 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
OmniEVA: Embodied Versatile Planner via Task-Adaptive 3D-Grounded and Embodiment-aware Reasoning
Sep 11, 2025Recent advances in multimodal large language models (MLLMs) have opened new opportunities for embodied intelligence, enabling multimodal understanding, reasoning, and interaction, as well as continuous spatial decision-making. Nevertheless, current MLLM-based embodied systems face two critical limitations. First, Geometric Adaptability Gap: models trained solely on 2D inputs or with hard-coded 3D geometry injection suffer from either insufficient spatial information or restricted 2D generalization, leading to poor adaptability across tasks with diverse spatial demands. Second, Embodiment Constraint Gap: prior work often neglects the physical constraints and capacities of real robots, resulting in task plans that are theoretically valid but practically infeasible.To address these gaps, we introduce OmniEVA -- an embodied versatile planner that enables advanced embodied reasoning and task planning through two pivotal innovations: (1) a Task-Adaptive 3D Grounding mechanism, which introduces a gated router to perform explicit selective regulation of 3D fusion based on contextual requirements, enabling context-aware 3D grounding for diverse embodied tasks. (2) an Embodiment-Aware Reasoning framework that jointly incorporates task goals and embodiment constraints into the reasoning loop, resulting in planning decisions that are both goal-directed and executable. Extensive experimental results demonstrate that OmniEVA not only achieves state-of-the-art general embodied reasoning performance, but also exhibits a strong ability across a wide range of downstream scenarios. Evaluations of a suite of proposed embodied benchmarks, including both primitive and composite tasks, confirm its robust and versatile planning capabilities. Project page: https://omnieva.github.io
MineAnyBuild: Benchmarking Spatial Planning for Open-world AI Agents
May 26, 2025Spatial Planning is a crucial part in the field of spatial intelligence, which requires the understanding and planning about object arrangements in space perspective. AI agents with the spatial planning ability can better adapt to various real-world applications, including robotic manipulation, automatic assembly, urban planning etc. Recent works have attempted to construct benchmarks for evaluating the spatial intelligence of Multimodal Large Language Models (MLLMs). Nevertheless, these benchmarks primarily focus on spatial reasoning based on typical Visual Question-Answering (VQA) forms, which suffers from the gap between abstract spatial understanding and concrete task execution. In this work, we take a step further to build a comprehensive benchmark called MineAnyBuild, aiming to evaluate the spatial planning ability of open-world AI agents in the Minecraft game. Specifically, MineAnyBuild requires an agent to generate executable architecture building plans based on the given multi-modal human instructions. It involves 4,000 curated spatial planning tasks and also provides a paradigm for infinitely expandable data collection by utilizing rich player-generated content. MineAnyBuild evaluates spatial planning through four core supporting dimensions: spatial understanding, spatial reasoning, creativity, and spatial commonsense. Based on MineAnyBuild, we perform a comprehensive evaluation for existing MLLM-based agents, revealing the severe limitations but enormous potential in their spatial planning abilities. We believe our MineAnyBuild will open new avenues for the evaluation of spatial intelligence and help promote further development for open-world AI agents capable of spatial planning.
Structured Preference Optimization for Vision-Language Long-Horizon Task Planning
Feb 28, 2025Existing methods for vision-language task planning excel in short-horizon tasks but often fall short in complex, long-horizon planning within dynamic environments. These challenges primarily arise from the difficulty of effectively training models to produce high-quality reasoning processes for long-horizon tasks. To address this, we propose Structured Preference Optimization (SPO), which aims to enhance reasoning and action selection in long-horizon task planning through structured preference evaluation and optimized training strategies. Specifically, SPO introduces: 1) Preference-Based Scoring and Optimization, which systematically evaluates reasoning chains based on task relevance, visual grounding, and historical consistency; and 2) Curriculum-Guided Training, where the model progressively adapts from simple to complex tasks, improving its generalization ability in long-horizon scenarios and enhancing reasoning robustness. To advance research in vision-language long-horizon task planning, we introduce ExtendaBench, a comprehensive benchmark covering 1,509 tasks across VirtualHome and Habitat 2.0, categorized into ultra-short, short, medium, and long tasks. Experimental results demonstrate that SPO significantly improves reasoning quality and final decision accuracy, outperforming prior methods on long-horizon tasks and underscoring the effectiveness of preference-driven optimization in vision-language task planning. Specifically, SPO achieves a +5.98% GCR and +4.68% SR improvement in VirtualHome and a +3.30% GCR and +2.11% SR improvement in Habitat over the best-performing baselines.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025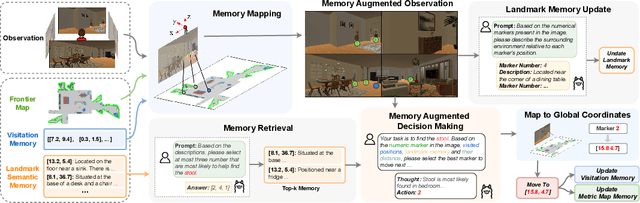
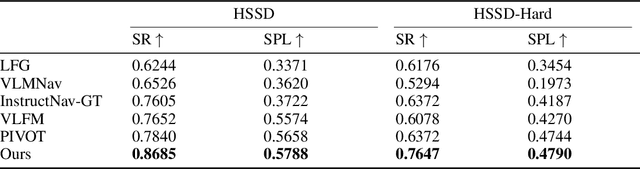
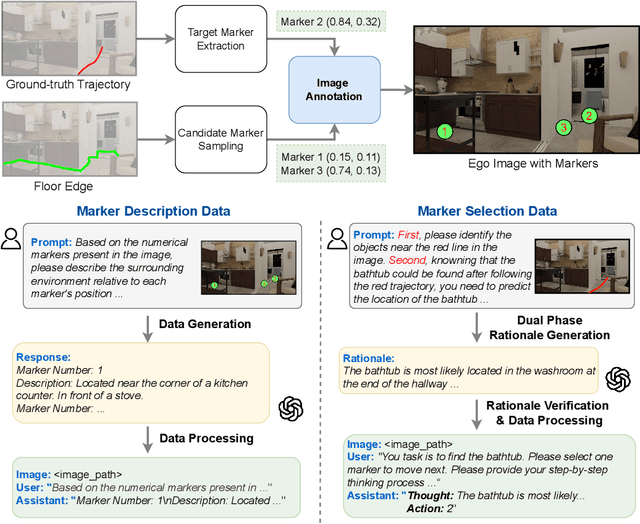

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
3D-MoE: A Mixture-of-Experts Multi-modal LLM for 3D Vision and Pose Diffusion via Rectified Flow
Jan 28, 2025



3D vision and spatial reasoning have long been recognized as preferable for accurately perceiving our three-dimensional world, especially when compared with traditional visual reasoning based on 2D images. Due to the difficulties in collecting high-quality 3D data, research in this area has only recently gained momentum. With the advent of powerful large language models (LLMs), multi-modal LLMs for 3D vision have been developed over the past few years. However, most of these models focus primarily on the vision encoder for 3D data. In this paper, we propose converting existing densely activated LLMs into mixture-of-experts (MoE) models, which have proven effective for multi-modal data processing. In addition to leveraging these models' instruction-following capabilities, we further enable embodied task planning by attaching a diffusion head, Pose-DiT, that employs a novel rectified flow diffusion scheduler. Experimental results on 3D question answering and task-planning tasks demonstrate that our 3D-MoE framework achieves improved performance with fewer activated parameters.
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025



Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning
Aug 02, 2024Vision-language-action models have gained significant attention for their ability to model trajectories in robot learning. However, most existing models rely on Transformer models with vanilla causal attention, which we find suboptimal for processing segmented multi-modal sequences. Additionally, the autoregressive generation approach falls short in generating multi-dimensional actions. In this paper, we introduce Actra, an optimized Transformer architecture featuring trajectory attention and learnable action queries, designed for effective encoding and decoding of segmented vision-language-action trajectories in robot imitation learning. Furthermore, we devise a multi-modal contrastive learning objective to explicitly align different modalities, complementing the primary behavior cloning objective. Through extensive experiments conducted across various environments, Actra exhibits substantial performance improvement when compared to state-of-the-art models in terms of generalizability, dexterity, and precision.
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
Jun 28, 2024



We present a framework for intuitive robot programming by non-experts, leveraging natural language prompts and contextual information from the Robot Operating System (ROS). Our system integrates large language models (LLMs), enabling non-experts to articulate task requirements to the system through a chat interface. Key features of the framework include: integration of ROS with an AI agent connected to a plethora of open-source and commercial LLMs, automatic extraction of a behavior from the LLM output and execution of ROS actions/services, support for three behavior modes (sequence, behavior tree, state machine), imitation learning for adding new robot actions to the library of possible actions, and LLM reflection via human and environment feedback. Extensive experiments validate the framework, showcasing robustness, scalability, and versatility in diverse scenarios, including long-horizon tasks, tabletop rearrangements, and remote supervisory control. To facilitate the adoption of our framework and support the reproduction of our results, we have made our code open-source. You can access it at: https://github.com/huawei-noah/HEBO/tree/master/ROSLLM.
A Survey on Vision-Language-Action Models for Embodied AI
May 23, 2024



Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.