 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETAIN: Interactive Tool for Regression Testing Guided LLM Migration
Sep 05, 2024



Large Language Models (LLMs) are increasingly integrated into diverse applications. The rapid evolution of LLMs presents opportunities for developers to enhance applications continuously. However, this constant adaptation can also lead to performance regressions during model migrations. While several interactive tools have been proposed to streamline the complexity of prompt engineering, few address the specific requirements of regression testing for LLM Migrations. To bridge this gap, we introduce RETAIN (REgression Testing guided LLM migrAtIoN), a tool designed explicitly for regression testing in LLM Migrations. RETAIN comprises two key components: an interactive interface tailored to regression testing needs during LLM migrations, and an error discovery module that facilitates understanding of differences in model behaviors. The error discovery module generates textual descriptions of various errors or differences between model outputs, providing actionable insights for prompt refinement. Our automatic evaluation and empirical user studies demonstrate that RETAIN, when compared to manual evaluation, enabled participants to identify twice as many errors, facilitated experimentation with 75% more prompts, and achieves 12% higher metric scores in a given time frame.
MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering
Aug 16, 2024



Recent advancements in retrieval-augmented generation (RAG) have demonstrated impressive performance in the question-answering (QA) task. However, most previous works predominantly focus on text-based answers. While some studies address multimodal data, they still fall short in generating comprehensive multimodal answers, particularly for explaining concepts or providing step-by-step tutorials on how to accomplish specific goals. This capability is especially valuable for applications such as enterprise chatbots and settings such as customer service and educational systems, where the answers are sourced from multimodal data. In this paper, we introduce a simple and effective framework named MuRAR (Multimodal Retrieval and Answer Refinement). MuRAR enhances text-based answers by retrieving relevant multimodal data and refining the responses to create coherent multimodal answers. This framework can be easily extended to support multimodal answers in enterprise chatbots with minimal modifications. Human evaluation results indicate that multimodal answers generated by MuRAR are more useful and readable compared to plain text answers.
ConvKGYarn: Spinning Configurable and Scalable Conversational Knowledge Graph QA datasets with Large Language Models
Aug 12, 2024



The rapid advancement of Large Language Models (LLMs) and conversational assistants necessitates dynamic, scalable, and configurable conversational datasets for training and evaluation. These datasets must accommodate diverse user interaction modes, including text and voice, each presenting unique modeling challenges. Knowledge Graphs (KGs), with their structured and evolving nature, offer an ideal foundation for current and precise knowledge. Although human-curated KG-based conversational datasets exist, they struggle to keep pace with the rapidly changing user information needs. We present ConvKGYarn, a scalable method for generating up-to-date and configurable conversational KGQA datasets. Qualitative psychometric analyses confirm our method can generate high-quality datasets rivaling a popular conversational KGQA dataset while offering it at scale and covering a wide range of human-interaction configurations. We showcase its utility by testing LLMs on diverse conversations - exploring model behavior on conversational KGQA sets with different configurations grounded in the same KG fact set. Our results highlight the ability of ConvKGYarn to improve KGQA foundations and evaluate parametric knowledge of LLMs, thus offering a robust solution to the constantly evolving landscape of conversational assistants.
APE: Active Learning-based Tooling for Finding Informative Few-shot Examples for LLM-based Entity Matching
Jul 29, 2024
Prompt engineering is an iterative procedure often requiring extensive manual effort to formulate suitable instructions for effectively directing large language models (LLMs) in specific tasks. Incorporating few-shot examples is a vital and effective approach to providing LLMs with precise instructions, leading to improved LLM performance. Nonetheless, identifying the most informative demonstrations for LLMs is labor-intensive, frequently entailing sifting through an extensive search space. In this demonstration, we showcase a human-in-the-loop tool called APE (Active Prompt Engineering) designed for refining prompts through active learning. Drawing inspiration from active learning, APE iteratively selects the most ambiguous examples for human feedback, which will be transformed into few-shot examples within the prompt. The demo recording can be found with the submission or be viewed at https://youtu.be/OwQ6MQx53-Y.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024



Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
AGRaME: Any-Granularity Ranking with Multi-Vector Embeddings
May 23, 2024



Ranking is a fundamental and popular problem in search. However, existing ranking algorithms usually restrict the granularity of ranking to full passages or require a specific dense index for each desired level of granularity. Such lack of flexibility in granularity negatively affects many applications that can benefit from more granular ranking, such as sentence-level ranking for open-domain question-answering, or proposition-level ranking for attribution. In this work, we introduce the idea of any-granularity ranking, which leverages multi-vector embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level of granularity. We propose a multi-granular contrastive loss for training multi-vector approaches, and validate its utility with both sentences and propositions as ranking units. Finally, we demonstrate the application of proposition-level ranking to post-hoc citation addition in retrieval-augmented generation, surpassing the performance of prompt-driven citation generation.
Entity Disambiguation via Fusion Entity Decoding
Apr 02, 2024
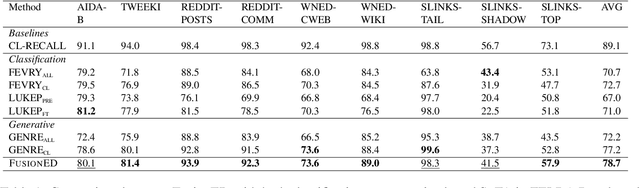


Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.
Increasing Coverage and Precision of Textual Information in Multilingual Knowledge Graphs
Nov 27, 2023



Recent work in Natural Language Processing and Computer Vision has been using textual information -- e.g., entity names and descriptions -- available in knowledge graphs to ground neural models to high-quality structured data. However, when it comes to non-English languages, the quantity and quality of textual information are comparatively scarce. To address this issue, we introduce the novel task of automatic Knowledge Graph Enhancement (KGE) and perform a thorough investigation on bridging the gap in both the quantity and quality of textual information between English and non-English languages. More specifically, we: i) bring to light the problem of increasing multilingual coverage and precision of entity names and descriptions in Wikidata; ii) demonstrate that state-of-the-art methods, namely, Machine Translation (MT), Web Search (WS), and Large Language Models (LLMs), struggle with this task; iii) present M-NTA, a novel unsupervised approach that combines MT, WS, and LLMs to generate high-quality textual information; and, iv) study the impact of increasing multilingual coverage and precision of non-English textual information in Entity Linking, Knowledge Graph Completion, and Question Answering. As part of our effort towards better multilingual knowledge graphs, we also introduce WikiKGE-10, the first human-curated benchmark to evaluate KGE approaches in 10 languages across 7 language families.
FairytaleCQA: Integrating a Commonsense Knowledge Graph into Children's Storybook Narratives
Nov 16, 2023



AI models (including LLM) often rely on narrative question-answering (QA) datasets to provide customized QA functionalities to support downstream children education applications; however, existing datasets only include QA pairs that are grounded within the given storybook content, but children can learn more when teachers refer the storybook content to real-world knowledge (e.g., commonsense knowledge). We introduce the FairytaleCQA dataset, which is annotated by children education experts, to supplement 278 storybook narratives with educationally appropriate commonsense knowledge. The dataset has 5,868 QA pairs that not only originate from the storybook narrative but also contain the commonsense knowledge grounded by an external knowledge graph (i.e., ConceptNet). A follow-up experiment shows that a smaller model (T5-large) fine-tuned with FairytaleCQA reliably outperforms much larger prompt-engineered LLM (e.g., GPT-4) in this new QA-pair generation task (QAG). This result suggests that: 1) our dataset brings novel challenges to existing LLMs, and 2) human experts' data annotation are still critical as they have much nuanced knowledge that LLMs do not know in the children educational domain.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023



Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.