 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
May 16, 2025Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs' abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
DDAE++: Enhancing Diffusion Models Towards Unified Generative and Discriminative Learning
May 16, 2025While diffusion models have gained prominence in image synthesis, their generative pre-training has been shown to yield discriminative representations, paving the way towards unified visual generation and understanding. However, two key questions remain: 1) Can these representations be leveraged to improve the training of diffusion models themselves, rather than solely benefiting downstream tasks? 2) Can the feature quality be enhanced to rival or even surpass modern self-supervised learners, without compromising generative capability? This work addresses these questions by introducing self-conditioning, a straightforward yet effective mechanism that internally leverages the rich semantics inherent in denoising network to guide its own decoding layers, forming a tighter bottleneck that condenses high-level semantics to improve generation. Results are compelling: our method boosts both generation FID and recognition accuracy with 1% computational overhead and generalizes across diverse diffusion architectures. Crucially, self-conditioning facilitates an effective integration of discriminative techniques, such as contrastive self-distillation, directly into diffusion models without sacrificing generation quality. Extensive experiments on pixel-space and latent-space datasets show that in linear evaluations, our enhanced diffusion models, particularly UViT and DiT, serve as strong representation learners, surpassing various self-supervised models.
SeriesBench: A Benchmark for Narrative-Driven Drama Series Understanding
Apr 30, 2025



With the rapid development of Multi-modal Large Language Models (MLLMs), an increasing number of benchmarks have been established to evaluate the video understanding capabilities of these models. However, these benchmarks focus on \textbf{standalone} videos and mainly assess ``visual elements'' like human actions and object states. In reality, contemporary videos often encompass complex and continuous narratives, typically presented as a \textbf{series}. To address this challenge, we propose \textbf{SeriesBench}, a benchmark consisting of 105 carefully curated narrative-driven series, covering 28 specialized tasks that require deep narrative understanding. Specifically, we first select a diverse set of drama series spanning various genres. Then, we introduce a novel long-span narrative annotation method, combined with a full-information transformation approach to convert manual annotations into diverse task formats. To further enhance model capacity for detailed analysis of plot structures and character relationships within series, we propose a novel narrative reasoning framework, \textbf{PC-DCoT}. Extensive results on \textbf{SeriesBench} indicate that existing MLLMs still face significant challenges in understanding narrative-driven series, while \textbf{PC-DCoT} enables these MLLMs to achieve performance improvements. Overall, our \textbf{SeriesBench} and \textbf{PC-DCoT} highlight the critical necessity of advancing model capabilities to understand narrative-driven series, guiding the future development of MLLMs. SeriesBench is publicly available at https://github.com/zackhxn/SeriesBench-CVPR2025.
SkeletonX: Data-Efficient Skeleton-based Action Recognition via Cross-sample Feature Aggregation
Apr 16, 2025While current skeleton action recognition models demonstrate impressive performance on large-scale datasets, their adaptation to new application scenarios remains challenging. These challenges are particularly pronounced when facing new action categories, diverse performers, and varied skeleton layouts, leading to significant performance degeneration. Additionally, the high cost and difficulty of collecting skeleton data make large-scale data collection impractical. This paper studies one-shot and limited-scale learning settings to enable efficient adaptation with minimal data. Existing approaches often overlook the rich mutual information between labeled samples, resulting in sub-optimal performance in low-data scenarios. To boost the utility of labeled data, we identify the variability among performers and the commonality within each action as two key attributes. We present SkeletonX, a lightweight training pipeline that integrates seamlessly with existing GCN-based skeleton action recognizers, promoting effective training under limited labeled data. First, we propose a tailored sample pair construction strategy on two key attributes to form and aggregate sample pairs. Next, we develop a concise and effective feature aggregation module to process these pairs. Extensive experiments are conducted on NTU RGB+D, NTU RGB+D 120, and PKU-MMD with various GCN backbones, demonstrating that the pipeline effectively improves performance when trained from scratch with limited data. Moreover, it surpasses previous state-of-the-art methods in the one-shot setting, with only 1/10 of the parameters and much fewer FLOPs. The code and data are available at: https://github.com/zzysteve/SkeletonX
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025



Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
APHQ-ViT: Post-Training Quantization with Average Perturbation Hessian Based Reconstruction for Vision Transformers
Apr 03, 2025



Vision Transformers (ViTs) have become one of the most commonly used backbones for vision tasks. Despite their remarkable performance, they often suffer significant accuracy drops when quantized for practical deployment, particularly by post-training quantization (PTQ) under ultra-low bits. Recently, reconstruction-based PTQ methods have shown promising performance in quantizing Convolutional Neural Networks (CNNs). However, they fail when applied to ViTs, primarily due to the inaccurate estimation of output importance and the substantial accuracy degradation in quantizing post-GELU activations. To address these issues, we propose \textbf{APHQ-ViT}, a novel PTQ approach based on importance estimation with Average Perturbation Hessian (APH). Specifically, we first thoroughly analyze the current approximation approaches with Hessian loss, and propose an improved average perturbation Hessian loss. To deal with the quantization of the post-GELU activations, we design an MLP Reconstruction (MR) method by replacing the GELU function in MLP with ReLU and reconstructing it by the APH loss on a small unlabeled calibration set. Extensive experiments demonstrate that APHQ-ViT using linear quantizers outperforms existing PTQ methods by substantial margins in 3-bit and 4-bit across different vision tasks. The source code is available at https://github.com/GoatWu/APHQ-ViT.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025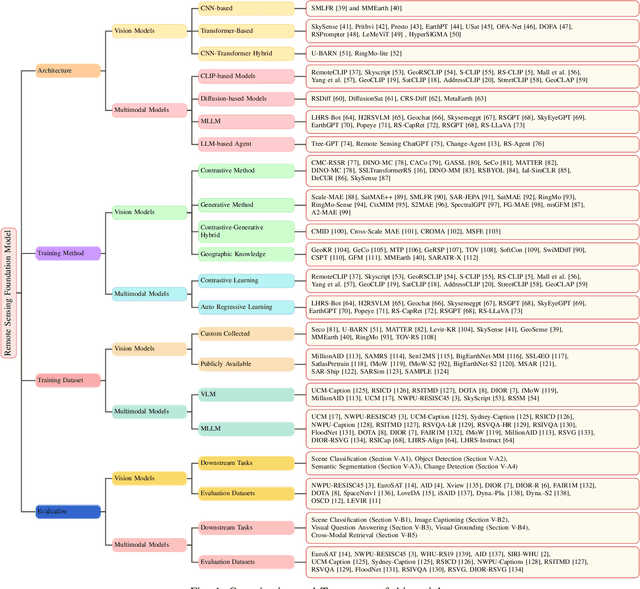
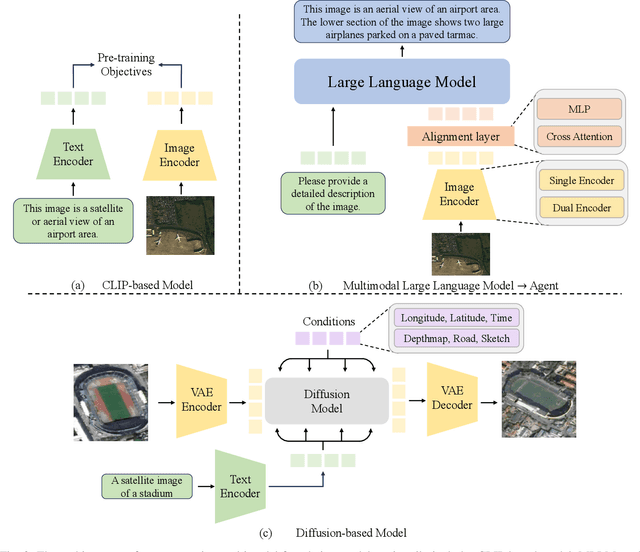

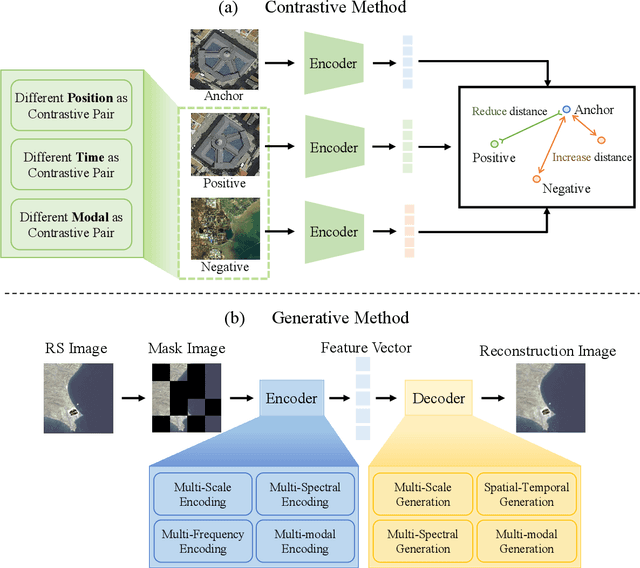
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
Mar 25, 2025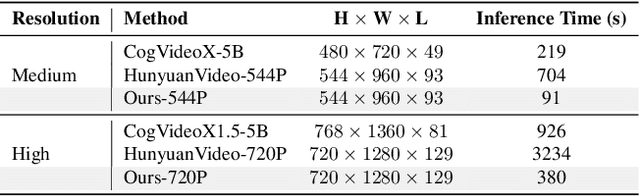
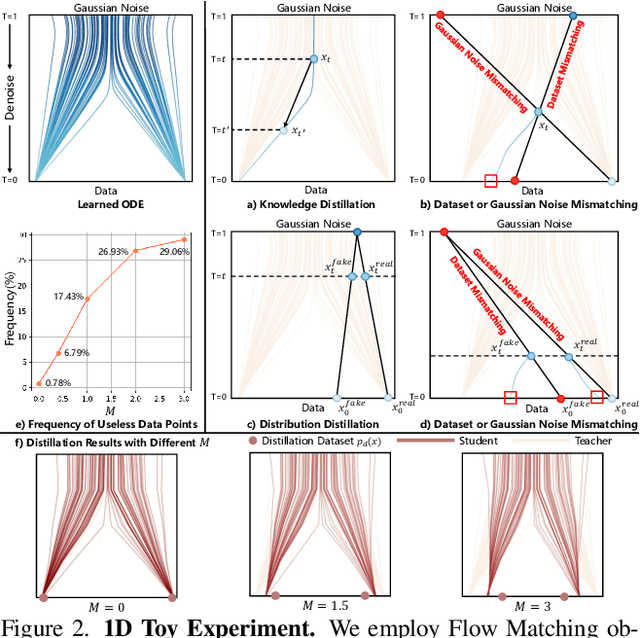

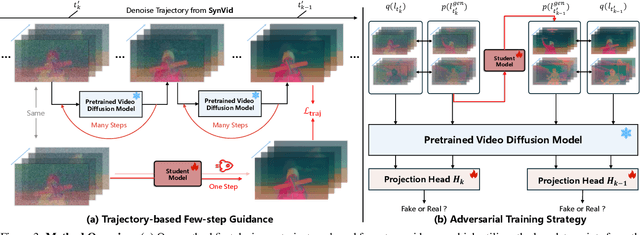
Diffusion models have achieved remarkable progress in the field of video generation. However, their iterative denoising nature requires a large number of inference steps to generate a video, which is slow and computationally expensive. In this paper, we begin with a detailed analysis of the challenges present in existing diffusion distillation methods and propose a novel efficient method, namely AccVideo, to reduce the inference steps for accelerating video diffusion models with synthetic dataset. We leverage the pretrained video diffusion model to generate multiple valid denoising trajectories as our synthetic dataset, which eliminates the use of useless data points during distillation. Based on the synthetic dataset, we design a trajectory-based few-step guidance that utilizes key data points from the denoising trajectories to learn the noise-to-video mapping, enabling video generation in fewer steps. Furthermore, since the synthetic dataset captures the data distribution at each diffusion timestep, we introduce an adversarial training strategy to align the output distribution of the student model with that of our synthetic dataset, thereby enhancing the video quality. Extensive experiments demonstrate that our model achieves 8.5x improvements in generation speed compared to the teacher model while maintaining comparable performance. Compared to previous accelerating methods, our approach is capable of generating videos with higher quality and resolution, i.e., 5-seconds, 720x1280, 24fps.
Generalizable AI-Generated Image Detection Based on Fractal Self-Similarity in the Spectrum
Mar 11, 2025



The generalization performance of AI-generated image detection remains a critical challenge. Although most existing methods perform well in detecting images from generative models included in the training set, their accuracy drops significantly when faced with images from unseen generators. To address this limitation, we propose a novel detection method based on the fractal self-similarity of the spectrum, a common feature among images generated by different models. Specifically, we demonstrate that AI-generated images exhibit fractal-like spectral growth through periodic extension and low-pass filtering. This observation motivates us to exploit the similarity among different fractal branches of the spectrum. Instead of directly analyzing the spectrum, our method mitigates the impact of varying spectral characteristics across different generators, improving detection performance for images from unseen models. Experiments on a public benchmark demonstrated the generalized detection performance across both GANs and diffusion models.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.