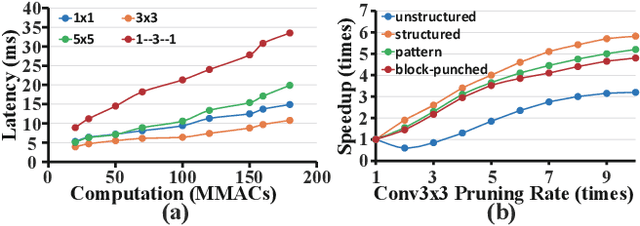
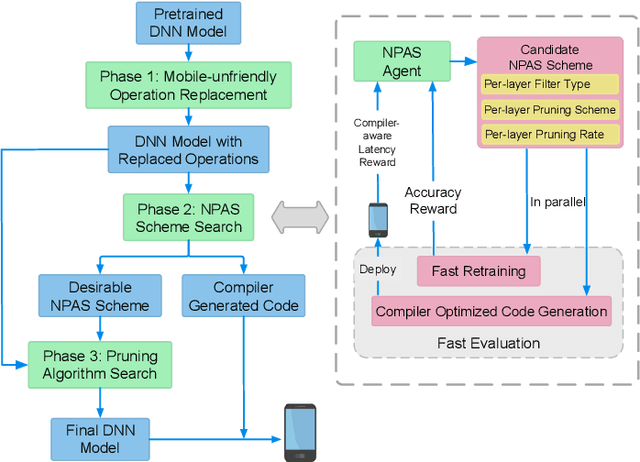
With the increasing demand to efficiently deploy DNNs on mobile edge devices, it becomes much more important to reduce unnecessary computation and increase the execution speed. Prior methods towards this goal, including model compression and network architecture search (NAS), are largely performed independently and do not fully consider compiler-level optimizations which is a must-do for mobile acceleration. In this work, we first propose (i) a general category of fine-grained structured pruning applicable to various DNN layers, and (ii) a comprehensive, compiler automatic code generation framework supporting different DNNs and different pruning schemes, which bridge the gap of model compression and NAS. We further propose NPAS, a compiler-aware unified network pruning, and architecture search. To deal with large search space, we propose a meta-modeling procedure based on reinforcement learning with fast evaluation and Bayesian optimization, ensuring the total number of training epochs comparable with representative NAS frameworks. Our framework achieves 6.7ms, 5.9ms, 3.9ms ImageNet inference times with 78.2%, 75% (MobileNet-V3 level), and 71% (MobileNet-V2 level) Top-1 accuracy respectively on an off-the-shelf mobile phone, consistently outperforming prior work.
Efficient Transformer-based Large Scale Language Representations using Hardware-friendly Block Structured Pruning
Oct 08, 2020
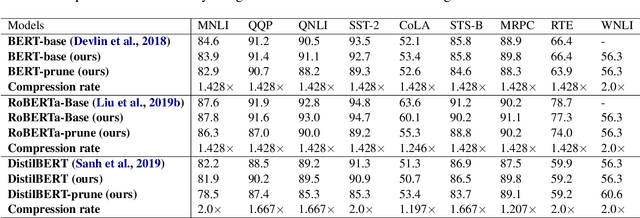
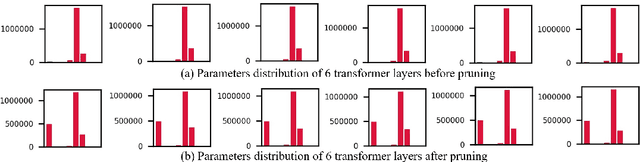
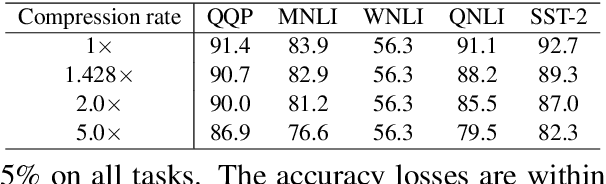
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this work, we propose an efficient transformer-based large-scale language representation using hardware-friendly block structure pruning. We incorporate the reweighted group Lasso into block-structured pruning for optimization. Besides the significantly reduced weight storage and computation, the proposed approach achieves high compression rates. Experimental results on different models (BERT, RoBERTa, and DistilBERT) on the General Language Understanding Evaluation (GLUE) benchmark tasks show that we achieve up to 5.0x with zero or minor accuracy degradation on certain task(s). Our proposed method is also orthogonal to existing compact pre-trained language models such as DistilBERT using knowledge distillation, since a further 1.79x average compression rate can be achieved on top of DistilBERT with zero or minor accuracy degradation. It is suitable to deploy the final compressed model on resource-constrained edge devices.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020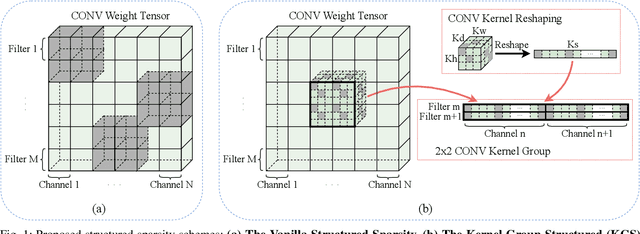
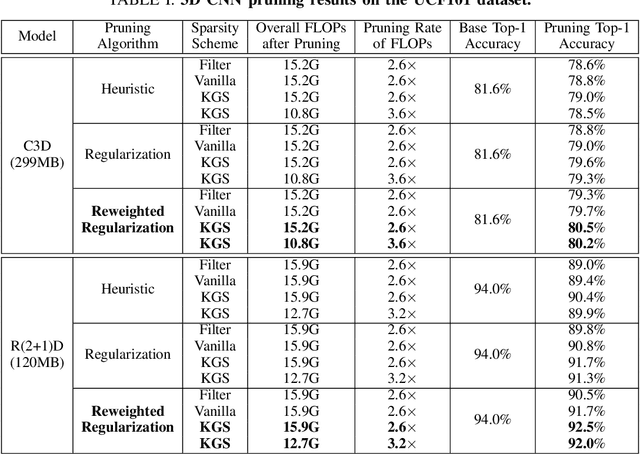
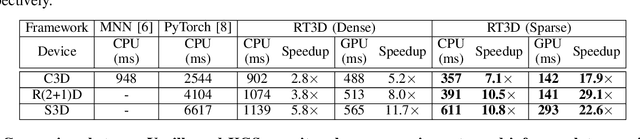

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.
A Privacy-Preserving DNN Pruning and Mobile Acceleration Framework
Mar 13, 2020
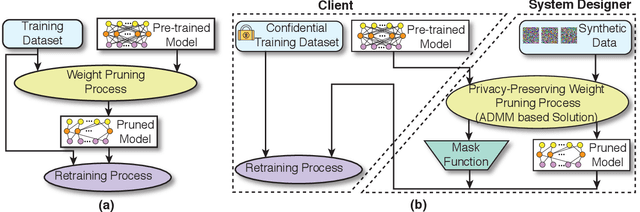
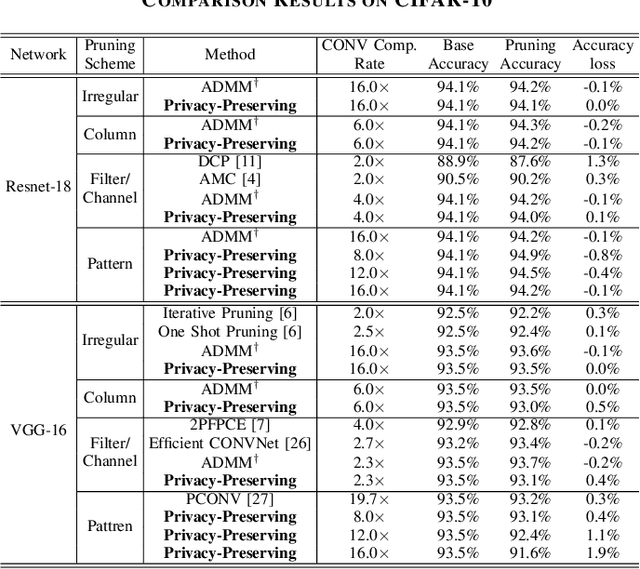
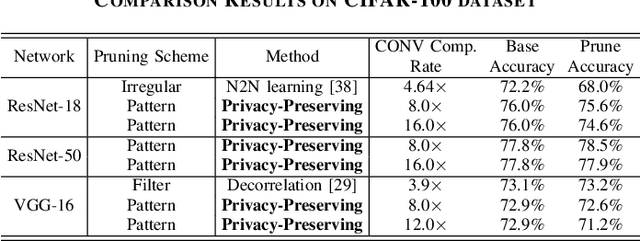
To facilitate the deployment of deep neural networks (DNNs) on resource-constrained computing systems, DNN model compression methods have been proposed. However, previous methods mainly focus on reducing the model size and/or improving hardware performance, without considering the data privacy requirement. This paper proposes a privacy-preserving model compression framework that formulates a privacy-preserving DNN weight pruning problem and develops an ADMM based solution to support different weight pruning schemes. We consider the case that the system designer will perform weight pruning on a pre-trained model provided by the client, whereas the client cannot share her confidential training dataset. To mitigate the non-availability of the training dataset, the system designer distills the knowledge of a pre-trained model into a pruned model using only randomly generated synthetic data. Then the client's effort is simply reduced to performing the retraining process using her confidential training dataset, which is similar as the DNN training process with the help of the mask function from the system designer. Both algorithmic and hardware experiments validate the effectiveness of the proposed framework.