 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Injection for Neural Contextual Biasing
Jun 05, 2024



Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
Apr 15, 2024



Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
* 9 pages, 3 figures, accepted by NAACL 2024 - Industry Track
High-precision Voice Search Query Correction via Retrievable Speech-text Embedings
Jan 08, 2024Automatic speech recognition (ASR) systems can suffer from poor recall for various reasons, such as noisy audio, lack of sufficient training data, etc. Previous work has shown that recall can be improved by retrieving rewrite candidates from a large database of likely, contextually-relevant alternatives to the hypothesis text using nearest-neighbors search over embeddings of the ASR hypothesis text to correct and candidate corrections. However, ASR-hypothesis-based retrieval can yield poor precision if the textual hypotheses are too phonetically dissimilar to the transcript truth. In this paper, we eliminate the hypothesis-audio mismatch problem by querying the correction database directly using embeddings derived from the utterance audio; the embeddings of the utterance audio and candidate corrections are produced by multimodal speech-text embedding networks trained to place the embedding of the audio of an utterance and the embedding of its corresponding textual transcript close together. After locating an appropriate correction candidate using nearest-neighbor search, we score the candidate with its speech-text embedding distance before adding the candidate to the original n-best list. We show a relative word error rate (WER) reduction of 6% on utterances whose transcripts appear in the candidate set, without increasing WER on general utterances.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023


Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.
A Deliberation-based Joint Acoustic and Text Decoder
Mar 23, 2023



We propose a new two-pass E2E speech recognition model that improves ASR performance by training on a combination of paired data and unpaired text data. Previously, the joint acoustic and text decoder (JATD) has shown promising results through the use of text data during model training and the recently introduced deliberation architecture has reduced recognition errors by leveraging first-pass decoding results. Our method, dubbed Deliberation-JATD, combines the spelling correcting abilities of deliberation with JATD's use of unpaired text data to further improve performance. The proposed model produces substantial gains across multiple test sets, especially those focused on rare words, where it reduces word error rate (WER) by between 12% and 22.5% relative. This is done without increasing model size or requiring multi-stage training, making Deliberation-JATD an efficient candidate for on-device applications.
Streaming Intended Query Detection using E2E Modeling for Continued Conversation
Aug 29, 2022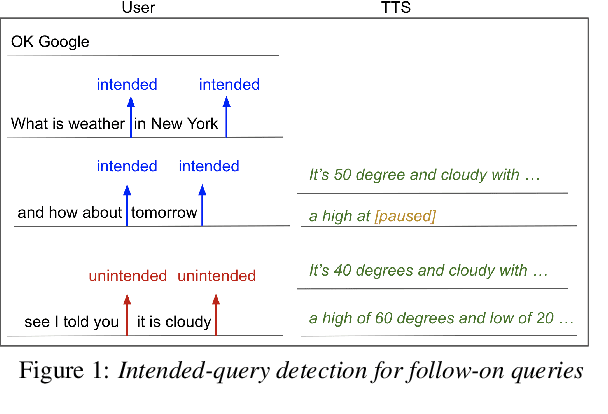

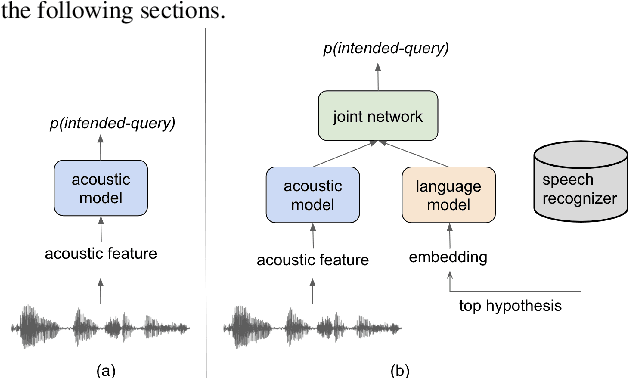
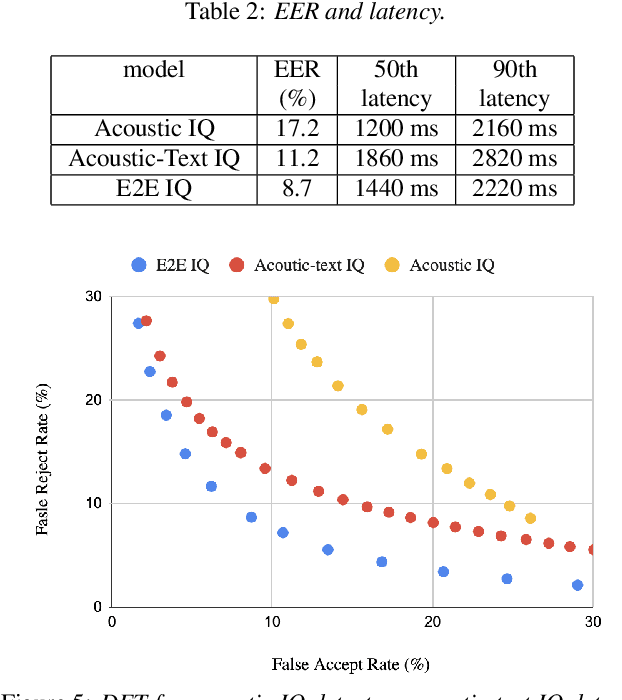
In voice-enabled applications, a predetermined hotword isusually used to activate a device in order to attend to the query.However, speaking queries followed by a hotword each timeintroduces a cognitive burden in continued conversations. Toavoid repeating a hotword, we propose a streaming end-to-end(E2E) intended query detector that identifies the utterancesdirected towards the device and filters out other utterancesnot directed towards device. The proposed approach incor-porates the intended query detector into the E2E model thatalready folds different components of the speech recognitionpipeline into one neural network.The E2E modeling onspeech decoding and intended query detection also allows us todeclare a quick intended query detection based on early partialrecognition result, which is important to decrease latencyand make the system responsive. We demonstrate that theproposed E2E approach yields a 22% relative improvement onequal error rate (EER) for the detection accuracy and 600 mslatency improvement compared with an independent intendedquery detector. In our experiment, the proposed model detectswhether the user is talking to the device with a 8.7% EERwithin 1.4 seconds of median latency after user starts speaking.
Speech Recognition with Augmented Synthesized Speech
Sep 25, 2019
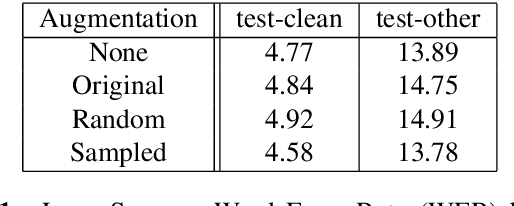
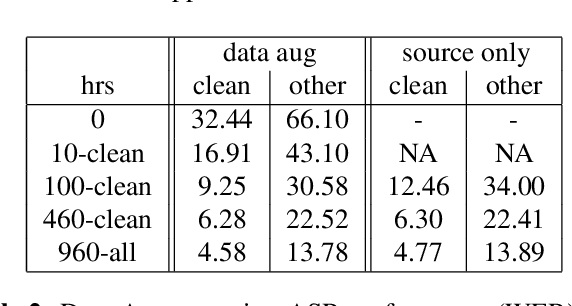
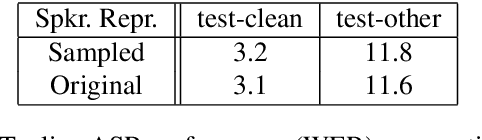
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.
Improving Performance of End-to-End ASR on Numeric Sequences
Jul 01, 2019
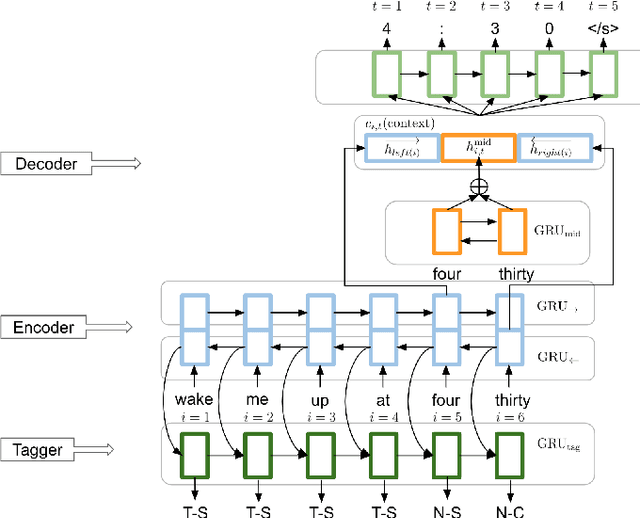
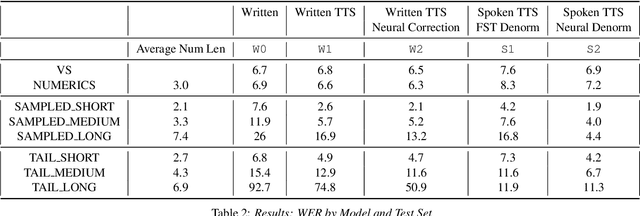
Recognizing written domain numeric utterances (e.g. I need $1.25.) can be challenging for ASR systems, particularly when numeric sequences are not seen during training. This out-of-vocabulary (OOV) issue is addressed in conventional ASR systems by training part of the model on spoken domain utterances (e.g. I need one dollar and twenty five cents.), for which numeric sequences are composed of in-vocabulary numbers, and then using an FST verbalizer to denormalize the result. Unfortunately, conventional ASR models are not suitable for the low memory setting of on-device speech recognition. E2E models such as RNN-T are attractive for on-device ASR, as they fold the AM, PM and LM of a conventional model into one neural network. However, in the on-device setting the large memory footprint of an FST denormer makes spoken domain training more difficult. In this paper, we investigate techniques to improve E2E model performance on numeric data. We find that using a text-to-speech system to generate additional numeric training data, as well as using a small-footprint neural network to perform spoken-to-written domain denorming, yields improvement in several numeric classes. In the case of the longest numeric sequences, we see reduction of WER by up to a factor of 8.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.