 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
Rooftop Wind Field Reconstruction Using Sparse Sensors: From Deterministic to Generative Learning Methods
Mar 13, 2026Real-time rooftop wind-speed distribution is important for the safe operation of drones and urban air mobility systems, wind control systems, and rooftop utilization. However, rooftop flows show strong nonlinearity, separation, and cross-direction variability, which make flow field reconstruction from sparse sensors difficult. This study develops a learning-from-observation framework using wind-tunnel experimental data obtained by Particle Image Velocimetry (PIV) and compares Kriging interpolation with three deep learning models: UNet, Vision Transformer Autoencoder (ViTAE), and Conditional Wasserstein GAN (CWGAN). We evaluate two training strategies, single wind-direction training (SDT) and mixed wind-direction training (MDT), across sensor densities from 5 to 30, test robustness under sensor position perturbations of plus or minus 1 grid, and optimize sensor placement via Proper Orthogonal Decomposition with QR decomposition. Results show that deep learning methods can reconstruct rooftop wind fields from sparse sensor data effectively. Compared with Kriging interpolation, the deep learning models improved SSIM by up to 32.7%, FAC2 by 24.2%, and NMSE by 27.8%. Mixed wind-direction training further improved performance, with gains of up to 173.7% in SSIM, 16.7% in FAC2, and 98.3% in MG compared with single-direction training. The results also show that sensor configuration, optimization, and training strategy should be considered jointly for reliable deployment. QR-based optimization improved robustness by up to 27.8% under sensor perturbations, although with metric-dependent trade-offs. Training on experimental rather than simulated data also provides practical guidance for method selection and sensor placement in different scenarios.
From Woofs to Words: Towards Intelligent Robotic Guide Dogs with Verbal Communication
Mar 13, 2026Assistive robotics is an important subarea of robotics that focuses on the well-being of people with disabilities. A robotic guide dog is an assistive quadruped robot that helps visually impaired people in obstacle avoidance and navigation. Enabling language capabilities for robotic guide dogs goes beyond naively adding an existing dialog system onto a mobile robot. The novel challenges include grounding language in the dynamically changing environment and improving spatial awareness for the human handler. To address those challenges, we develop a novel dialog system for robotic guide dogs that uses LLMs to verbalize both navigational plans and scenes. The goal is to enable verbal communication for collaborative decision-making within the handler-robot team. In experiments, we conducted a human study to evaluate different verbalization strategies and a simulation study to assess the efficiency and accuracy in navigation tasks.
Towards Understanding and Enhancing Security of Proof-of-Training for DNN Model Ownership Verification
Oct 06, 2024



The great economic values of deep neural networks (DNNs) urge AI enterprises to protect their intellectual property (IP) for these models. Recently, proof-of-training (PoT) has been proposed as a promising solution to DNN IP protection, through which AI enterprises can utilize the record of DNN training process as their ownership proof. To prevent attackers from forging ownership proof, a secure PoT scheme should be able to distinguish honest training records from those forged by attackers. Although existing PoT schemes provide various distinction criteria, these criteria are based on intuitions or observations. The effectiveness of these criteria lacks clear and comprehensive analysis, resulting in existing schemes initially deemed secure being swiftly compromised by simple ideas. In this paper, we make the first move to identify distinction criteria in the style of formal methods, so that their effectiveness can be explicitly demonstrated. Specifically, we conduct systematic modeling to cover a wide range of attacks and then theoretically analyze the distinctions between honest and forged training records. The analysis results not only induce a universal distinction criterion, but also provide detailed reasoning to demonstrate its effectiveness in defending against attacks covered by our model. Guided by the criterion, we propose a generic PoT construction that can be instantiated into concrete schemes. This construction sheds light on the realization that trajectory matching algorithms, previously employed in data distillation, possess significant advantages in PoT construction. Experimental results demonstrate that our scheme can resist attacks that have compromised existing PoT schemes, which corroborates its superiority in security.
MetMamba: Regional Weather Forecasting with Spatial-Temporal Mamba Model
Aug 14, 2024



Deep Learning based Weather Prediction (DLWP) models have been improving rapidly over the last few years, surpassing state of the art numerical weather forecasts by significant margins. While much of the optimization effort is focused on training curriculum to extend forecast range in the global context, two aspects remains less explored: limited area modeling and better backbones for weather forecasting. We show in this paper that MetMamba, a DLWP model built on a state-of-the-art state-space model, Mamba, offers notable performance gains and unique advantages over other popular backbones using traditional attention mechanisms and neural operators. We also demonstrate the feasibility of deep learning based limited area modeling via coupled training with a global host model.
RMGN: A Regional Mask Guided Network for Parser-free Virtual Try-on
Apr 24, 2022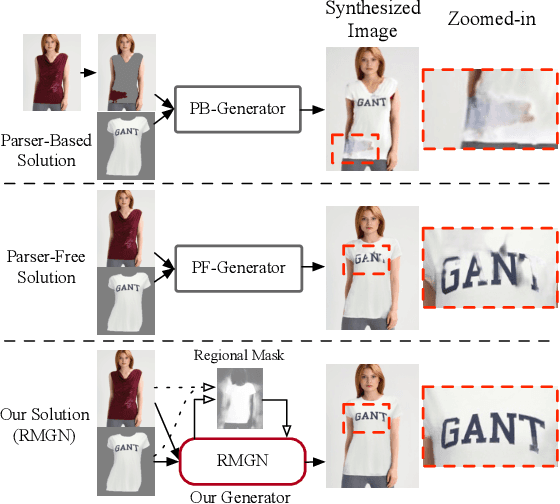
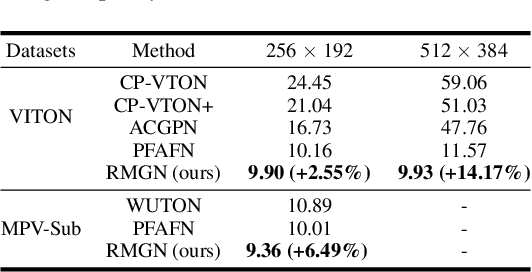
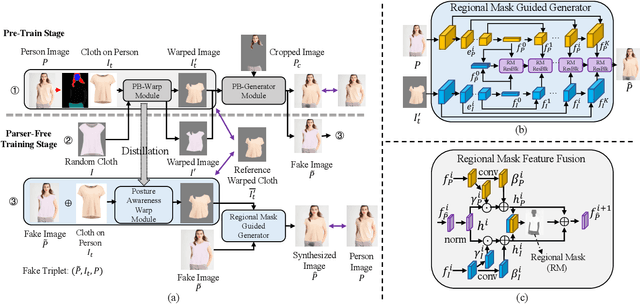
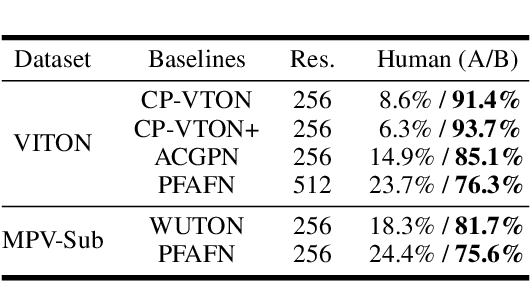
Virtual try-on(VTON) aims at fitting target clothes to reference person images, which is widely adopted in e-commerce.Existing VTON approaches can be narrowly categorized into Parser-Based(PB) and Parser-Free(PF) by whether relying on the parser information to mask the persons' clothes and synthesize try-on images. Although abandoning parser information has improved the applicability of PF methods, the ability of detail synthesizing has also been sacrificed. As a result, the distraction from original cloth may persistin synthesized images, especially in complicated postures and high resolution applications. To address the aforementioned issue, we propose a novel PF method named Regional Mask Guided Network(RMGN). More specifically, a regional mask is proposed to explicitly fuse the features of target clothes and reference persons so that the persisted distraction can be eliminated. A posture awareness loss and a multi-level feature extractor are further proposed to handle the complicated postures and synthesize high resolution images. Extensive experiments demonstrate that our proposed RMGN outperforms both state-of-the-art PB and PF methods.Ablation studies further verify the effectiveness ofmodules in RMGN.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018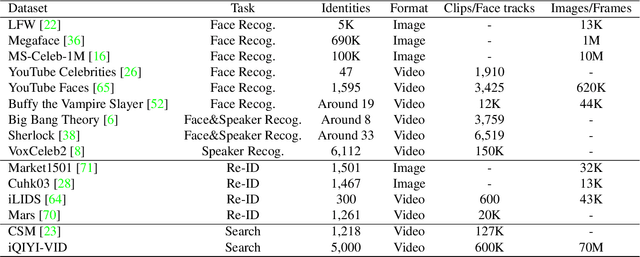

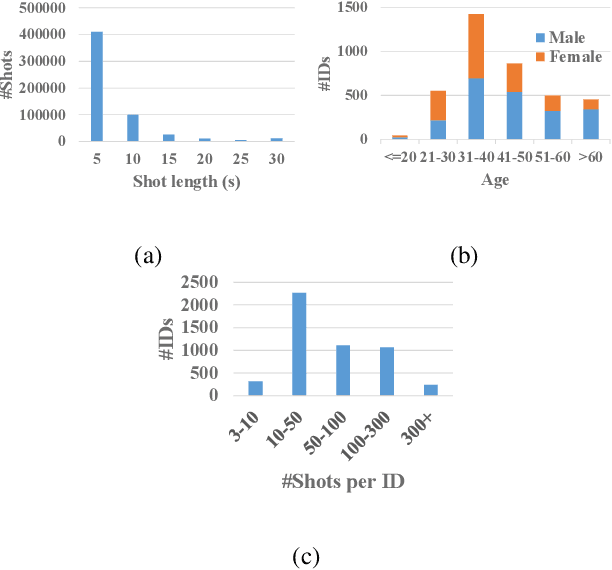
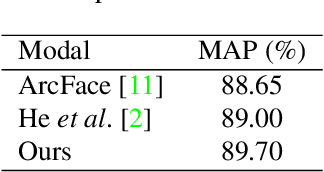
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.