 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Invariant Transformer for Point Cloud Matching
Mar 25, 2023



The intrinsic rotation invariance lies at the core of matching point clouds with handcrafted descriptors. However, it is widely despised by recent deep matchers that obtain the rotation invariance extrinsically via data augmentation. As the finite number of augmented rotations can never span the continuous SO(3) space, these methods usually show instability when facing rotations that are rarely seen. To this end, we introduce RoITr, a Rotation-Invariant Transformer to cope with the pose variations in the point cloud matching task. We contribute both on the local and global levels. Starting from the local level, we introduce an attention mechanism embedded with Point Pair Feature (PPF)-based coordinates to describe the pose-invariant geometry, upon which a novel attention-based encoder-decoder architecture is constructed. We further propose a global transformer with rotation-invariant cross-frame spatial awareness learned by the self-attention mechanism, which significantly improves the feature distinctiveness and makes the model robust with respect to the low overlap. Experiments are conducted on both the rigid and non-rigid public benchmarks, where RoITr outperforms all the state-of-the-art models by a considerable margin in the low-overlapping scenarios. Especially when the rotations are enlarged on the challenging 3DLoMatch benchmark, RoITr surpasses the existing methods by at least 13 and 5 percentage points in terms of Inlier Ratio and Registration Recall, respectively.
MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking
Mar 18, 2023



The main challenge of Multi-Object Tracking~(MOT) lies in maintaining a continuous trajectory for each target. Existing methods often learn reliable motion patterns to match the same target between adjacent frames and discriminative appearance features to re-identify the lost targets after a long period. However, the reliability of motion prediction and the discriminability of appearances can be easily hurt by dense crowds and extreme occlusions in the tracking process. In this paper, we propose a simple yet effective multi-object tracker, i.e., MotionTrack, which learns robust short-term and long-term motions in a unified framework to associate trajectories from a short to long range. For dense crowds, we design a novel Interaction Module to learn interaction-aware motions from short-term trajectories, which can estimate the complex movement of each target. For extreme occlusions, we build a novel Refind Module to learn reliable long-term motions from the target's history trajectory, which can link the interrupted trajectory with its corresponding detection. Our Interaction Module and Refind Module are embedded in the well-known tracking-by-detection paradigm, which can work in tandem to maintain superior performance. Extensive experimental results on MOT17 and MOT20 datasets demonstrate the superiority of our approach in challenging scenarios, and it achieves state-of-the-art performances at various MOT metrics.
Deep Graph-based Spatial Consistency for Robust Non-rigid Point Cloud Registration
Mar 17, 2023



We study the problem of outlier correspondence pruning for non-rigid point cloud registration. In rigid registration, spatial consistency has been a commonly used criterion to discriminate outliers from inliers. It measures the compatibility of two correspondences by the discrepancy between the respective distances in two point clouds. However, spatial consistency no longer holds in non-rigid cases and outlier rejection for non-rigid registration has not been well studied. In this work, we propose Graph-based Spatial Consistency Network (GraphSCNet) to filter outliers for non-rigid registration. Our method is based on the fact that non-rigid deformations are usually locally rigid, or local shape preserving. We first design a local spatial consistency measure over the deformation graph of the point cloud, which evaluates the spatial compatibility only between the correspondences in the vicinity of a graph node. An attention-based non-rigid correspondence embedding module is then devised to learn a robust representation of non-rigid correspondences from local spatial consistency. Despite its simplicity, GraphSCNet effectively improves the quality of the putative correspondences and attains state-of-the-art performance on three challenging benchmarks. Our code and models are available at https://github.com/qinzheng93/GraphSCNet.
Learning Accurate Template Matching with Differentiable Coarse-to-Fine Correspondence Refinement
Mar 15, 2023Template matching is a fundamental task in computer vision and has been studied for decades. It plays an essential role in manufacturing industry for estimating the poses of different parts, facilitating downstream tasks such as robotic grasping. Existing methods fail when the template and source images have different modalities, cluttered backgrounds or weak textures. They also rarely consider geometric transformations via homographies, which commonly exist even for planar industrial parts. To tackle the challenges, we propose an accurate template matching method based on differentiable coarse-to-fine correspondence refinement. We use an edge-aware module to overcome the domain gap between the mask template and the grayscale image, allowing robust matching. An initial warp is estimated using coarse correspondences based on novel structure-aware information provided by transformers. This initial alignment is passed to a refinement network using references and aligned images to obtain sub-pixel level correspondences which are used to give the final geometric transformation. Extensive evaluation shows that our method is significantly better than state-of-the-art methods and baselines, providing good generalization ability and visually plausible results even on unseen real data.
DeepfakeMAE: Facial Part Consistency Aware Masked Autoencoder for Deepfake Video Detection
Mar 03, 2023



Deepfake techniques have been used maliciously, resulting in strong research interests in developing Deepfake detection methods. Deepfake often manipulates the video content by tampering with some facial parts. However, this manipulation usually breaks the consistency among facial parts, e.g., Deepfake may change smiling lips to upset, but the eyes are still smiling. Existing works propose to spot inconsistency on some specific facial parts (e.g., lips), but they may perform poorly if new Deepfake techniques focus on the specific facial parts used by the detector. Thus, this paper proposes a new Deepfake detection model, DeepfakeMAE, which can utilize the consistencies among all facial parts. Specifically, given a real face image, we first pretrain a masked autoencoder to learn facial part consistency by randomly masking some facial parts and reconstructing missing areas based on the remaining facial parts. Furthermore, to maximize the discrepancy between real and fake videos, we propose a novel model with dual networks that utilize the pretrained encoder and decoder, respectively. 1) The pretrained encoder is finetuned for capturing the overall information of the given video. 2) The pretrained decoder is utilized for distinguishing real and fake videos based on the motivation that DeepfakeMAE's reconstruction should be more similar to a real face image than a fake one. Our extensive experiments on standard benchmarks demonstrate that DeepfakeMAE is highly effective and especially outperforms the previous state-of-the-art method by 3.1% AUC on average in cross-dataset detection.
Task-Specific Context Decoupling for Object Detection
Mar 02, 2023



Classification and localization are two main sub-tasks in object detection. Nonetheless, these two tasks have inconsistent preferences for feature context, i.e., localization expects more boundary-aware features to accurately regress the bounding box, while more semantic context is preferred for object classification. Exsiting methods usually leverage disentangled heads to learn different feature context for each task. However, the heads are still applied on the same input features, which leads to an imperfect balance between classifcation and localization. In this work, we propose a novel Task-Specific COntext DEcoupling (TSCODE) head which further disentangles the feature encoding for two tasks. For classification, we generate spatially-coarse but semantically-strong feature encoding. For localization, we provide high-resolution feature map containing more edge information to better regress object boundaries. TSCODE is plug-and-play and can be easily incorperated into existing detection pipelines. Extensive experiments demonstrate that our method stably improves different detectors by over 1.0 AP with less computational cost. Our code and models will be publicly released.
RIGA: Rotation-Invariant and Globally-Aware Descriptors for Point Cloud Registration
Sep 27, 2022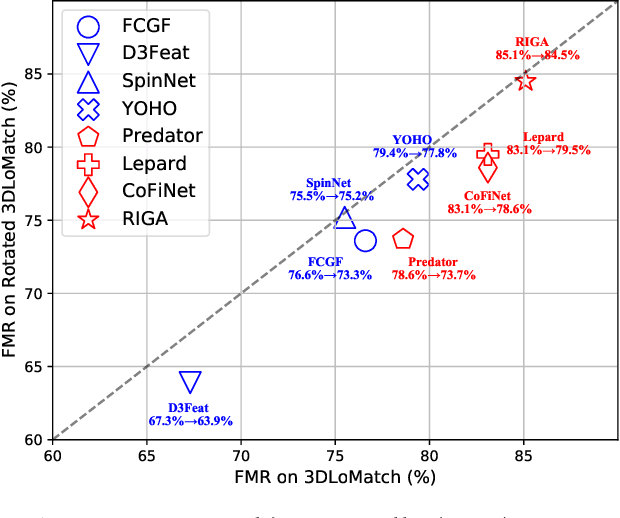
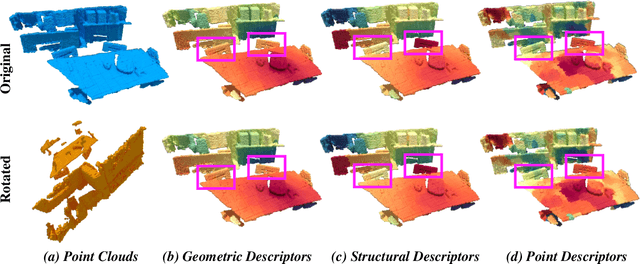
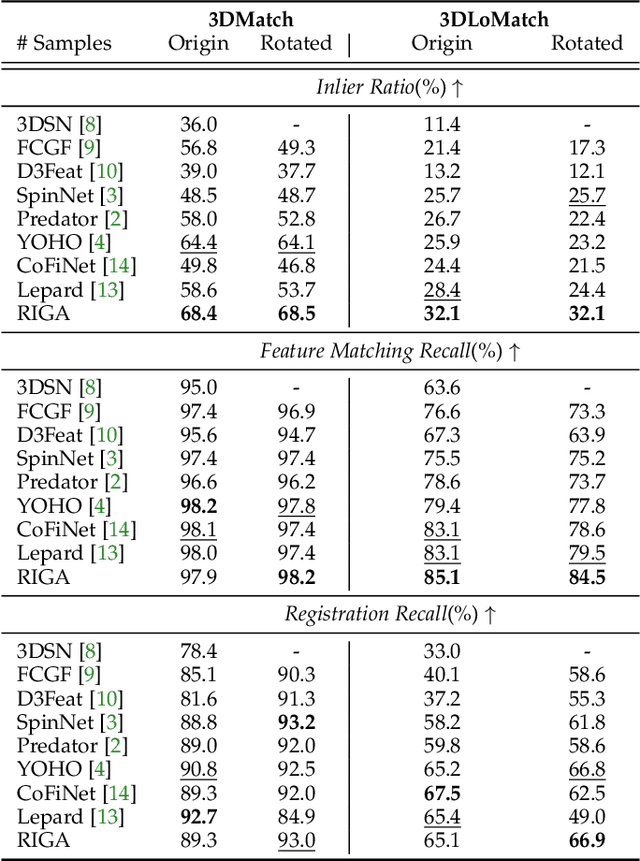
Successful point cloud registration relies on accurate correspondences established upon powerful descriptors. However, existing neural descriptors either leverage a rotation-variant backbone whose performance declines under large rotations, or encode local geometry that is less distinctive. To address this issue, we introduce RIGA to learn descriptors that are Rotation-Invariant by design and Globally-Aware. From the Point Pair Features (PPFs) of sparse local regions, rotation-invariant local geometry is encoded into geometric descriptors. Global awareness of 3D structures and geometric context is subsequently incorporated, both in a rotation-invariant fashion. More specifically, 3D structures of the whole frame are first represented by our global PPF signatures, from which structural descriptors are learned to help geometric descriptors sense the 3D world beyond local regions. Geometric context from the whole scene is then globally aggregated into descriptors. Finally, the description of sparse regions is interpolated to dense point descriptors, from which correspondences are extracted for registration. To validate our approach, we conduct extensive experiments on both object- and scene-level data. With large rotations, RIGA surpasses the state-of-the-art methods by a margin of 8\degree in terms of the Relative Rotation Error on ModelNet40 and improves the Feature Matching Recall by at least 5 percentage points on 3DLoMatch.
Unsupervised Voice-Face Representation Learning by Cross-Modal Prototype Contrast
May 02, 2022
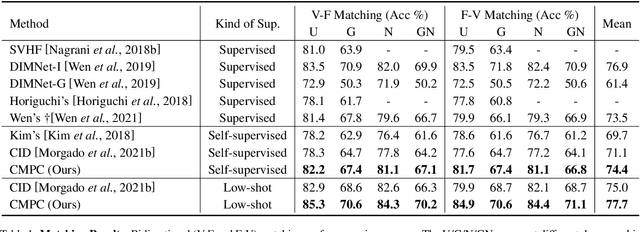
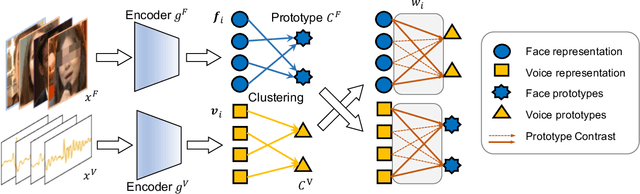
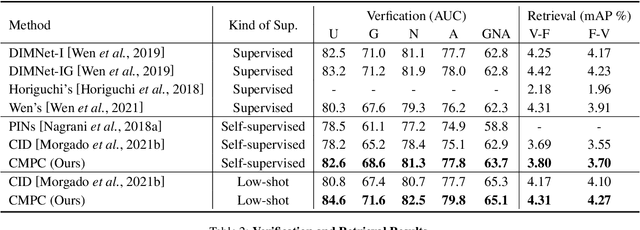
We present an approach to learn voice-face representations from the talking face videos, without any identity labels. Previous works employ cross-modal instance discrimination tasks to establish the correlation of voice and face. These methods neglect the semantic content of different videos, introducing false-negative pairs as training noise. Furthermore, the positive pairs are constructed based on the natural correlation between audio clips and visual frames. However, this correlation might be weak or inaccurate in a large amount of real-world data, which leads to deviating positives into the contrastive paradigm. To address these issues, we propose the cross-modal prototype contrastive learning (CMPC), which takes advantage of contrastive methods and resists adverse effects of false negatives and deviate positives. On one hand, CMPC could learn the intra-class invariance by constructing semantic-wise positives via unsupervised clustering in different modalities. On the other hand, by comparing the similarities of cross-modal instances from that of cross-modal prototypes, we dynamically recalibrate the unlearnable instances' contribution to overall loss. Experiments show that the proposed approach outperforms state-of-the-art unsupervised methods on various voice-face association evaluation protocols. Additionally, in the low-shot supervision setting, our method also has a significant improvement compared to previous instance-wise contrastive learning.
Geometric Transformer for Fast and Robust Point Cloud Registration
Mar 12, 2022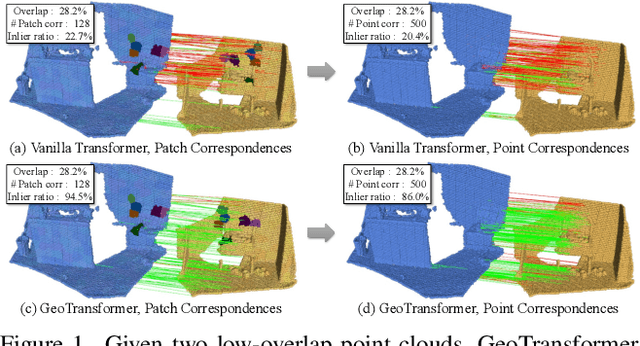
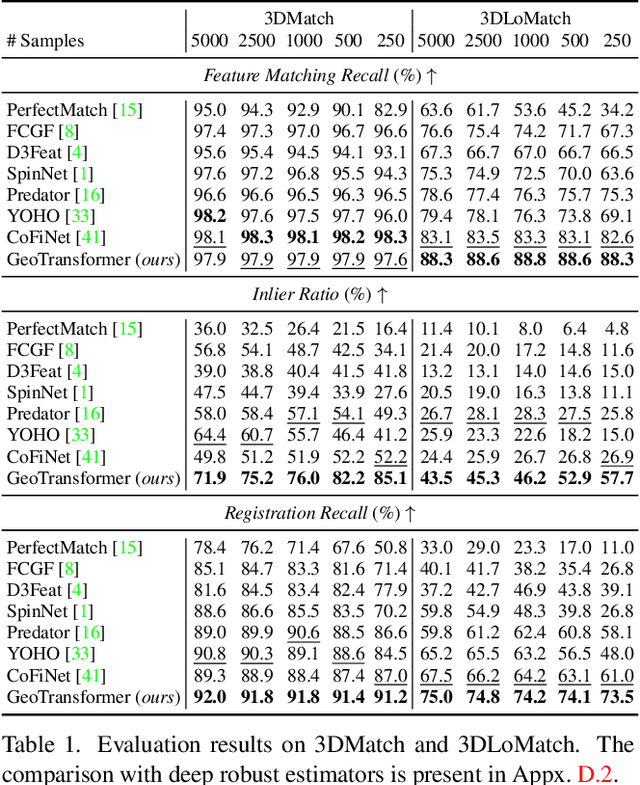
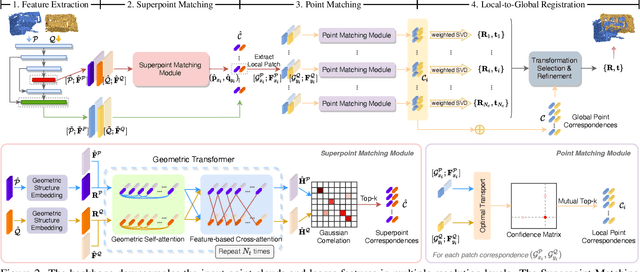
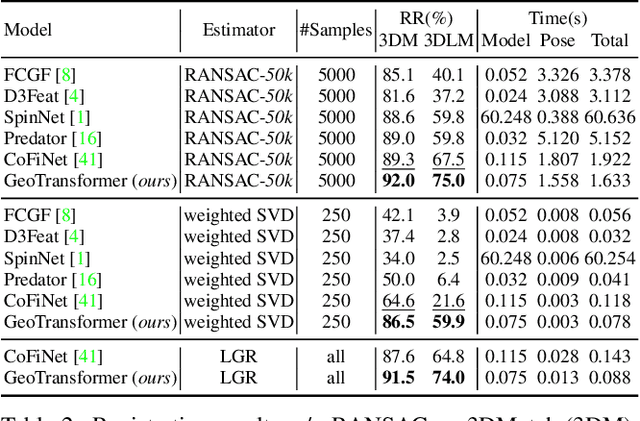
We study the problem of extracting accurate correspondences for point cloud registration. Recent keypoint-free methods bypass the detection of repeatable keypoints which is difficult in low-overlap scenarios, showing great potential in registration. They seek correspondences over downsampled superpoints, which are then propagated to dense points. Superpoints are matched based on whether their neighboring patches overlap. Such sparse and loose matching requires contextual features capturing the geometric structure of the point clouds. We propose Geometric Transformer to learn geometric feature for robust superpoint matching. It encodes pair-wise distances and triplet-wise angles, making it robust in low-overlap cases and invariant to rigid transformation. The simplistic design attains surprisingly high matching accuracy such that no RANSAC is required in the estimation of alignment transformation, leading to $100$ times acceleration. Our method improves the inlier ratio by $17{\sim}30$ percentage points and the registration recall by over $7$ points on the challenging 3DLoMatch benchmark. Our code and models are available at \url{https://github.com/qinzheng93/GeoTransformer}.
A System for Efficiently Hunting for Cyber Threats in Computer Systems Using Threat Intelligence
Jan 17, 2021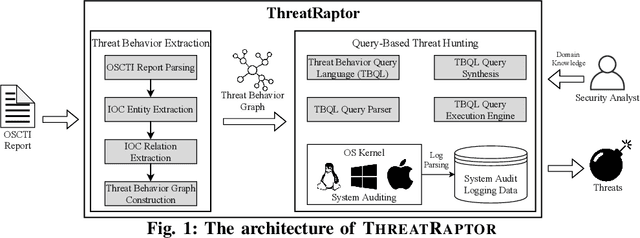


Log-based cyber threat hunting has emerged as an important solution to counter sophisticated cyber attacks. However, existing approaches require non-trivial efforts of manual query construction and have overlooked the rich external knowledge about threat behaviors provided by open-source Cyber Threat Intelligence (OSCTI). To bridge the gap, we build ThreatRaptor, a system that facilitates cyber threat hunting in computer systems using OSCTI. Built upon mature system auditing frameworks, ThreatRaptor provides (1) an unsupervised, light-weight, and accurate NLP pipeline that extracts structured threat behaviors from unstructured OSCTI text, (2) a concise and expressive domain-specific query language, TBQL, to hunt for malicious system activities, (3) a query synthesis mechanism that automatically synthesizes a TBQL query from the extracted threat behaviors, and (4) an efficient query execution engine to search the big system audit logging data.