 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCGD: Collective Gradient Divergence Optimized Scheduling for Wireless Federated Learning
Jun 09, 2025Federated learning (FL) is a promising paradigm for multiple devices to cooperatively train a model. When applied in wireless networks, two issues consistently affect the performance of FL, i.e., data heterogeneity of devices and limited bandwidth. Many papers have investigated device scheduling strategies considering the two issues. However, most of them recognize data heterogeneity as a property of individual devices. In this paper, we prove that the convergence speed of FL is affected by the sum of device-level and sample-level collective gradient divergence (CGD). The device-level CGD refers to the gradient divergence of the scheduled device group, instead of the sum of the individual device divergence. The sample-level CGD is statistically upper bounded by sampling variance, which is inversely proportional to the total number of samples scheduled for local update. To derive a tractable form of the device-level CGD, we further consider a classification problem and transform it into the weighted earth moving distance (WEMD) between the group distribution and the global distribution. Then we propose FedCGD algorithm to minimize the sum of multi-level CGDs by balancing WEMD and sampling variance, within polynomial time. Simulation shows that the proposed strategy increases classification accuracy on the CIFAR-10 dataset by up to 4.2\% while scheduling 41.8\% fewer devices, and flexibly switches between reducing WEMD and reducing sampling variance.
Mobility-Aware Asynchronous Federated Learning with Dynamic Sparsification
Jun 08, 2025Asynchronous Federated Learning (AFL) enables distributed model training across multiple mobile devices, allowing each device to independently update its local model without waiting for others. However, device mobility introduces intermittent connectivity, which necessitates gradient sparsification and leads to model staleness, jointly affecting AFL convergence. This paper develops a theoretical model to characterize the interplay among sparsification, model staleness and mobility-induced contact patterns, and their joint impact on AFL convergence. Based on the analysis, we propose a mobility-aware dynamic sparsification (MADS) algorithm that optimizes the sparsification degree based on contact time and model staleness. Closed-form solutions are derived, showing that under low-speed conditions, MADS increases the sparsification degree to enhance convergence, while under high-speed conditions, it reduces the sparsification degree to guarantee reliable uploads within limited contact time. Experimental results validate the theoretical findings. Compared with the state-of-the-art benchmarks, the MADS algorithm increases the image classification accuracy on the CIFAR-10 dataset by 8.76% and reduces the average displacement error in the Argoverse trajectory prediction dataset by 9.46%.
Dynamic Scheduling for Vehicle-to-Vehicle Communications Enhanced Federated Learning
Jun 25, 2024



Leveraging the computing and sensing capabilities of vehicles, vehicular federated learning (VFL) has been applied to edge training for connected vehicles. The dynamic and interconnected nature of vehicular networks presents unique opportunities to harness direct vehicle-to-vehicle (V2V) communications, enhancing VFL training efficiency. In this paper, we formulate a stochastic optimization problem to optimize the VFL training performance, considering the energy constraints and mobility of vehicles, and propose a V2V-enhanced dynamic scheduling (VEDS) algorithm to solve it. The model aggregation requirements of VFL and the limited transmission time due to mobility result in a stepwise objective function, which presents challenges in solving the problem. We thus propose a derivative-based drift-plus-penalty method to convert the long-term stochastic optimization problem to an online mixed integer nonlinear programming (MINLP) problem, and provide a theoretical analysis to bound the performance gap between the online solution and the offline optimal solution. Further analysis of the scheduling priority reduces the original problem into a set of convex optimization problems, which are efficiently solved using the interior-point method. Experimental results demonstrate that compared with the state-of-the-art benchmarks, the proposed algorithm enhances the image classification accuracy on the CIFAR-10 dataset by 3.18% and reduces the average displacement errors on the Argoverse trajectory prediction dataset by 10.21%.
Mobility Accelerates Learning: Convergence Analysis on Hierarchical Federated Learning in Vehicular Networks
Jan 18, 2024



Hierarchical federated learning (HFL) enables distributed training of models across multiple devices with the help of several edge servers and a cloud edge server in a privacy-preserving manner. In this paper, we consider HFL with highly mobile devices, mainly targeting at vehicular networks. Through convergence analysis, we show that mobility influences the convergence speed by both fusing the edge data and shuffling the edge models. While mobility is usually considered as a challenge from the perspective of communication, we prove that it increases the convergence speed of HFL with edge-level heterogeneous data, since more diverse data can be incorporated. Furthermore, we demonstrate that a higher speed leads to faster convergence, since it accelerates the fusion of data. Simulation results show that mobility increases the model accuracy of HFL by up to 15.1% when training a convolutional neural network on the CIFAR-10 dataset.
Data-Heterogeneous Hierarchical Federated Learning with Mobility
Jun 19, 2023Federated learning enables distributed training of machine learning (ML) models across multiple devices in a privacy-preserving manner. Hierarchical federated learning (HFL) is further proposed to meet the requirements of both latency and coverage. In this paper, we consider a data-heterogeneous HFL scenario with mobility, mainly targeting vehicular networks. We derive the convergence upper bound of HFL with respect to mobility and data heterogeneity, and analyze how mobility impacts the performance of HFL. While mobility is considered as a challenge from a communication point of view, our goal here is to exploit mobility to improve the learning performance by mitigating data heterogeneity. Simulation results verify the analysis and show that mobility can indeed improve the model accuracy by up to 15.1\% when training a convolutional neural network on the CIFAR-10 dataset using HFL.
CRT-Net: A Generalized and Scalable Framework for the Computer-Aided Diagnosis of Electrocardiogram Signals
May 28, 2021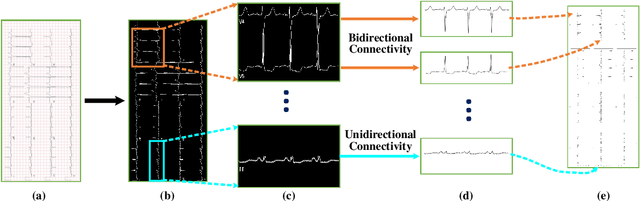
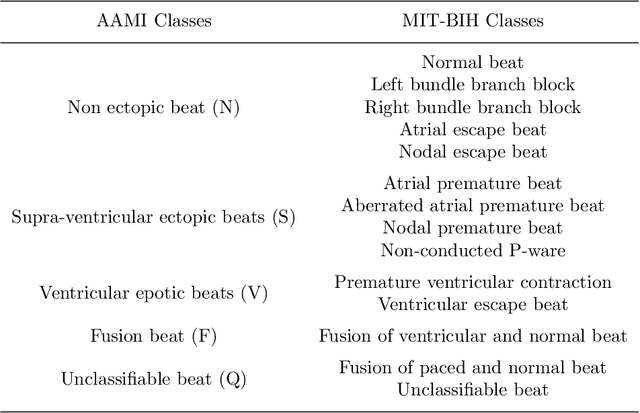
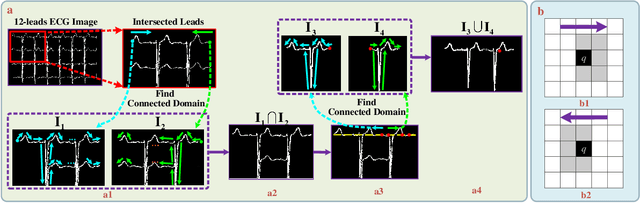
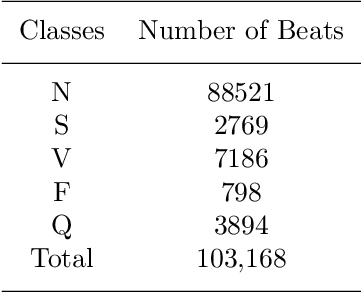
Electrocardiogram (ECG) signals play critical roles in the clinical screening and diagnosis of many types of cardiovascular diseases. Despite deep neural networks that have been greatly facilitated computer-aided diagnosis (CAD) in many clinical tasks, the variability and complexity of ECG in the clinic still pose significant challenges in both diagnostic performance and clinical applications. In this paper, we develop a robust and scalable framework for the clinical recognition of ECG. Considering the fact that hospitals generally record ECG signals in the form of graphic waves of 2-D images, we first extract the graphic waves of 12-lead images into numerical 1-D ECG signals by a proposed bi-directional connectivity method. Subsequently, a novel deep neural network, namely CRT-Net, is designed for the fine-grained and comprehensive representation and recognition of 1-D ECG signals. The CRT-Net can well explore waveform features, morphological characteristics and time domain features of ECG by embedding convolution neural network(CNN), recurrent neural network(RNN), and transformer module in a scalable deep model, which is especially suitable in clinical scenarios with different lengths of ECG signals captured from different devices. The proposed framework is first evaluated on two widely investigated public repositories, demonstrating the superior performance of ECG recognition in comparison with state-of-the-art. Moreover, we validate the effectiveness of our proposed bi-directional connectivity and CRT-Net on clinical ECG images collected from the local hospital, including 258 patients with chronic kidney disease (CKD), 351 patients with Type-2 Diabetes (T2DM), and around 300 patients in the control group. In the experiments, our methods can achieve excellent performance in the recognition of these two types of disease.