 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale multilingual audio visual dubbing
Nov 06, 2020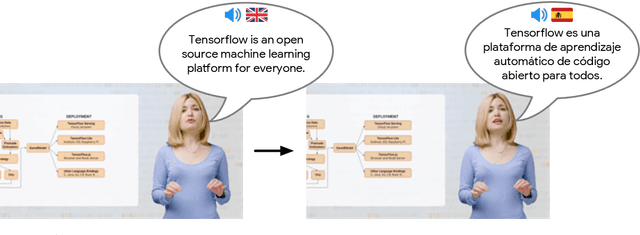
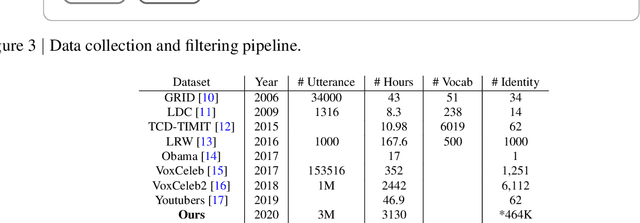
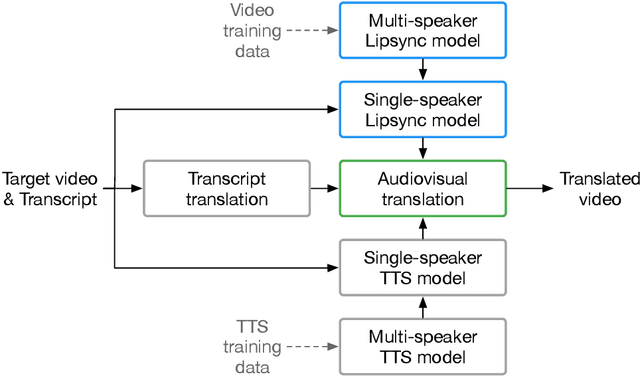
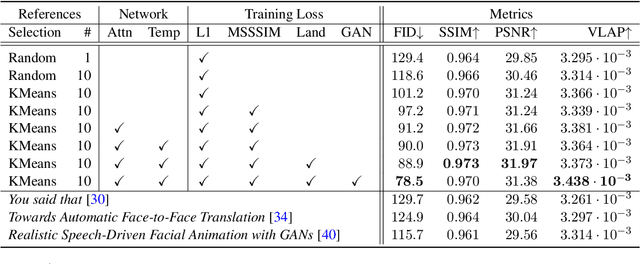
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
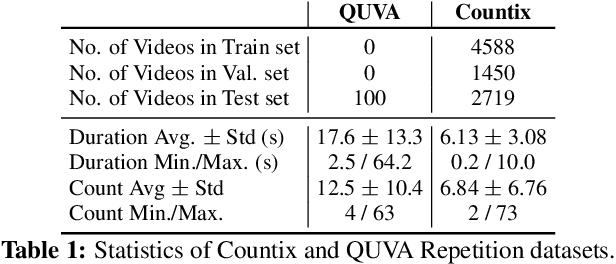


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
Self-Supervised Sim-to-Real Adaptation for Visual Robotic Manipulation
Oct 21, 2019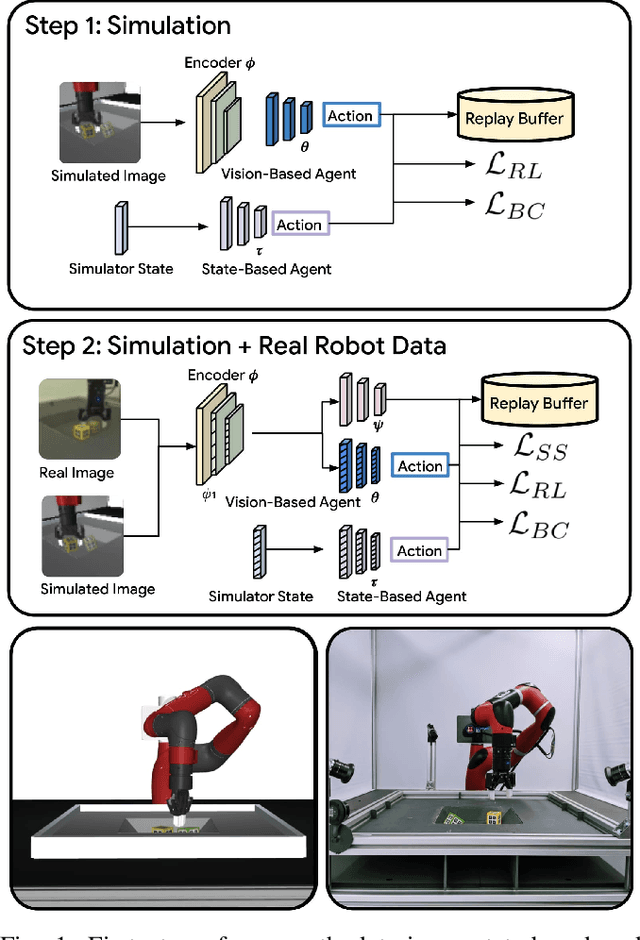

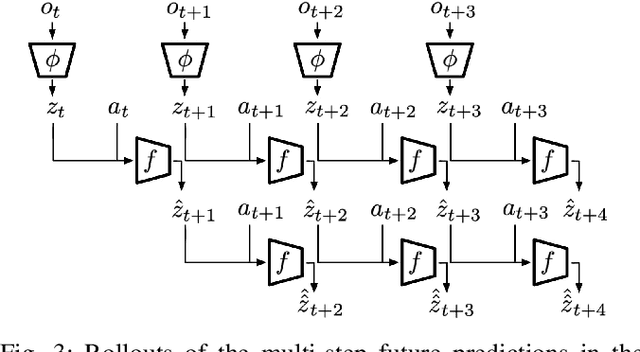
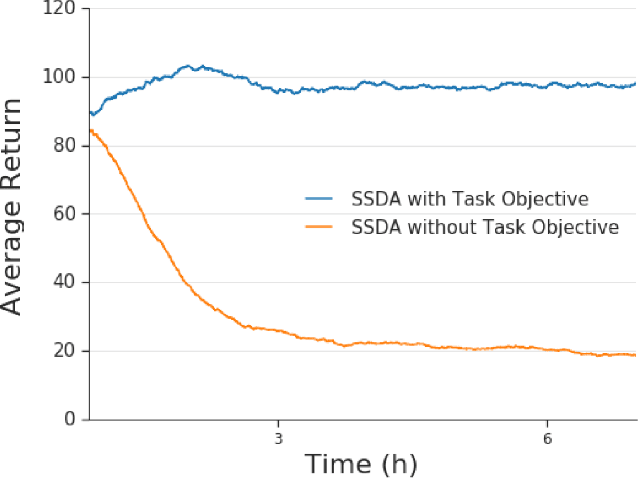
Collecting and automatically obtaining reward signals from real robotic visual data for the purposes of training reinforcement learning algorithms can be quite challenging and time-consuming. Methods for utilizing unlabeled data can have a huge potential to further accelerate robotic learning. We consider here the problem of performing manipulation tasks from pixels. In such tasks, choosing an appropriate state representation is crucial for planning and control. This is even more relevant with real images where noise, occlusions and resolution affect the accuracy and reliability of state estimation. In this work, we learn a latent state representation implicitly with deep reinforcement learning in simulation, and then adapt it to the real domain using unlabeled real robot data. We propose to do so by optimizing sequence-based self supervised objectives. These exploit the temporal nature of robot experience, and can be common in both the simulated and real domains, without assuming any alignment of underlying states in simulated and unlabeled real images. We propose Contrastive Forward Dynamics loss, which combines dynamics model learning with time-contrastive techniques. The learned state representation that results from our methods can be used to robustly solve a manipulation task in simulation and to successfully transfer the learned skill on a real system. We demonstrate the effectiveness of our approaches by training a vision-based reinforcement learning agent for cube stacking. Agents trained with our method, using only 5 hours of unlabeled real robot data for adaptation, shows a clear improvement over domain randomization, and standard visual domain adaptation techniques for sim-to-real transfer.
A Framework for Data-Driven Robotics
Sep 26, 2019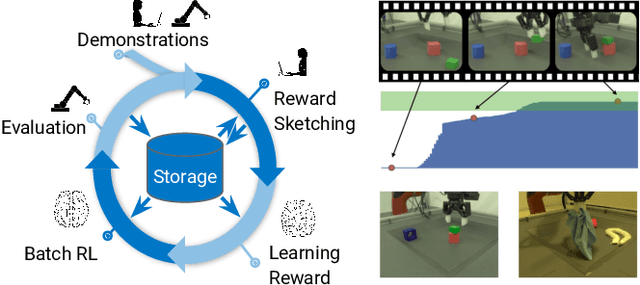
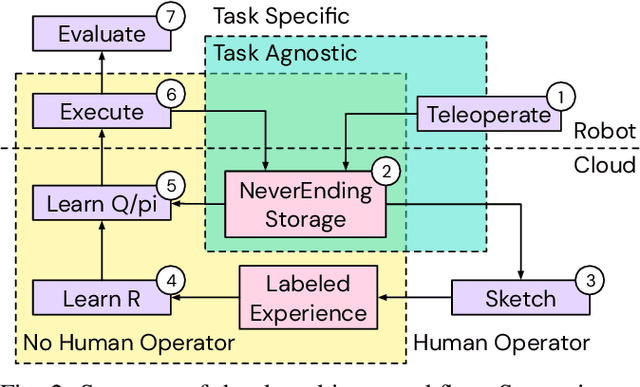
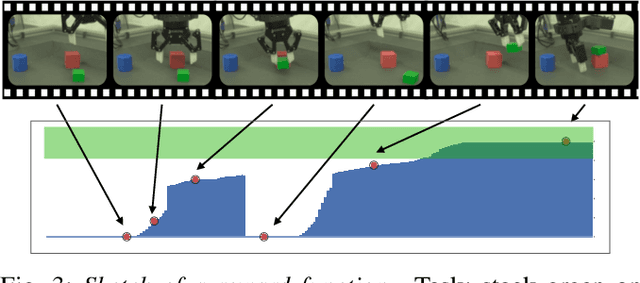
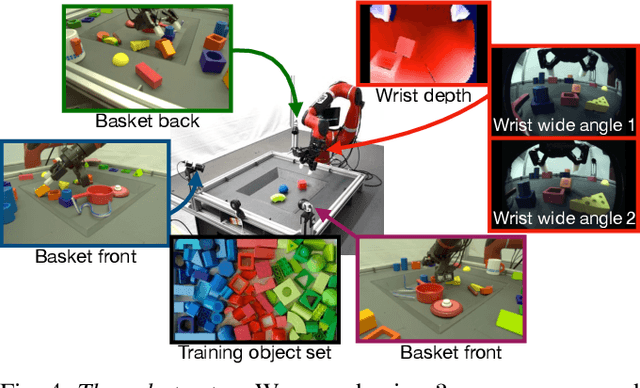
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
Temporal Cycle-Consistency Learning
Apr 16, 2019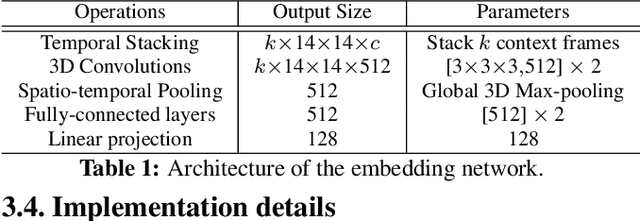
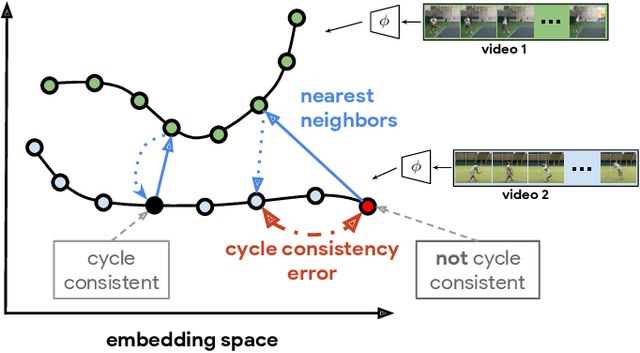

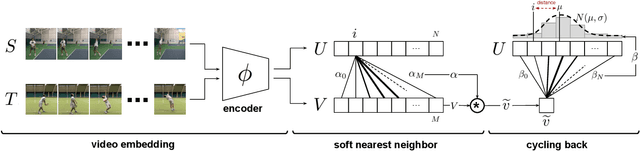
We introduce a self-supervised representation learning method based on the task of temporal alignment between videos. The method trains a network using temporal cycle consistency (TCC), a differentiable cycle-consistency loss that can be used to find correspondences across time in multiple videos. The resulting per-frame embeddings can be used to align videos by simply matching frames using the nearest-neighbors in the learned embedding space. To evaluate the power of the embeddings, we densely label the Pouring and Penn Action video datasets for action phases. We show that (i) the learned embeddings enable few-shot classification of these action phases, significantly reducing the supervised training requirements; and (ii) TCC is complementary to other methods of self-supervised learning in videos, such as Shuffle and Learn and Time-Contrastive Networks. The embeddings are also used for a number of applications based on alignment (dense temporal correspondence) between video pairs, including transfer of metadata of synchronized modalities between videos (sounds, temporal semantic labels), synchronized playback of multiple videos, and anomaly detection. Project webpage: https://sites.google.com/view/temporal-cycle-consistency .
Recipe1M: A Dataset for Learning Cross-Modal Embeddings for Cooking Recipes and Food Images
Oct 14, 2018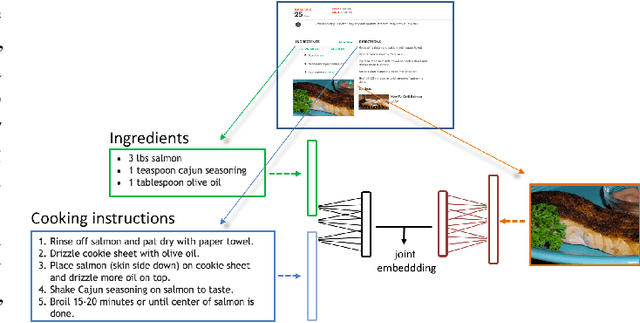
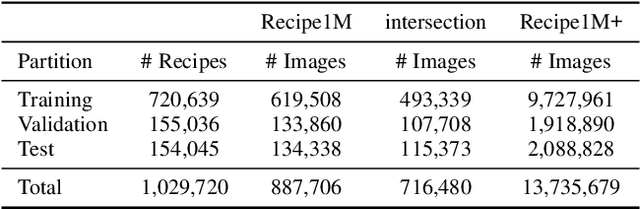

In this paper, we introduce Recipe1M, a new large-scale, structured corpus of over one million cooking recipes and 13 million food images. As the largest publicly available collection of recipe data, Recipe1M affords the ability to train high-capacity models on aligned, multi-modal data. Using these data, we train a neural network to learn a joint embedding of recipes and images that yields impressive results on an image-recipe retrieval task. Moreover, we demonstrate that regularization via the addition of a high-level classification objective both improves retrieval performance to rival that of humans and enables semantic vector arithmetic. We postulate that these embeddings will provide a basis for further exploration of the Recipe1M dataset and food and cooking in general. Code, data and models are publicly available.
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
Oct 11, 2018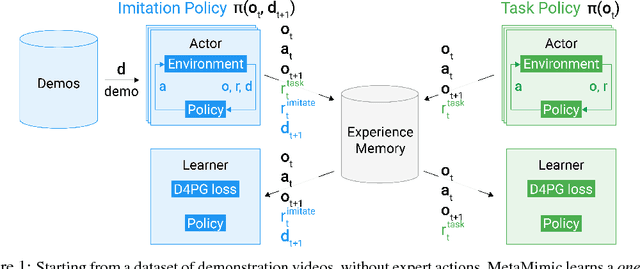
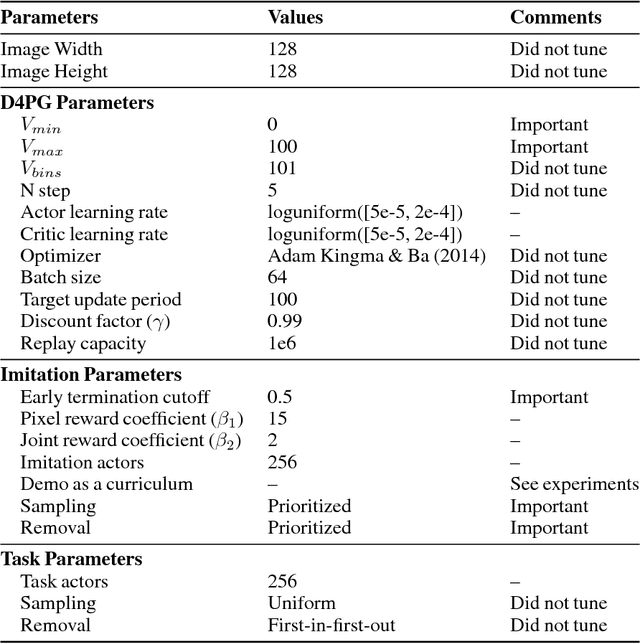
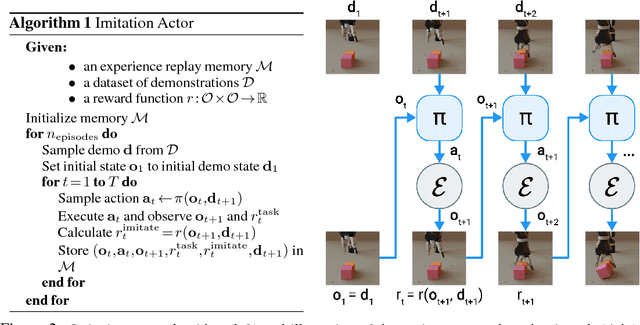
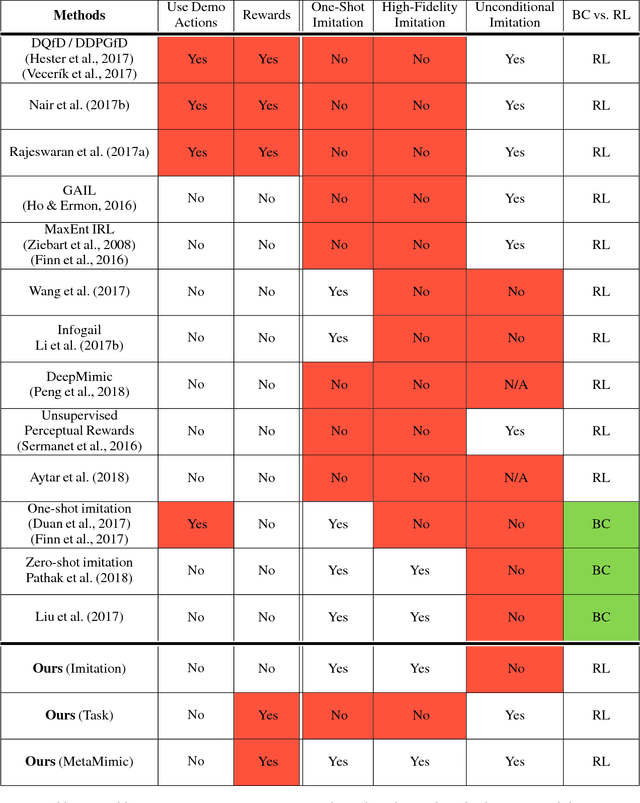
Humans are experts at high-fidelity imitation -- closely mimicking a demonstration, often in one attempt. Humans use this ability to quickly solve a task instance, and to bootstrap learning of new tasks. Achieving these abilities in autonomous agents is an open problem. In this paper, we introduce an off-policy RL algorithm (MetaMimic) to narrow this gap. MetaMimic can learn both (i) policies for high-fidelity one-shot imitation of diverse novel skills, and (ii) policies that enable the agent to solve tasks more efficiently than the demonstrators. MetaMimic relies on the principle of storing all experiences in a memory and replaying these to learn massive deep neural network policies by off-policy RL. This paper introduces, to the best of our knowledge, the largest existing neural networks for deep RL and shows that larger networks with normalization are needed to achieve one-shot high-fidelity imitation on a challenging manipulation task. The results also show that both types of policy can be learned from vision, in spite of the task rewards being sparse, and without access to demonstrator actions.
Playing hard exploration games by watching YouTube
May 29, 2018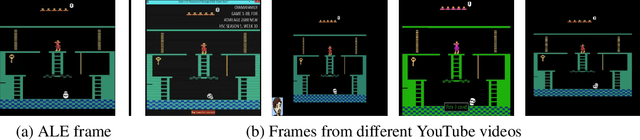

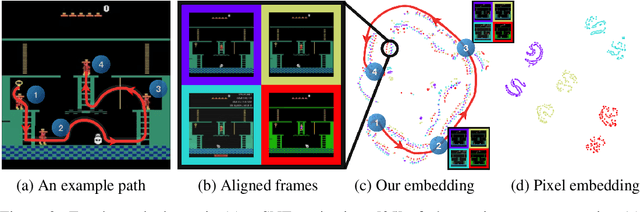
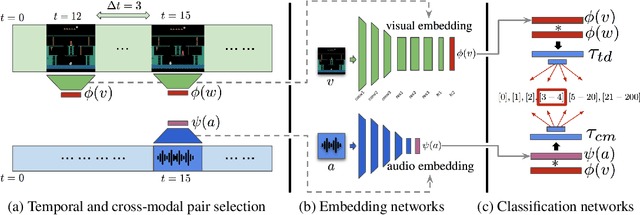
Deep reinforcement learning methods traditionally struggle with tasks where environment rewards are particularly sparse. One successful method of guiding exploration in these domains is to imitate trajectories provided by a human demonstrator. However, these demonstrations are typically collected under artificial conditions, i.e. with access to the agent's exact environment setup and the demonstrator's action and reward trajectories. Here we propose a two-stage method that overcomes these limitations by relying on noisy, unaligned footage without access to such data. First, we learn to map unaligned videos from multiple sources to a common representation using self-supervised objectives constructed over both time and modality (i.e. vision and sound). Second, we embed a single YouTube video in this representation to construct a reward function that encourages an agent to imitate human gameplay. This method of one-shot imitation allows our agent to convincingly exceed human-level performance on the infamously hard exploration games Montezuma's Revenge, Pitfall! and Private Eye for the first time, even if the agent is not presented with any environment rewards.
Exploiting Convolution Filter Patterns for Transfer Learning
Aug 23, 2017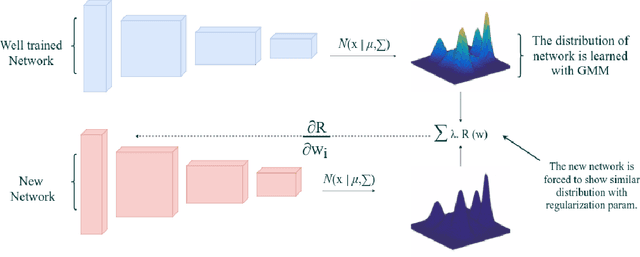
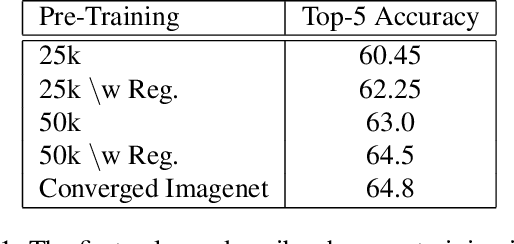

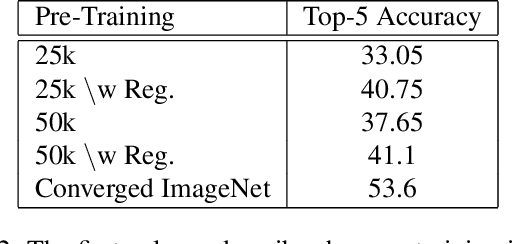
In this paper, we introduce a new regularization technique for transfer learning. The aim of the proposed approach is to capture statistical relationships among convolution filters learned from a well-trained network and transfer this knowledge to another network. Since convolution filters of the prevalent deep Convolutional Neural Network (CNN) models share a number of similar patterns, in order to speed up the learning procedure, we capture such correlations by Gaussian Mixture Models (GMMs) and transfer them using a regularization term. We have conducted extensive experiments on the CIFAR10, Places2, and CMPlaces datasets to assess generalizability, task transferability, and cross-model transferability of the proposed approach, respectively. The experimental results show that the feature representations have efficiently been learned and transferred through the proposed statistical regularization scheme. Moreover, our method is an architecture independent approach, which is applicable for a variety of CNN architectures.
See, Hear, and Read: Deep Aligned Representations
Jun 03, 2017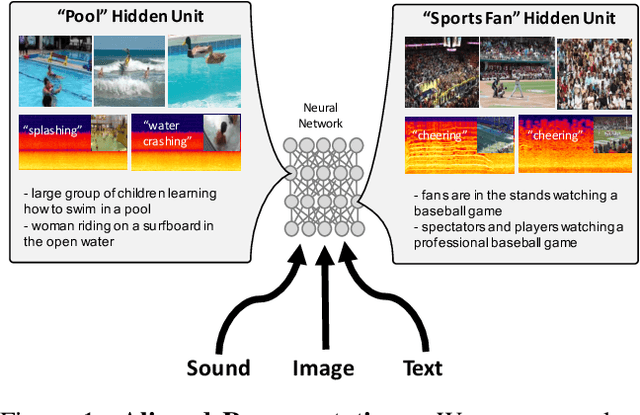
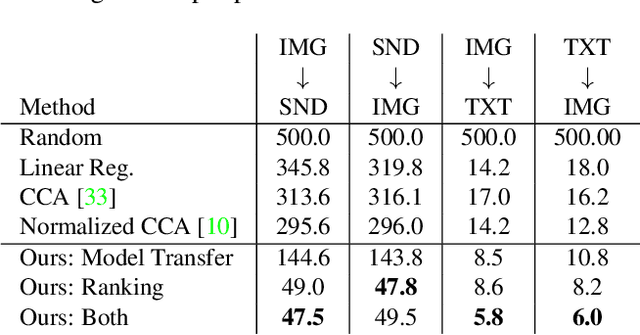


We capitalize on large amounts of readily-available, synchronous data to learn a deep discriminative representations shared across three major natural modalities: vision, sound and language. By leveraging over a year of sound from video and millions of sentences paired with images, we jointly train a deep convolutional network for aligned representation learning. Our experiments suggest that this representation is useful for several tasks, such as cross-modal retrieval or transferring classifiers between modalities. Moreover, although our network is only trained with image+text and image+sound pairs, it can transfer between text and sound as well, a transfer the network never observed during training. Visualizations of our representation reveal many hidden units which automatically emerge to detect concepts, independent of the modality.