 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobility-Aware Asynchronous Federated Learning with Dynamic Sparsification
Jun 08, 2025Asynchronous Federated Learning (AFL) enables distributed model training across multiple mobile devices, allowing each device to independently update its local model without waiting for others. However, device mobility introduces intermittent connectivity, which necessitates gradient sparsification and leads to model staleness, jointly affecting AFL convergence. This paper develops a theoretical model to characterize the interplay among sparsification, model staleness and mobility-induced contact patterns, and their joint impact on AFL convergence. Based on the analysis, we propose a mobility-aware dynamic sparsification (MADS) algorithm that optimizes the sparsification degree based on contact time and model staleness. Closed-form solutions are derived, showing that under low-speed conditions, MADS increases the sparsification degree to enhance convergence, while under high-speed conditions, it reduces the sparsification degree to guarantee reliable uploads within limited contact time. Experimental results validate the theoretical findings. Compared with the state-of-the-art benchmarks, the MADS algorithm increases the image classification accuracy on the CIFAR-10 dataset by 8.76% and reduces the average displacement error in the Argoverse trajectory prediction dataset by 9.46%.
CPathAgent: An Agent-based Foundation Model for Interpretable High-Resolution Pathology Image Analysis Mimicking Pathologists' Diagnostic Logic
May 26, 2025Recent advances in computational pathology have led to the emergence of numerous foundation models. However, these approaches fail to replicate the diagnostic process of pathologists, as they either simply rely on general-purpose encoders with multi-instance learning for classification or directly apply multimodal models to generate reports from images. A significant limitation is their inability to emulate the diagnostic logic employed by pathologists, who systematically examine slides at low magnification for overview before progressively zooming in on suspicious regions to formulate comprehensive diagnoses. To address this gap, we introduce CPathAgent, an innovative agent-based model that mimics pathologists' reasoning processes by autonomously executing zoom-in/out and navigation operations across pathology images based on observed visual features. To achieve this, we develop a multi-stage training strategy unifying patch-level, region-level, and whole-slide capabilities within a single model, which is essential for mimicking pathologists, who require understanding and reasoning capabilities across all three scales. This approach generates substantially more detailed and interpretable diagnostic reports compared to existing methods, particularly for huge region understanding. Additionally, we construct an expert-validated PathMMU-HR$^{2}$, the first benchmark for huge region analysis, a critical intermediate scale between patches and whole slides, as diagnosticians typically examine several key regions rather than entire slides at once. Extensive experiments demonstrate that CPathAgent consistently outperforms existing approaches across three scales of benchmarks, validating the effectiveness of our agent-based diagnostic approach and highlighting a promising direction for the future development of computational pathology.
FASR-Net: Unsupervised Shadow Removal Leveraging Inherent Frequency Priors
Apr 08, 2025Shadow removal is challenging due to the complex interaction of geometry, lighting, and environmental factors. Existing unsupervised methods often overlook shadow-specific priors, leading to incomplete shadow recovery. To address this issue, we propose a novel unsupervised Frequency Aware Shadow Removal Network (FASR-Net), which leverages the inherent frequency characteristics of shadow regions. Specifically, the proposed Wavelet Attention Downsampling Module (WADM) integrates wavelet-based image decomposition and deformable attention, effectively breaking down the image into frequency components to enhance shadow details within specific frequency bands. We also introduce several new loss functions for precise shadow-free image reproduction: a frequency loss to capture image component details, a brightness-chromaticity loss that references the chromaticity of shadow-free regions, and an alignment loss to ensure smooth transitions between shadowed and shadow-free regions. Experimental results on the AISTD and SRD datasets demonstrate that our method achieves superior shadow removal performance.
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Apr 07, 2025Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead. While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks. Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks. We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance. All quantized models and codes will be open-sourced in https://github.com/ruikangliu/Quantized-Reasoning-Models.
Towards Effective and Efficient Context-aware Nucleus Detection in Histopathology Whole Slide Images
Mar 04, 2025
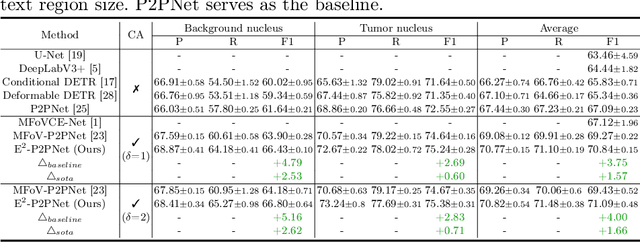
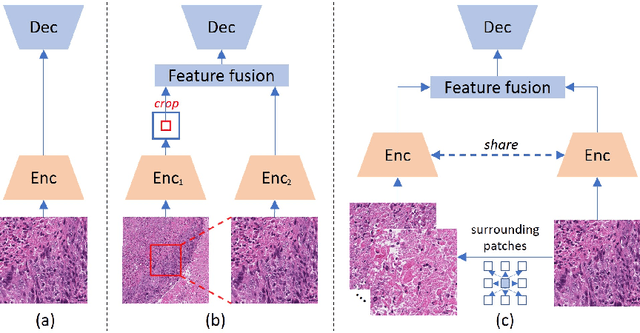
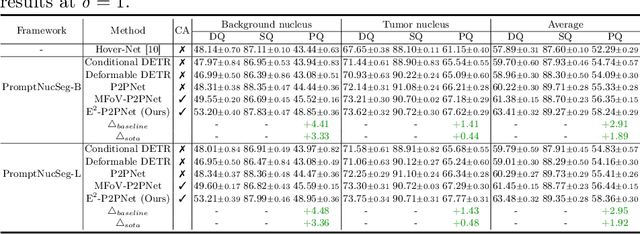
Nucleus detection in histopathology whole slide images (WSIs) is crucial for a broad spectrum of clinical applications. Current approaches for nucleus detection in gigapixel WSIs utilize a sliding window methodology, which overlooks boarder contextual information (eg, tissue structure) and easily leads to inaccurate predictions. To address this problem, recent studies additionally crops a large Filed-of-View (FoV) region around each sliding window to extract contextual features. However, such methods substantially increases the inference latency. In this paper, we propose an effective and efficient context-aware nucleus detection algorithm. Specifically, instead of leveraging large FoV regions, we aggregate contextual clues from off-the-shelf features of historically visited sliding windows. This design greatly reduces computational overhead. Moreover, compared to large FoV regions at a low magnification, the sliding window patches have higher magnification and provide finer-grained tissue details, thereby enhancing the detection accuracy. To further improve the efficiency, we propose a grid pooling technique to compress dense feature maps of each patch into a few contextual tokens. Finally, we craft OCELOT-seg, the first benchmark dedicated to context-aware nucleus instance segmentation. Code, dataset, and model checkpoints will be available at https://github.com/windygoo/PathContext.
CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Computational Pathology
Dec 16, 2024The emergence of large multimodal models (LMMs) has brought significant advancements to pathology. Previous research has primarily focused on separately training patch-level and whole-slide image (WSI)-level models, limiting the integration of learned knowledge across patches and WSIs, and resulting in redundant models. In this work, we introduce CPath-Omni, the first 15-billion-parameter LMM designed to unify both patch and WSI level image analysis, consolidating a variety of tasks at both levels, including classification, visual question answering, captioning, and visual referring prompting. Extensive experiments demonstrate that CPath-Omni achieves state-of-the-art (SOTA) performance across seven diverse tasks on 39 out of 42 datasets, outperforming or matching task-specific models trained for individual tasks. Additionally, we develop a specialized pathology CLIP-based visual processor for CPath-Omni, CPath-CLIP, which, for the first time, integrates different vision models and incorporates a large language model as a text encoder to build a more powerful CLIP model, which achieves SOTA performance on nine zero-shot and four few-shot datasets. Our findings highlight CPath-Omni's ability to unify diverse pathology tasks, demonstrating its potential to streamline and advance the field of foundation model in pathology.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024



Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
FlatQuant: Flatness Matters for LLM Quantization
Oct 12, 2024



Recently, quantization has been widely used for the compression and acceleration of large language models~(LLMs). Due to the outliers in LLMs, it is crucial to flatten weights and activations to minimize quantization error with the equally spaced quantization points. Prior research explores various pre-quantization transformations to suppress outliers, such as per-channel scaling and Hadamard transformation. However, we observe that these transformed weights and activations can still remain steep and outspread. In this paper, we propose FlatQuant (Fast and Learnable Affine Transformation), a new post-training quantization approach to enhance flatness of weights and activations. Our approach identifies optimal affine transformations tailored to each linear layer, calibrated in hours via a lightweight objective. To reduce runtime overhead, we apply Kronecker decomposition to the transformation matrices, and fuse all operations in FlatQuant into a single kernel. Extensive experiments show that FlatQuant sets up a new state-of-the-art quantization benchmark. For instance, it achieves less than $\textbf{1}\%$ accuracy drop for W4A4 quantization on the LLaMA-3-70B model, surpassing SpinQuant by $\textbf{7.5}\%$. For inference latency, FlatQuant reduces the slowdown induced by pre-quantization transformation from 0.26x of QuaRot to merely $\textbf{0.07x}$, bringing up to $\textbf{2.3x}$ speedup for prefill and $\textbf{1.7x}$ speedup for decoding, respectively. Code is available at: \url{https://github.com/ruikangliu/FlatQuant}.
DiffCP: Ultra-Low Bit Collaborative Perception via Diffusion Model
Sep 29, 2024



Collaborative perception (CP) is emerging as a promising solution to the inherent limitations of stand-alone intelligence. However, current wireless communication systems are unable to support feature-level and raw-level collaborative algorithms due to their enormous bandwidth demands. In this paper, we propose DiffCP, a novel CP paradigm that utilizes a specialized diffusion model to efficiently compress the sensing information of collaborators. By incorporating both geometric and semantic conditions into the generative model, DiffCP enables feature-level collaboration with an ultra-low communication cost, advancing the practical implementation of CP systems. This paradigm can be seamlessly integrated into existing CP algorithms to enhance a wide range of downstream tasks. Through extensive experimentation, we investigate the trade-offs between communication, computation, and performance. Numerical results demonstrate that DiffCP can significantly reduce communication costs by 14.5-fold while maintaining the same performance as the state-of-the-art algorithm.
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Sep 04, 2024



This paper introduces MMMU-Pro, a robust version of the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark. MMMU-Pro rigorously assesses multimodal models' true understanding and reasoning capabilities through a three-step process based on MMMU: (1) filtering out questions answerable by text-only models, (2) augmenting candidate options, and (3) introducing a vision-only input setting where questions are embedded within images. This setting challenges AI to truly "see" and "read" simultaneously, testing a fundamental human cognitive skill of seamlessly integrating visual and textual information. Results show that model performance is substantially lower on MMMU-Pro than on MMMU, ranging from 16.8% to 26.9% across models. We explore the impact of OCR prompts and Chain of Thought (CoT) reasoning, finding that OCR prompts have minimal effect while CoT generally improves performance. MMMU-Pro provides a more rigorous evaluation tool, closely mimicking real-world scenarios and offering valuable directions for future research in multimodal AI.