 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpening the Black Box: Preliminary Insights into Affective Modeling in Multimodal Foundation Models
Jan 22, 2026Understanding where and how emotions are represented in large-scale foundation models remains an open problem, particularly in multimodal affective settings. Despite the strong empirical performance of recent affective models, the internal architectural mechanisms that support affective understanding and generation are still poorly understood. In this work, we present a systematic mechanistic study of affective modeling in multimodal foundation models. Across multiple architectures, training strategies, and affective tasks, we analyze how emotion-oriented supervision reshapes internal model parameters. Our results consistently reveal a clear and robust pattern: affective adaptation does not primarily focus on the attention module, but instead localizes to the feed-forward gating projection (\texttt{gate\_proj}). Through controlled module transfer, targeted single-module adaptation, and destructive ablation, we further demonstrate that \texttt{gate\_proj} is sufficient, efficient, and necessary for affective understanding and generation. Notably, by tuning only approximately 24.5\% of the parameters tuned by AffectGPT, our approach achieves 96.6\% of its average performance across eight affective tasks, highlighting substantial parameter efficiency. Together, these findings provide empirical evidence that affective capabilities in foundation models are structurally mediated by feed-forward gating mechanisms and identify \texttt{gate\_proj} as a central architectural locus of affective modeling.
GI-Bench: A Panoramic Benchmark Revealing the Knowledge-Experience Dissociation of Multimodal Large Language Models in Gastrointestinal Endoscopy Against Clinical Standards
Jan 13, 2026Multimodal Large Language Models (MLLMs) show promise in gastroenterology, yet their performance against comprehensive clinical workflows and human benchmarks remains unverified. To systematically evaluate state-of-the-art MLLMs across a panoramic gastrointestinal endoscopy workflow and determine their clinical utility compared with human endoscopists. We constructed GI-Bench, a benchmark encompassing 20 fine-grained lesion categories. Twelve MLLMs were evaluated across a five-stage clinical workflow: anatomical localization, lesion identification, diagnosis, findings description, and management. Model performance was benchmarked against three junior endoscopists and three residency trainees using Macro-F1, mean Intersection-over-Union (mIoU), and multi-dimensional Likert scale. Gemini-3-Pro achieved state-of-the-art performance. In diagnostic reasoning, top-tier models (Macro-F1 0.641) outperformed trainees (0.492) and rivaled junior endoscopists (0.727; p>0.05). However, a critical "spatial grounding bottleneck" persisted; human lesion localization (mIoU >0.506) significantly outperformed the best model (0.345; p<0.05). Furthermore, qualitative analysis revealed a "fluency-accuracy paradox": models generated reports with superior linguistic readability compared with humans (p<0.05) but exhibited significantly lower factual correctness (p<0.05) due to "over-interpretation" and hallucination of visual features.GI-Bench maintains a dynamic leaderboard that tracks the evolving performance of MLLMs in clinical endoscopy. The current rankings and benchmark results are available at https://roterdl.github.io/GIBench/.
MMFormalizer: Multimodal Autoformalization in the Wild
Jan 06, 2026Autoformalization, which translates natural language mathematics into formal statements to enable machine reasoning, faces fundamental challenges in the wild due to the multimodal nature of the physical world, where physics requires inferring hidden constraints (e.g., mass or energy) from visual elements. To address this, we propose MMFormalizer, which extends autoformalization beyond text by integrating adaptive grounding with entities from real-world mathematical and physical domains. MMFormalizer recursively constructs formal propositions from perceptually grounded primitives through recursive grounding and axiom composition, with adaptive recursive termination ensuring that every abstraction is supported by visual evidence and anchored in dimensional or axiomatic grounding. We evaluate MMFormalizer on a new benchmark, PhyX-AF, comprising 115 curated samples from MathVerse, PhyX, Synthetic Geometry, and Analytic Geometry, covering diverse multimodal autoformalization tasks. Results show that frontier models such as GPT-5 and Gemini-3-Pro achieve the highest compile and semantic accuracy, with GPT-5 excelling in physical reasoning, while geometry remains the most challenging domain. Overall, MMFormalizer provides a scalable framework for unified multimodal autoformalization, bridging perception and formal reasoning. To the best of our knowledge, this is the first multimodal autoformalization method capable of handling classical mechanics (derived from the Hamiltonian), as well as relativity, quantum mechanics, and thermodynamics. More details are available on our project page: MMFormalizer.github.io
AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning
Dec 28, 2025Conducting reinforcement learning (RL) in simulated environments offers a cost-effective and highly scalable way to enhance language-based agents. However, previous work has been limited to semi-automated environment synthesis or tasks lacking sufficient difficulty, offering little breadth or depth. In addition, the instability of simulated users integrated into these environments, along with the heterogeneity across simulated environments, poses further challenges for agentic RL. In this work, we propose: (1) a unified pipeline for automated and scalable synthesis of simulated environments associated with high-difficulty but easily verifiable tasks; and (2) an environment level RL algorithm that not only effectively mitigates user instability but also performs advantage estimation at the environment level, thereby improving training efficiency and stability. Comprehensive evaluations on agentic benchmarks, including tau-bench, tau2-Bench, and VitaBench, validate the effectiveness of our proposed method. Further in-depth analyses underscore its out-of-domain generalization.
The Quest for Winning Tickets in Low-Rank Adapters
Dec 27, 2025The Lottery Ticket Hypothesis (LTH) suggests that over-parameterized neural networks contain sparse subnetworks ("winning tickets") capable of matching full model performance when trained from scratch. With the growing reliance on fine-tuning large pretrained models, we investigate whether LTH extends to parameter-efficient fine-tuning (PEFT), specifically focusing on Low-Rank Adaptation (LoRA) methods. Our key finding is that LTH holds within LoRAs, revealing sparse subnetworks that can match the performance of dense adapters. In particular, we find that the effectiveness of sparse subnetworks depends more on how much sparsity is applied in each layer than on the exact weights included in the subnetwork. Building on this insight, we propose Partial-LoRA, a method that systematically identifies said subnetworks and trains sparse low-rank adapters aligned with task-relevant subspaces of the pre-trained model. Experiments across 8 vision and 12 language tasks in both single-task and multi-task settings show that Partial-LoRA reduces the number of trainable parameters by up to 87\%, while maintaining or improving accuracy. Our results not only deepen our theoretical understanding of transfer learning and the interplay between pretraining and fine-tuning but also open new avenues for developing more efficient adaptation strategies.
Decomposing Task Vectors for Refined Model Editing
Dec 27, 2025Large pre-trained models have transformed machine learning, yet adapting these models effectively to exhibit precise, concept-specific behaviors remains a significant challenge. Task vectors, defined as the difference between fine-tuned and pre-trained model parameters, provide a mechanism for steering neural networks toward desired behaviors. This has given rise to large repositories dedicated to task vectors tailored for specific behaviors. The arithmetic operation of these task vectors allows for the seamless combination of desired behaviors without the need for large datasets. However, these vectors often contain overlapping concepts that can interfere with each other during arithmetic operations, leading to unpredictable outcomes. We propose a principled decomposition method that separates each task vector into two components: one capturing shared knowledge across multiple task vectors, and another isolating information unique to each specific task. By identifying invariant subspaces across projections, our approach enables more precise control over concept manipulation without unintended amplification or diminution of other behaviors. We demonstrate the effectiveness of our decomposition method across three domains: improving multi-task merging in image classification by 5% using shared components as additional task vectors, enabling clean style mixing in diffusion models without generation degradation by mixing only the unique components, and achieving 47% toxicity reduction in language models while preserving performance on general knowledge tasks by negating the toxic information isolated to the unique component. Our approach provides a new framework for understanding and controlling task vector arithmetic, addressing fundamental limitations in model editing operations.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025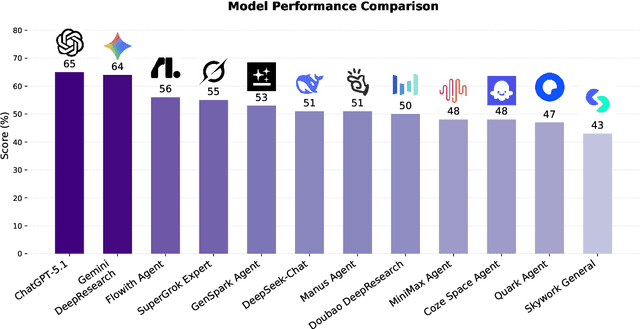
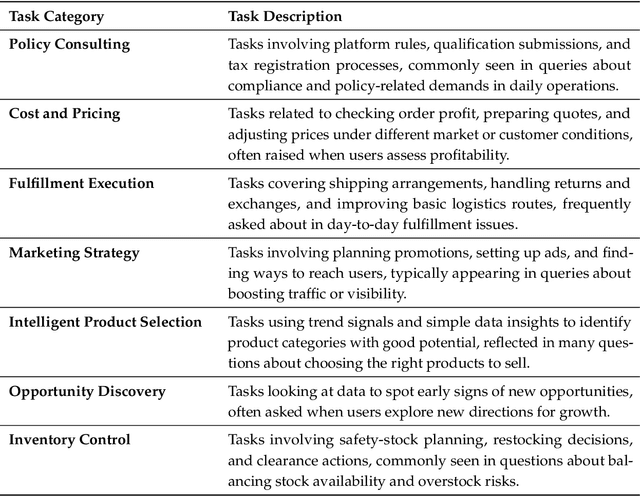

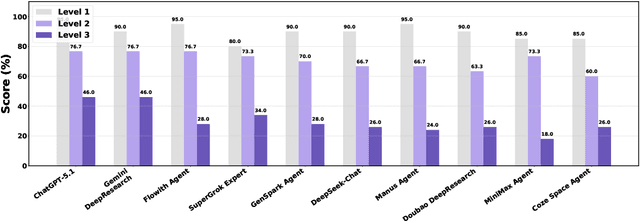
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
A Survey on Generative Recommendation: Data, Model, and Tasks
Oct 31, 2025Recommender systems serve as foundational infrastructure in modern information ecosystems, helping users navigate digital content and discover items aligned with their preferences. At their core, recommender systems address a fundamental problem: matching users with items. Over the past decades, the field has experienced successive paradigm shifts, from collaborative filtering and matrix factorization in the machine learning era to neural architectures in the deep learning era. Recently, the emergence of generative models, especially large language models (LLMs) and diffusion models, have sparked a new paradigm: generative recommendation, which reconceptualizes recommendation as a generation task rather than discriminative scoring. This survey provides a comprehensive examination through a unified tripartite framework spanning data, model, and task dimensions. Rather than simply categorizing works, we systematically decompose approaches into operational stages-data augmentation and unification, model alignment and training, task formulation and execution. At the data level, generative models enable knowledge-infused augmentation and agent-based simulation while unifying heterogeneous signals. At the model level, we taxonomize LLM-based methods, large recommendation models, and diffusion approaches, analyzing their alignment mechanisms and innovations. At the task level, we illuminate new capabilities including conversational interaction, explainable reasoning, and personalized content generation. We identify five key advantages: world knowledge integration, natural language understanding, reasoning capabilities, scaling laws, and creative generation. We critically examine challenges in benchmark design, model robustness, and deployment efficiency, while charting a roadmap toward intelligent recommendation assistants that fundamentally reshape human-information interaction.
Forestpest-YOLO: A High-Performance Detection Framework for Small Forestry Pests
Oct 01, 2025



Detecting agricultural pests in complex forestry environments using remote sensing imagery is fundamental for ecological preservation, yet it is severely hampered by practical challenges. Targets are often minuscule, heavily occluded, and visually similar to the cluttered background, causing conventional object detection models to falter due to the loss of fine-grained features and an inability to handle extreme data imbalance. To overcome these obstacles, this paper introduces Forestpest-YOLO, a detection framework meticulously optimized for the nuances of forestry remote sensing. Building upon the YOLOv8 architecture, our framework introduces a synergistic trio of innovations. We first integrate a lossless downsampling module, SPD-Conv, to ensure that critical high-resolution details of small targets are preserved throughout the network. This is complemented by a novel cross-stage feature fusion block, CSPOK, which dynamically enhances multi-scale feature representation while suppressing background noise. Finally, we employ VarifocalLoss to refine the training objective, compelling the model to focus on high-quality and hard-to-classify samples. Extensive experiments on our challenging, self-constructed ForestPest dataset demonstrate that Forestpest-YOLO achieves state-of-the-art performance, showing marked improvements in detecting small, occluded pests and significantly outperforming established baseline models.
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Sep 16, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.