 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA: xLSTM with Multihead Exponential Gated Fusion for Precise Aspect-based Sentiment Analysis
Jul 01, 2025Aspect-based Sentiment Analysis (ABSA) is a critical Natural Language Processing (NLP) task that extracts aspects from text and determines their associated sentiments, enabling fine-grained analysis of user opinions. Existing ABSA methods struggle to balance computational efficiency with high performance: deep learning models often lack global context, transformers demand significant computational resources, and Mamba-based approaches face CUDA dependency and diminished local correlations. Recent advancements in Extended Long Short-Term Memory (xLSTM) models, particularly their efficient modeling of long-range dependencies, have significantly advanced the NLP community. However, their potential in ABSA remains untapped. To this end, we propose xLSTM with Multihead Exponential Gated Fusion (MEGA), a novel framework integrating a bi-directional mLSTM architecture with forward and partially flipped backward (PF-mLSTM) streams. The PF-mLSTM enhances localized context modeling by processing the initial sequence segment in reverse with dedicated parameters, preserving critical short-range patterns. We further introduce an mLSTM-based multihead cross exponential gated fusion mechanism (MECGAF) that dynamically combines forward mLSTM outputs as query and key with PF-mLSTM outputs as value, optimizing short-range dependency capture while maintaining global context and efficiency. Experimental results on three benchmark datasets demonstrate that MEGA outperforms state-of-the-art baselines, achieving superior accuracy and efficiency in ABSA tasks.
CASIA-Iris-Africa: A Large-scale African Iris Image Database
Feb 25, 2023



Iris biometrics is a phenotypic biometric trait that has proven to be agnostic to human natural physiological changes. Research on iris biometrics has progressed tremendously, partly due to publicly available iris databases. Various databases have been available to researchers that address pressing iris biometric challenges such as constraint, mobile, multispectral, synthetics, long-distance, contact lenses, liveness detection, etc. However, these databases mostly contain subjects of Caucasian and Asian docents with very few Africans. Despite many investigative studies on racial bias in face biometrics, very few studies on iris biometrics have been published, mainly due to the lack of racially diverse large-scale databases containing sufficient iris samples of Africans in the public domain. Furthermore, most of these databases contain a relatively small number of subjects and labelled images. This paper proposes a large-scale African database named CASIA-Iris-Africa that can be used as a complementary database for the iris recognition community to mediate the effect of racial biases on Africans. The database contains 28,717 images of 1023 African subjects (2046 iris classes) with age, gender, and ethnicity attributes that can be useful in demographically sensitive studies of Africans. Sets of specific application protocols are incorporated with the database to ensure the database's variability and scalability. Performance results of some open-source SOTA algorithms on the database are presented, which will serve as baseline performances. The relatively poor performances of the baseline algorithms on the proposed database despite better performance on other databases prove that racial biases exist in these iris recognition algorithms. The database will be made available on our website: http://www.idealtest.org.
CASIA-Face-Africa: A Large-scale African Face Image Database
May 11, 2021
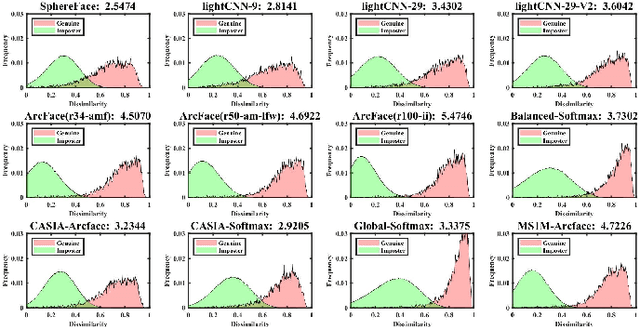
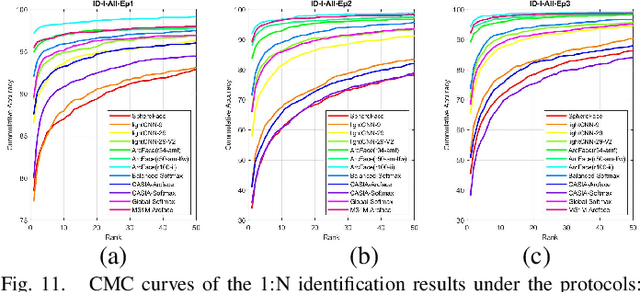

Face recognition is a popular and well-studied area with wide applications in our society. However, racial bias had been proven to be inherent in most State Of The Art (SOTA) face recognition systems. Many investigative studies on face recognition algorithms have reported higher false positive rates of African subjects cohorts than the other cohorts. Lack of large-scale African face image databases in public domain is one of the main restrictions in studying the racial bias problem of face recognition. To this end, we collect a face image database namely CASIA-Face-Africa which contains 38,546 images of 1,183 African subjects. Multi-spectral cameras are utilized to capture the face images under various illumination settings. Demographic attributes and facial expressions of the subjects are also carefully recorded. For landmark detection, each face image in the database is manually labeled with 68 facial keypoints. A group of evaluation protocols are constructed according to different applications, tasks, partitions and scenarios. The performances of SOTA face recognition algorithms without re-training are reported as baselines. The proposed database along with its face landmark annotations, evaluation protocols and preliminary results form a good benchmark to study the essential aspects of face biometrics for African subjects, especially face image preprocessing, face feature analysis and matching, facial expression recognition, sex/age estimation, ethnic classification, face image generation, etc. The database can be downloaded from our http://www.cripacsir.cn/dataset/