 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFGC 2021: A DeepFake Game Competition
Jun 02, 2021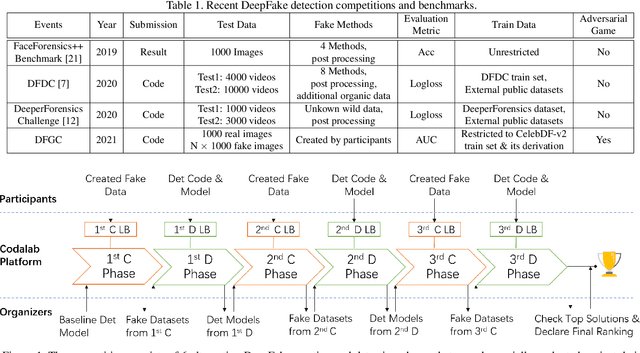
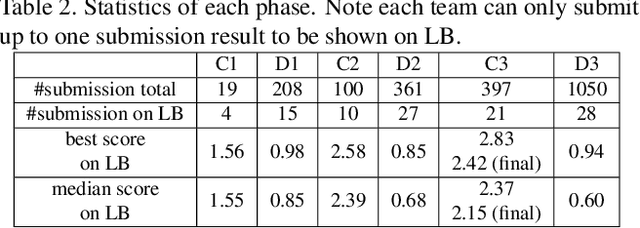
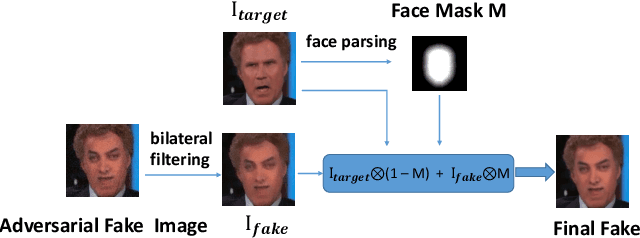
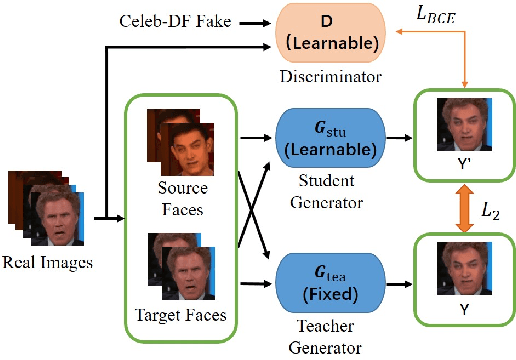
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
One Shot Face Swapping on Megapixels
May 11, 2021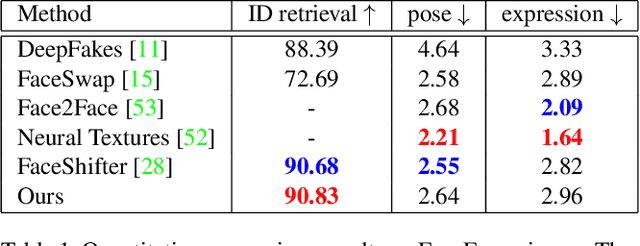
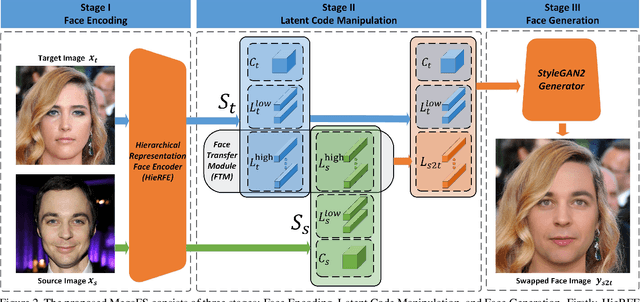

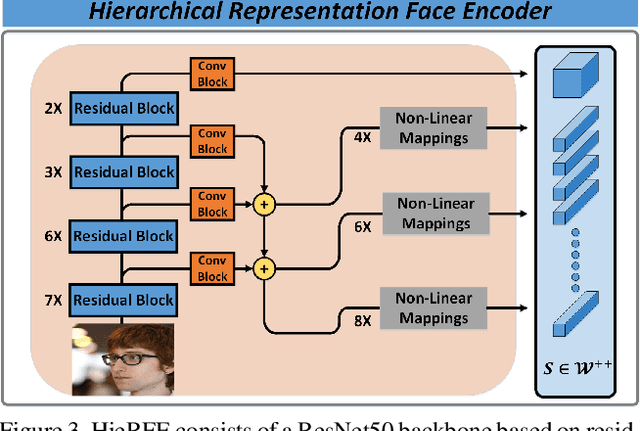
Face swapping has both positive applications such as entertainment, human-computer interaction, etc., and negative applications such as DeepFake threats to politics, economics, etc. Nevertheless, it is necessary to understand the scheme of advanced methods for high-quality face swapping and generate enough and representative face swapping images to train DeepFake detection algorithms. This paper proposes the first Megapixel level method for one shot Face Swapping (or MegaFS for short). Firstly, MegaFS organizes face representation hierarchically by the proposed Hierarchical Representation Face Encoder (HieRFE) in an extended latent space to maintain more facial details, rather than compressed representation in previous face swapping methods. Secondly, a carefully designed Face Transfer Module (FTM) is proposed to transfer the identity from a source image to the target by a non-linear trajectory without explicit feature disentanglement. Finally, the swapped faces can be synthesized by StyleGAN2 with the benefits of its training stability and powerful generative capability. Each part of MegaFS can be trained separately so the requirement of our model for GPU memory can be satisfied for megapixel face swapping. In summary, complete face representation, stable training, and limited memory usage are the three novel contributions to the success of our method. Extensive experiments demonstrate the superiority of MegaFS and the first megapixel level face swapping database is released for research on DeepFake detection and face image editing in the public domain. The dataset is at this link.
CASIA-Face-Africa: A Large-scale African Face Image Database
May 11, 2021
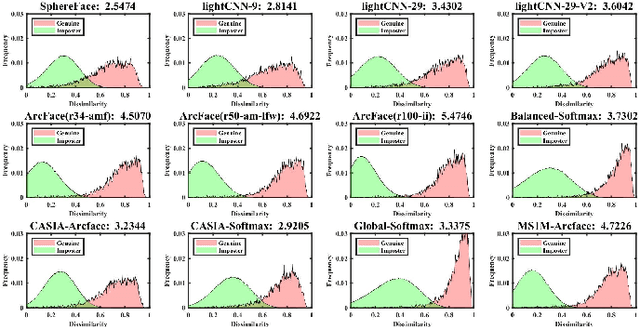
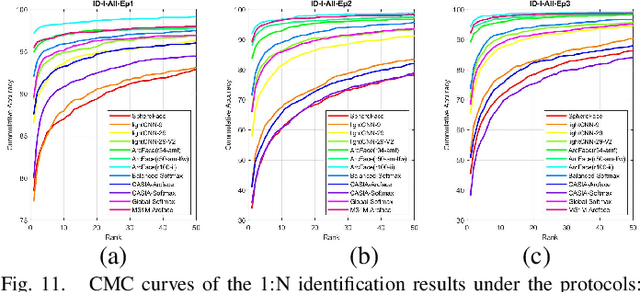

Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our http://www.cripacsir.cn/dataset/
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021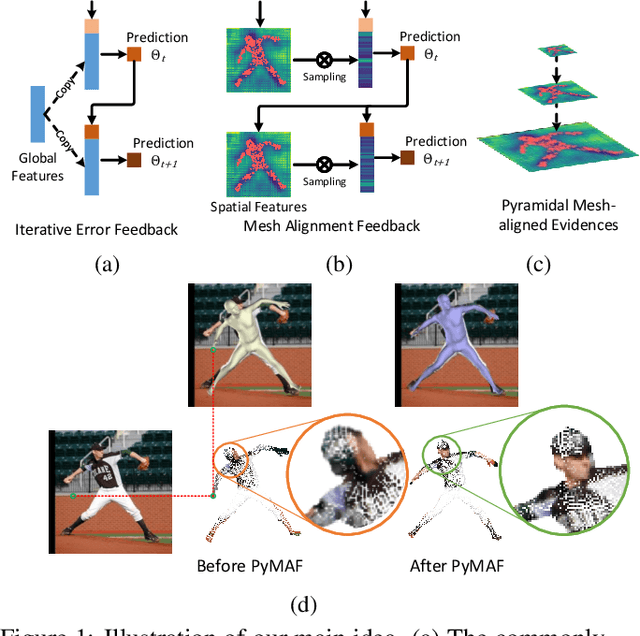
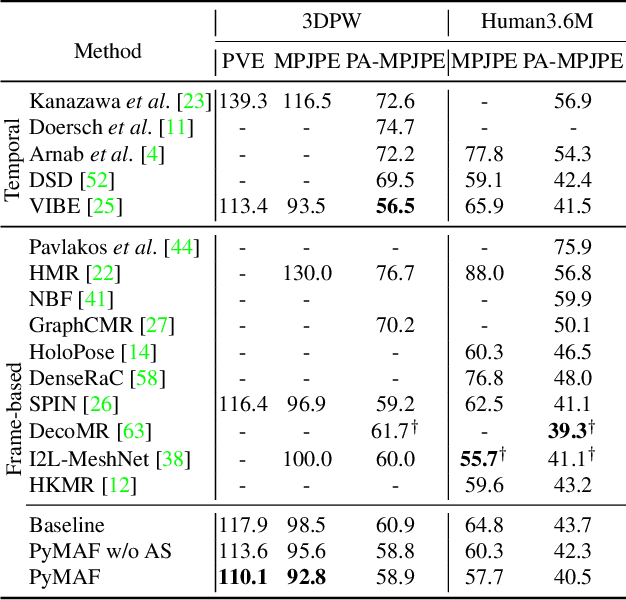
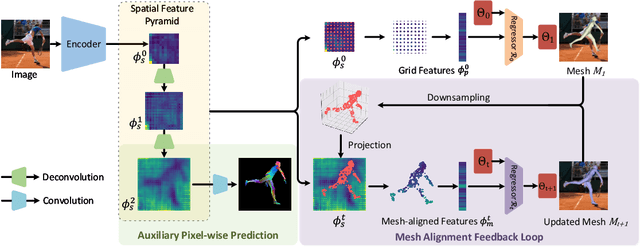
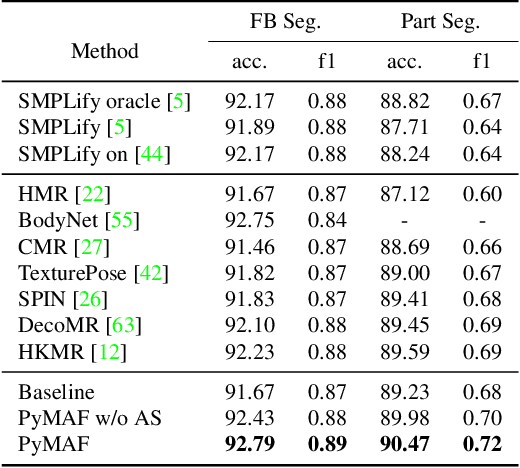
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .
ReMix: Towards Image-to-Image Translation with Limited Data
Mar 31, 2021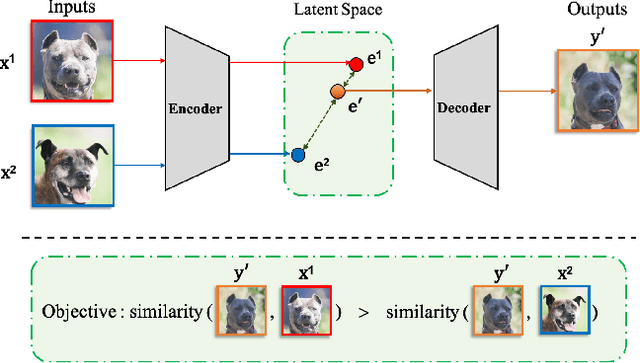
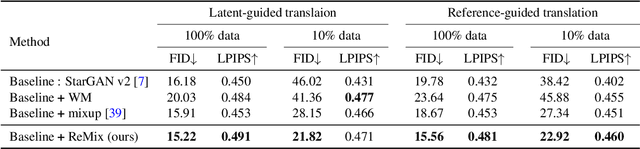
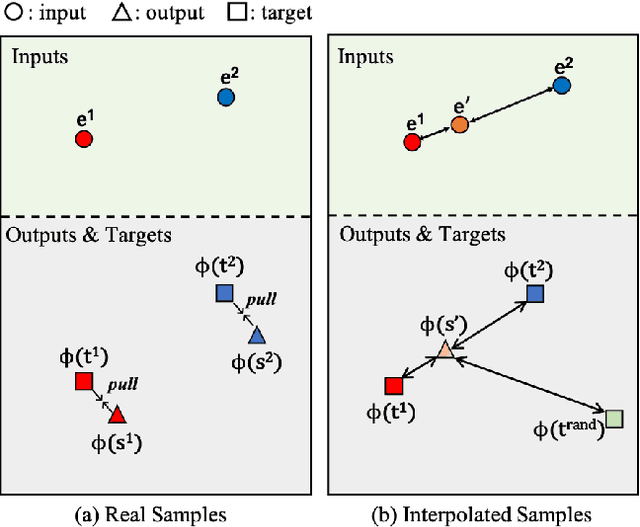
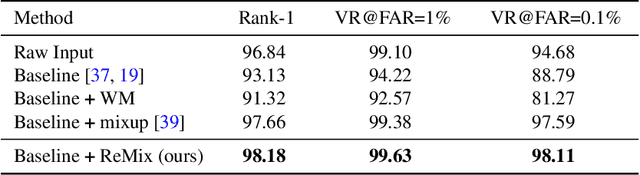
Image-to-image (I2I) translation methods based on generative adversarial networks (GANs) typically suffer from overfitting when limited training data is available. In this work, we propose a data augmentation method (ReMix) to tackle this issue. We interpolate training samples at the feature level and propose a novel content loss based on the perceptual relations among samples. The generator learns to translate the in-between samples rather than memorizing the training set, and thereby forces the discriminator to generalize. The proposed approach effectively reduces the ambiguity of generation and renders content-preserving results. The ReMix method can be easily incorporated into existing GAN models with minor modifications. Experimental results on numerous tasks demonstrate that GAN models equipped with the ReMix method achieve significant improvements.
All-in-Focus Iris Camera With a Great Capture Volume
Nov 19, 2020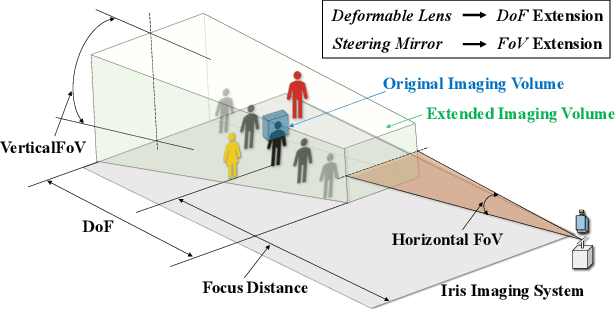
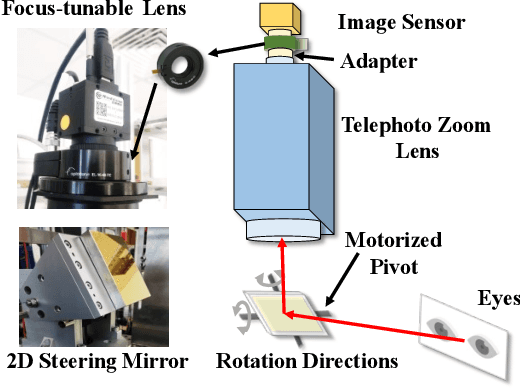
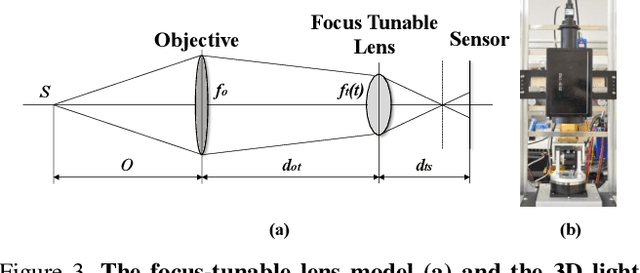
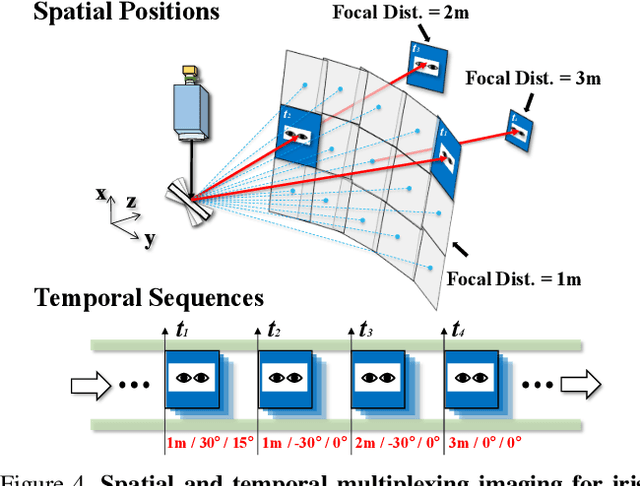
Imaging volume of an iris recognition system has been restricting the throughput and cooperation convenience in biometric applications. Numerous improvement trials are still impractical to supersede the dominant fixed-focus lens in stand-off iris recognition due to incremental performance increase and complicated optical design. In this study, we develop a novel all-in-focus iris imaging system using a focus-tunable lens and a 2D steering mirror to greatly extend capture volume by spatiotemporal multiplexing method. Our iris imaging depth of field extension system requires no mechanical motion and is capable to adjust the focal plane at extremely high speed. In addition, the motorized reflection mirror adaptively steers the light beam to extend the horizontal and vertical field of views in an active manner. The proposed all-in-focus iris camera increases the depth of field up to 3.9 m which is a factor of 37.5 compared with conventional long focal lens. We also experimentally demonstrate the capability of this 3D light beam steering imaging system in real-time multi-person iris refocusing using dynamic focal stacks and the potential of continuous iris recognition for moving participants.
Style Intervention: How to Achieve Spatial Disentanglement with Style-based Generators?
Nov 19, 2020


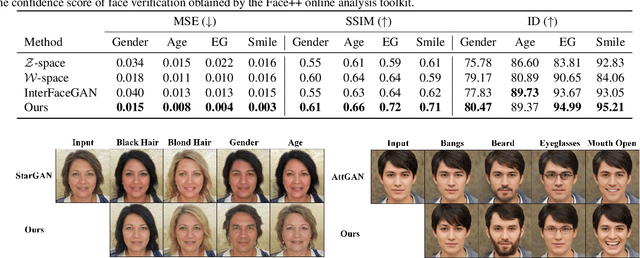
Generative Adversarial Networks (GANs) with style-based generators (e.g. StyleGAN) successfully enable semantic control over image synthesis, and recent studies have also revealed that interpretable image translations could be obtained by modifying the latent code. However, in terms of the low-level image content, traveling in the latent space would lead to `spatially entangled changes' in corresponding images, which is undesirable in many real-world applications where local editing is required. To solve this problem, we analyze properties of the 'style space' and explore the possibility of controlling the local translation with pre-trained style-based generators. Concretely, we propose 'Style Intervention', a lightweight optimization-based algorithm which could adapt to arbitrary input images and render natural translation effects under flexible objectives. We verify the performance of the proposed framework in facial attribute editing on high-resolution images, where both photo-realism and consistency are required. Extensive qualitative results demonstrate the effectiveness of our method, and quantitative measurements also show that the proposed algorithm outperforms state-of-the-art benchmarks in various aspects.
Recognition Oriented Iris Image Quality Assessment in the Feature Space
Sep 27, 2020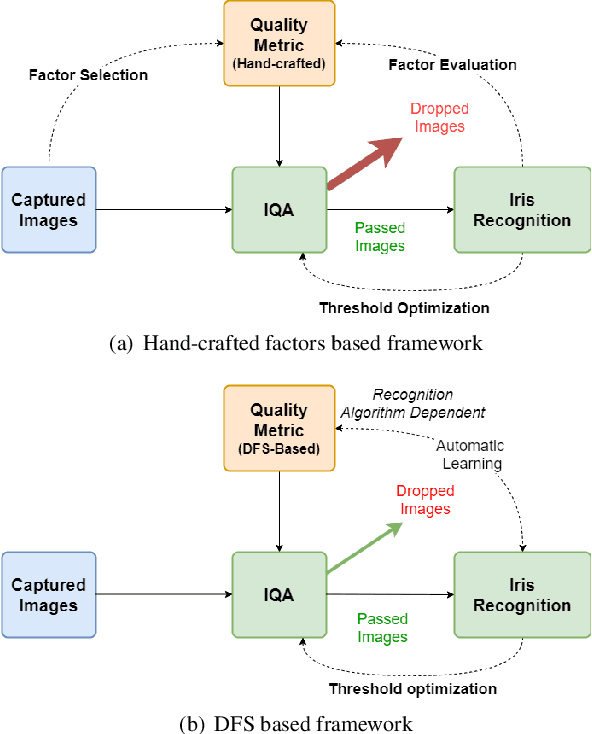
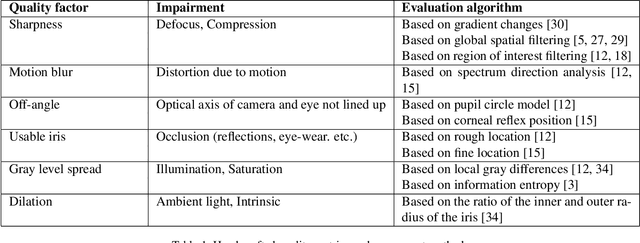
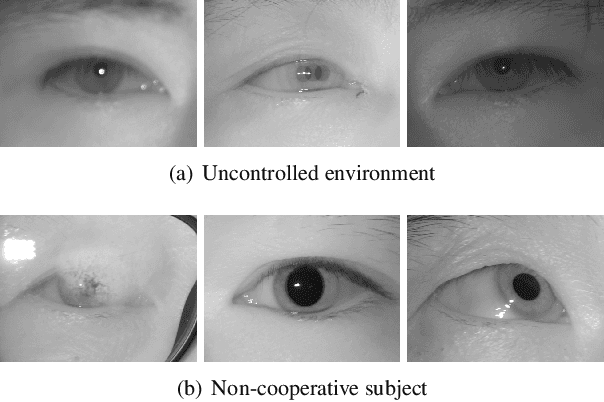
A large portion of iris images captured in real world scenarios are poor quality due to the uncontrolled environment and the non-cooperative subject. To ensure that the recognition algorithm is not affected by low-quality images, traditional hand-crafted factors based methods discard most images, which will cause system timeout and disrupt user experience. In this paper, we propose a recognition-oriented quality metric and assessment method for iris image to deal with the problem. The method regards the iris image embeddings Distance in Feature Space (DFS) as the quality metric and the prediction is based on deep neural networks with the attention mechanism. The quality metric proposed in this paper can significantly improve the performance of the recognition algorithm while reducing the number of images discarded for recognition, which is advantageous over hand-crafted factors based iris quality assessment methods. The relationship between Image Rejection Rate (IRR) and Equal Error Rate (EER) is proposed to evaluate the performance of the quality assessment algorithm under the same image quality distribution and the same recognition algorithm. Compared with hand-crafted factors based methods, the proposed method is a trial to bridge the gap between the image quality assessment and biometric recognition. The code is available at https://github.com/Debatrix/DFSNet.
Black Re-ID: A Head-shoulder Descriptor for the Challenging Problem of Person Re-Identification
Aug 19, 2020

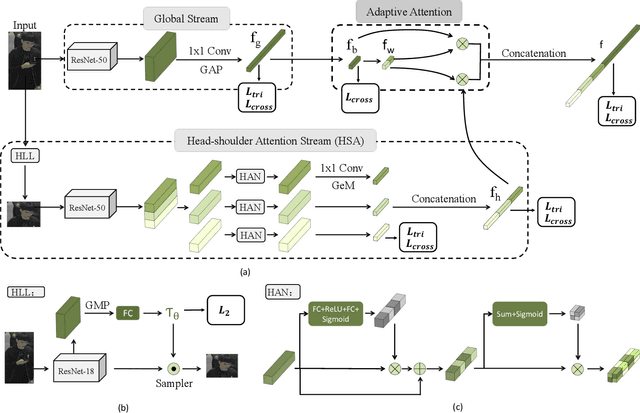
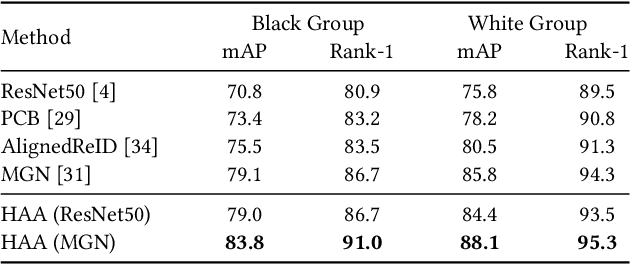
Person re-identification (Re-ID) aims at retrieving an input person image from a set of images captured by multiple cameras. Although recent Re-ID methods have made great success, most of them extract features in terms of the attributes of clothing (e.g., color, texture). However, it is common for people to wear black clothes or be captured by surveillance systems in low light illumination, in which cases the attributes of the clothing are severely missing. We call this problem the Black Re-ID problem. To solve this problem, rather than relying on the clothing information, we propose to exploit head-shoulder features to assist person Re-ID. The head-shoulder adaptive attention network (HAA) is proposed to learn the head-shoulder feature and an innovative ensemble method is designed to enhance the generalization of our model. Given the input person image, the ensemble method would focus on the head-shoulder feature by assigning a larger weight if the individual insides the image is in black clothing. Due to the lack of a suitable benchmark dataset for studying the Black Re-ID problem, we also contribute the first Black-reID dataset, which contains 1274 identities in training set. Extensive evaluations on the Black-reID, Market1501 and DukeMTMC-reID datasets show that our model achieves the best result compared with the state-of-the-art Re-ID methods on both Black and conventional Re-ID problems. Furthermore, our method is also proved to be effective in dealing with person Re-ID in similar clothing. Our code and dataset are avaliable on https://github.com/xbq1994/.
Reference Guided Face Component Editing
Jun 03, 2020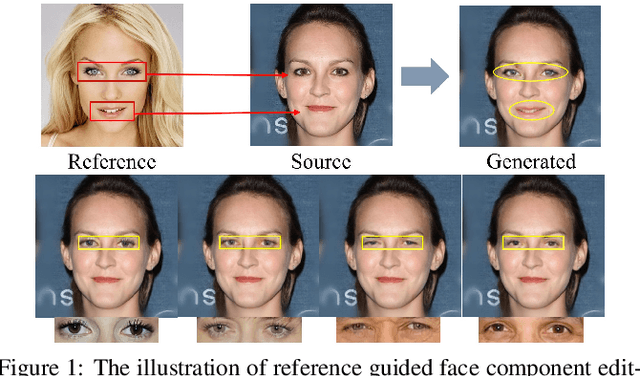
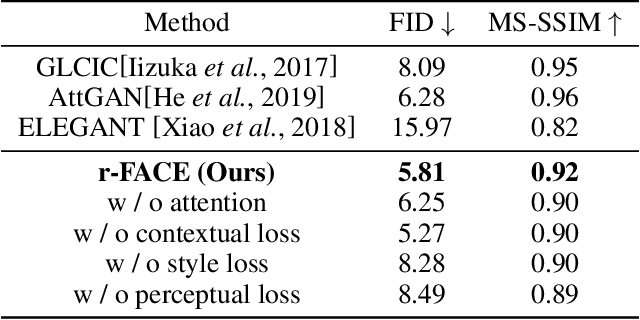

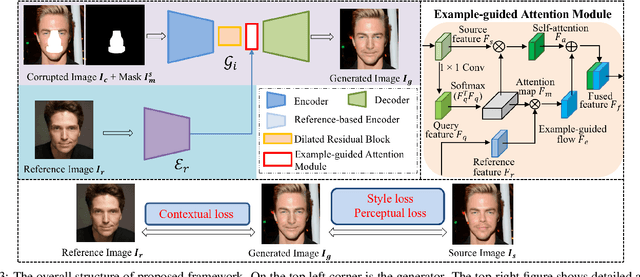
Face portrait editing has achieved great progress in recent years. However, previous methods either 1) operate on pre-defined face attributes, lacking the flexibility of controlling shapes of high-level semantic facial components (e.g., eyes, nose, mouth), or 2) take manually edited mask or sketch as an intermediate representation for observable changes, but such additional input usually requires extra efforts to obtain. To break the limitations (e.g. shape, mask or sketch) of the existing methods, we propose a novel framework termed r-FACE (Reference Guided FAce Component Editing) for diverse and controllable face component editing with geometric changes. Specifically, r-FACE takes an image inpainting model as the backbone, utilizing reference images as conditions for controlling the shape of face components. In order to encourage the framework to concentrate on the target face components, an example-guided attention module is designed to fuse attention features and the target face component features extracted from the reference image. Both qualitative and quantitative results demonstrate that our model is superior to existing literature.