 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT is not Enough: Enhancing Large Language Models with Knowledge Graphs for Fact-aware Language Modeling
Jun 20, 2023Recently, ChatGPT, a representative large language model (LLM), has gained considerable attention due to its powerful emergent abilities. Some researchers suggest that LLMs could potentially replace structured knowledge bases like knowledge graphs (KGs) and function as parameterized knowledge bases. However, while LLMs are proficient at learning probabilistic language patterns based on large corpus and engaging in conversations with humans, they, like previous smaller pre-trained language models (PLMs), still have difficulty in recalling facts while generating knowledge-grounded contents. To overcome these limitations, researchers have proposed enhancing data-driven PLMs with knowledge-based KGs to incorporate explicit factual knowledge into PLMs, thus improving their performance to generate texts requiring factual knowledge and providing more informed responses to user queries. This paper reviews the studies on enhancing PLMs with KGs, detailing existing knowledge graph enhanced pre-trained language models (KGPLMs) as well as their applications. Inspired by existing studies on KGPLM, this paper proposes to enhance LLMs with KGs by developing knowledge graph-enhanced large language models (KGLLMs). KGLLM provides a solution to enhance LLMs' factual reasoning ability, opening up new avenues for LLM research.
Cold-Start based Multi-Scenario Ranking Model for Click-Through Rate Prediction
Apr 16, 2023Online travel platforms (OTPs), e.g., Ctrip.com or Fliggy.com, can effectively provide travel-related products or services to users. In this paper, we focus on the multi-scenario click-through rate (CTR) prediction, i.e., training a unified model to serve all scenarios. Existing multi-scenario based CTR methods struggle in the context of OTP setting due to the ignorance of the cold-start users who have very limited data. To fill this gap, we propose a novel method named Cold-Start based Multi-scenario Network (CSMN). Specifically, it consists of two basic components including: 1) User Interest Projection Network (UIPN), which firstly purifies users' behaviors by eliminating the scenario-irrelevant information in behaviors with respect to the visiting scenario, followed by obtaining users' scenario-specific interests by summarizing the purified behaviors with respect to the target item via an attention mechanism; and 2) User Representation Memory Network (URMN), which benefits cold-start users from users with rich behaviors through a memory read and write mechanism. CSMN seamlessly integrates both components in an end-to-end learning framework. Extensive experiments on real-world offline dataset and online A/B test demonstrate the superiority of CSMN over state-of-the-art methods.
GIPA++: A General Information Propagation Algorithm for Graph Learning
Jan 19, 2023Graph neural networks (GNNs) have been widely used in graph-structured data computation, showing promising performance in various applications such as node classification, link prediction, and network recommendation. Existing works mainly focus on node-wise correlation when doing weighted aggregation of neighboring nodes based on attention, such as dot product by the dense vectors of two nodes. This may cause conflicting noise in nodes to be propagated when doing information propagation. To solve this problem, we propose a General Information Propagation Algorithm (GIPA in short), which exploits more fine-grained information fusion including bit-wise and feature-wise correlations based on edge features in their propagation. Specifically, the bit-wise correlation calculates the element-wise attention weight through a multi-layer perceptron (MLP) based on the dense representations of two nodes and their edge; The feature-wise correlation is based on the one-hot representations of node attribute features for feature selection. We evaluate the performance of GIPA on the Open Graph Benchmark proteins (OGBN-proteins for short) dataset and the Alipay dataset of Alibaba. Experimental results reveal that GIPA outperforms the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8901\pm 0.0011$, which is better than that of all the existing methods listed in the OGBN-proteins leaderboard.
Context-Aware Robust Fine-Tuning
Nov 29, 2022Contrastive Language-Image Pre-trained (CLIP) models have zero-shot ability of classifying an image belonging to "[CLASS]" by using similarity between the image and the prompt sentence "a [CONTEXT] of [CLASS]". Based on exhaustive text cues in "[CONTEXT]", CLIP model is aware of different contexts, e.g. background, style, viewpoint, and exhibits unprecedented robustness against a wide range of distribution shifts. However, recent works find further fine-tuning of CLIP models improves accuracy but sacrifices the robustness on downstream tasks. We conduct an empirical investigation to show fine-tuning will corrupt the context-aware ability of pre-trained CLIP features. To solve this problem, we propose Context-Aware Robust Fine-tuning (CAR-FT). CAR-FT regularizes the model during fine-tuning to capture the context information. Specifically, we use zero-shot prompt weights to get the context distribution contained in the image. By minimizing the Kullback-Leibler Divergence (KLD) between context distributions induced by original/fine-tuned CLIP models, CAR-FT makes the context-aware ability of CLIP inherited into downstream tasks, and achieves both higher In-Distribution (ID) and Out-Of-Distribution (OOD) accuracy. The experimental results show CAR-FT achieves superior robustness on five OOD test datasets of ImageNet, and meanwhile brings accuracy gains on nine downstream tasks. Additionally, CAR-FT surpasses previous Domain Generalization (DG) methods and gets 78.5% averaged accuracy on DomainBed benchmark, building the new state-of-the-art.
Defending Against Backdoor Attack on Graph Nerual Network by Explainability
Sep 07, 2022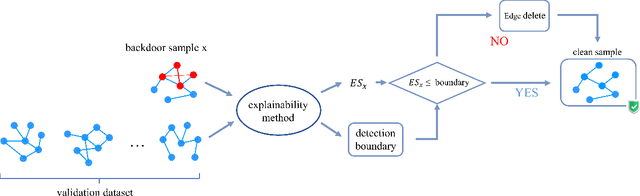
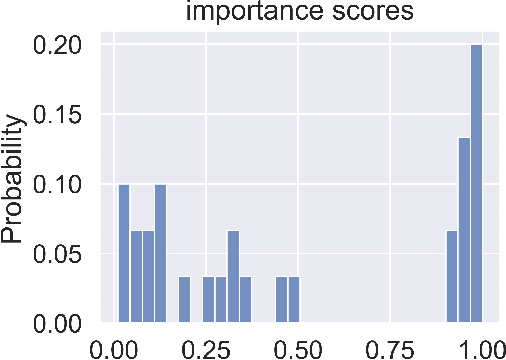
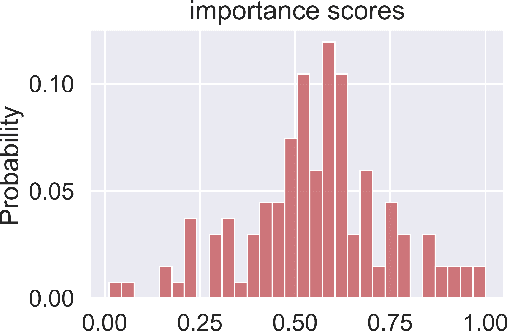
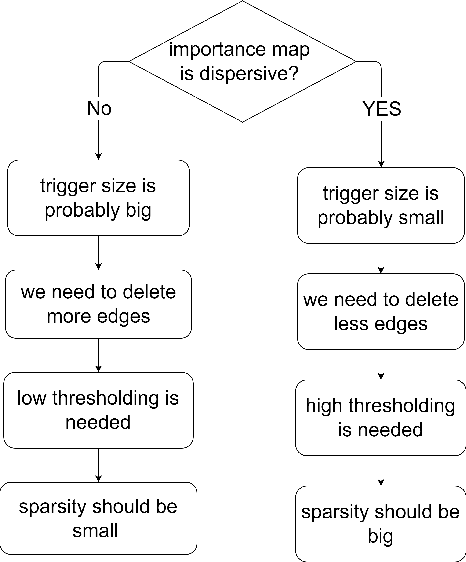
Backdoor attack is a powerful attack algorithm to deep learning model. Recently, GNN's vulnerability to backdoor attack has been proved especially on graph classification task. In this paper, we propose the first backdoor detection and defense method on GNN. Most backdoor attack depends on injecting small but influential trigger to the clean sample. For graph data, current backdoor attack focus on manipulating the graph structure to inject the trigger. We find that there are apparent differences between benign samples and malicious samples in some explanatory evaluation metrics, such as fidelity and infidelity. After identifying the malicious sample, the explainability of the GNN model can help us capture the most significant subgraph which is probably the trigger in a trojan graph. We use various dataset and different attack settings to prove the effectiveness of our defense method. The attack success rate all turns out to decrease considerably.
A Systematical Evaluation for Next-Basket Recommendation Algorithms
Sep 07, 2022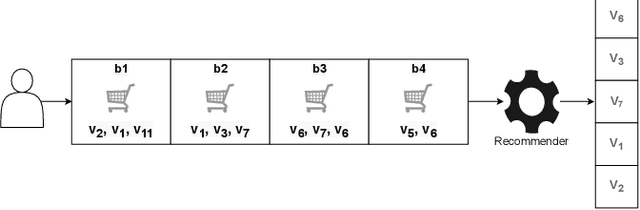
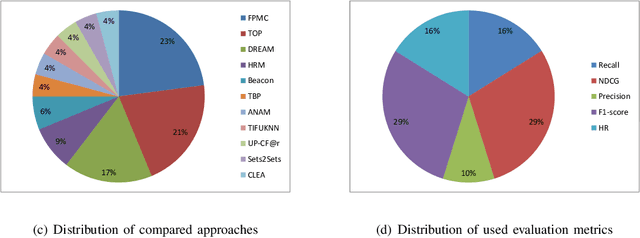
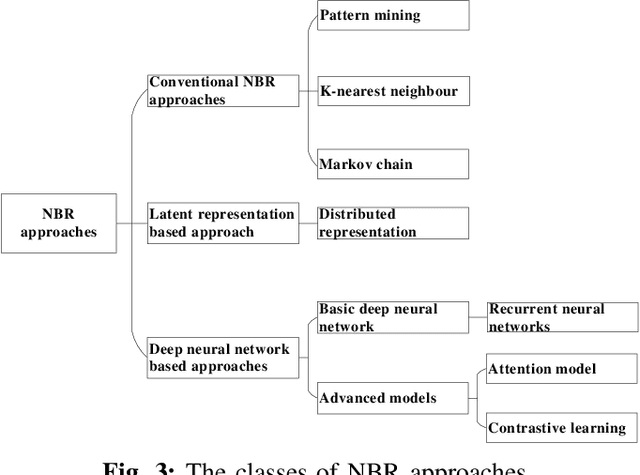
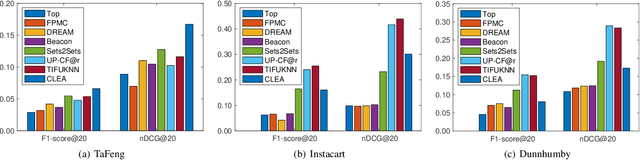
Next basket recommender systems (NBRs) aim to recommend a user's next (shopping) basket of items via modeling the user's preferences towards items based on the user's purchase history, usually a sequence of historical baskets. Due to its wide applicability in the real-world E-commerce industry, the studies NBR have attracted increasing attention in recent years. NBRs have been widely studied and much progress has been achieved in this area with a variety of NBR approaches having been proposed. However, an important issue is that there is a lack of a systematic and unified evaluation over the various NBR approaches. Different studies often evaluate NBR approaches on different datasets, under different experimental settings, making it hard to fairly and effectively compare the performance of different NBR approaches. To bridge this gap, in this work, we conduct a systematical empirical study in NBR area. Specifically, we review the representative work in NBR and analyze their cons and pros. Then, we run the selected NBR algorithms on the same datasets, under the same experimental setting and evaluate their performances using the same measurements. This provides a unified framework to fairly compare different NBR approaches. We hope this study can provide a valuable reference for the future research in this vibrant area.
Path-aware Siamese Graph Neural Network for Link Prediction
Aug 10, 2022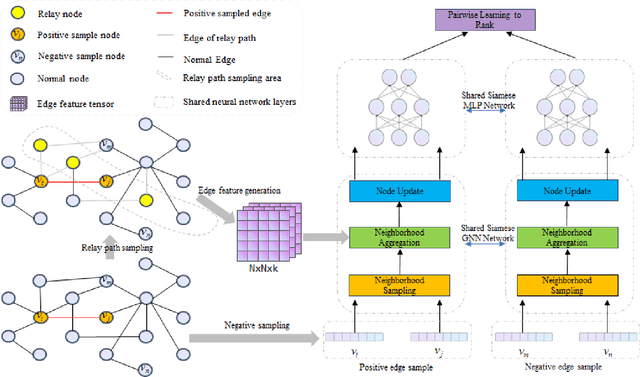

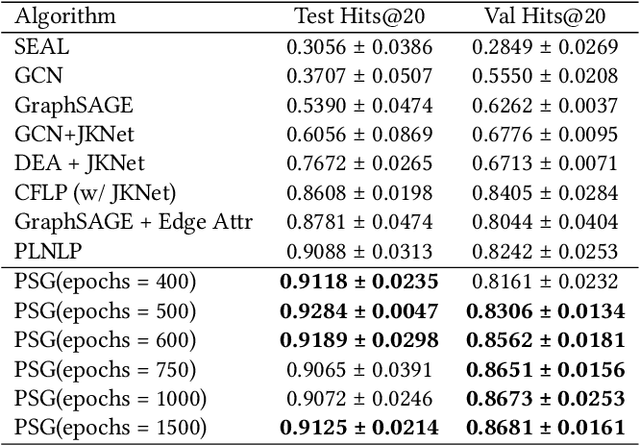
In this paper, we propose an algorithm of Path-aware Siamese Graph neural network(PSG) for link prediction tasks. Firstly, PSG can capture both nodes and edge features for given two nodes, namely the structure information of k-neighborhoods and relay paths information of the nodes. Furthermore, siamese graph neural network is utilized by PSG for representation learning of two contrastive links, which are a positive link and a negative link. We evaluate the proposed algorithm PSG on a link property prediction dataset of Open Graph Benchmark (OGB), ogbl-ddi. PSG achieves top 1 performance on ogbl-ddi. The experimental results verify the superiority of PSG.
Re-weighting Negative Samples for Model-Agnostic Matching
Jul 06, 2022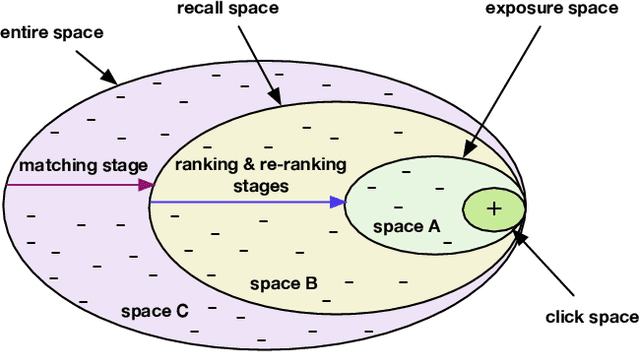
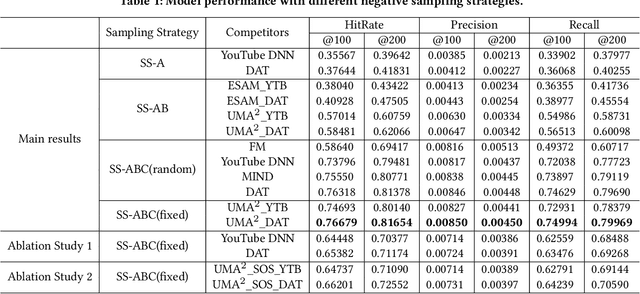
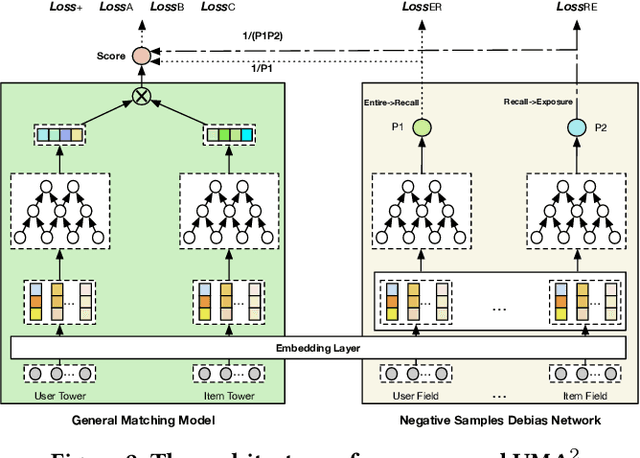
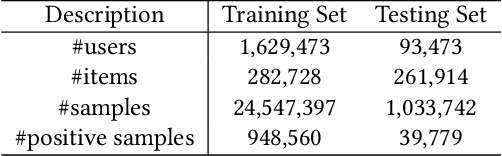
Recommender Systems (RS), as an efficient tool to discover users' interested items from a very large corpus, has attracted more and more attention from academia and industry. As the initial stage of RS, large-scale matching is fundamental yet challenging. A typical recipe is to learn user and item representations with a two-tower architecture and then calculate the similarity score between both representation vectors, which however still struggles in how to properly deal with negative samples. In this paper, we find that the common practice that randomly sampling negative samples from the entire space and treating them equally is not an optimal choice, since the negative samples from different sub-spaces at different stages have different importance to a matching model. To address this issue, we propose a novel method named Unbiased Model-Agnostic Matching Approach (UMA$^2$). It consists of two basic modules including 1) General Matching Model (GMM), which is model-agnostic and can be implemented as any embedding-based two-tower models; and 2) Negative Samples Debias Network (NSDN), which discriminates negative samples by borrowing the idea of Inverse Propensity Weighting (IPW) and re-weighs the loss in GMM. UMA$^2$ seamlessly integrates these two modules in an end-to-end multi-task learning framework. Extensive experiments on both real-world offline dataset and online A/B test demonstrate its superiority over state-of-the-art methods.
RMGN: A Regional Mask Guided Network for Parser-free Virtual Try-on
Apr 24, 2022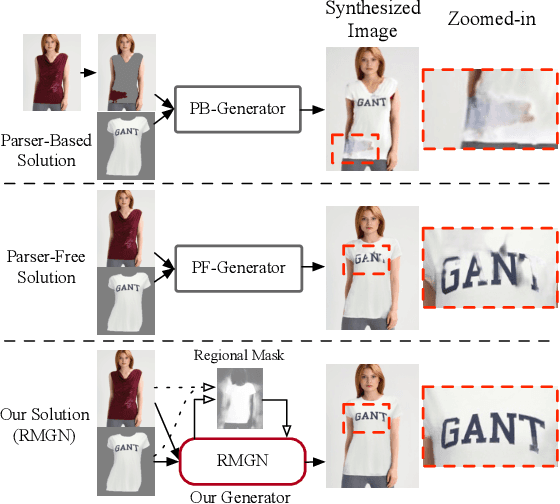
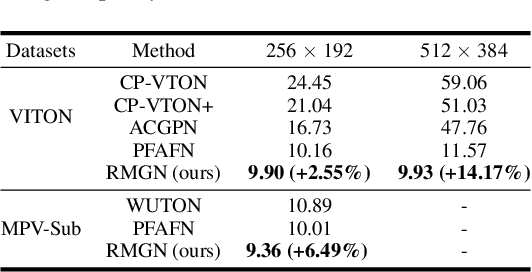
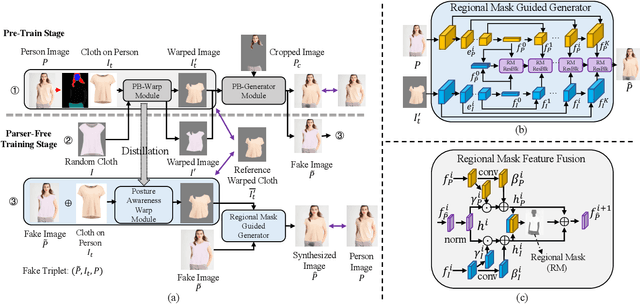
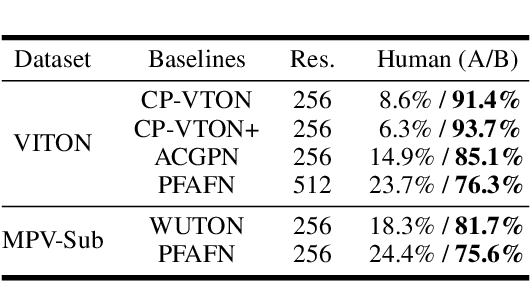
Virtual try-on(VTON) aims at fitting target clothes to reference person images, which is widely adopted in e-commerce.Existing VTON approaches can be narrowly categorized into Parser-Based(PB) and Parser-Free(PF) by whether relying on the parser information to mask the persons' clothes and synthesize try-on images. Although abandoning parser information has improved the applicability of PF methods, the ability of detail synthesizing has also been sacrificed. As a result, the distraction from original cloth may persistin synthesized images, especially in complicated postures and high resolution applications. To address the aforementioned issue, we propose a novel PF method named Regional Mask Guided Network(RMGN). More specifically, a regional mask is proposed to explicitly fuse the features of target clothes and reference persons so that the persisted distraction can be eliminated. A posture awareness loss and a multi-level feature extractor are further proposed to handle the complicated postures and synthesize high resolution images. Extensive experiments demonstrate that our proposed RMGN outperforms both state-of-the-art PB and PF methods.Ablation studies further verify the effectiveness ofmodules in RMGN.
Sequence-Based Target Coin Prediction for Cryptocurrency Pump-and-Dump
Apr 21, 2022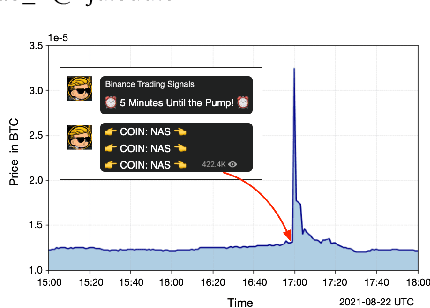
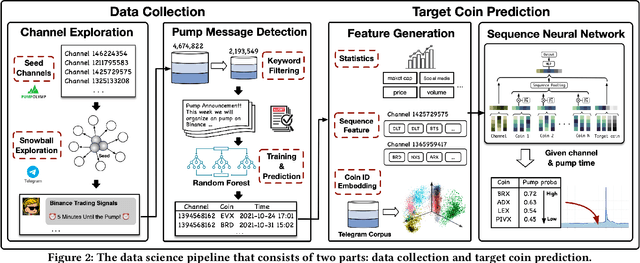
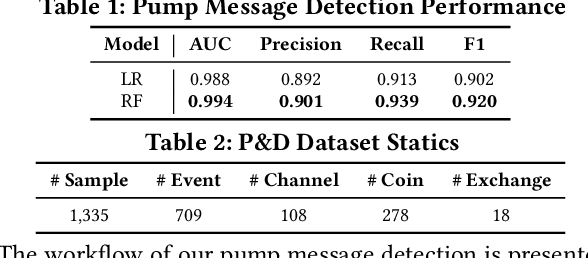
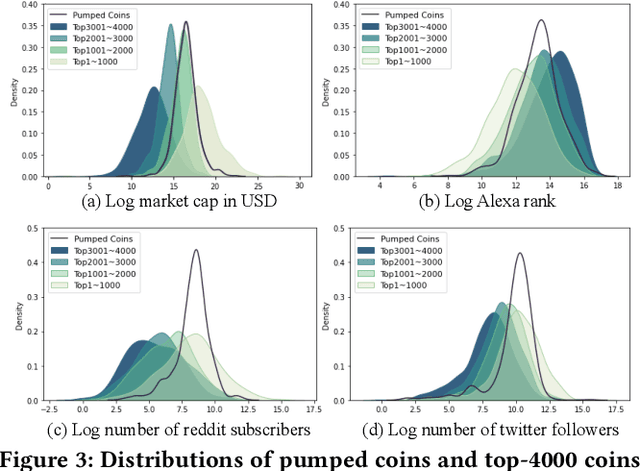
As the pump-and-dump schemes (P&Ds) proliferate in the cryptocurrency market, it becomes imperative to detect such fraudulent activities in advance, to inform potentially susceptible investors before they become victims. In this paper, we focus on the target coin prediction task, i.e., to predict the pump probability of all coins listed in the target exchange before a pump. We conduct a comprehensive study of the latest P&Ds, investigate 709 events organized in Telegram channels from Jan. 2019 to Jan. 2022, and unearth some abnormal yet interesting patterns of P&Ds. Empirical analysis demonstrates that pumped coins exhibit intra-channel homogeneity and inter-channel heterogeneity, which inspires us to develop a novel sequence-based neural network named SNN. Specifically, SNN encodes each channel's pump history as a sequence representation via a positional attention mechanism, which filters useful information and alleviates the noise introduced when the sequence length is long. We also identify and address the coin-side cold-start problem in a practical setting. Extensive experiments show a lift of 1.6% AUC and 41.0% Hit Ratio@3 brought by our method, making it well-suited for real-world application. As a side contribution, we release the source code of our entire data science pipeline on GitHub, along with the dataset tailored for studying the latest P&Ds.