 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoDiffusion: A Generalizable Multi-Task Diffusion Foundation Model for Musculoskeletal MRI Interpretation
Feb 24, 2026Musculoskeletal disorders represent a significant global health burden and are a leading cause of disability worldwide. While MRI is essential for accurate diagnosis, its interpretation remains exceptionally challenging. Radiologists must identify multiple potential abnormalities within complex anatomical structures across different imaging planes, a process that requires significant expertise and is prone to variability. We developed OrthoDiffusion, a unified diffusion-based foundation model designed for multi-task musculoskeletal MRI interpretation. The framework utilizes three orientation-specific 3D diffusion models, pre-trained in a self-supervised manner on 15,948 unlabeled knee MRI scans, to learn robust anatomical features from sagittal, coronal, and axial views. These view-specific representations are integrated to support diverse clinical tasks, including anatomical segmentation and multi-label diagnosis. Our evaluation demonstrates that OrthoDiffusion achieves excellent performance in the segmentation of 11 knee structures and the detection of 8 knee abnormalities. The model exhibited remarkable robustness across different clinical centers and MRI field strengths, consistently outperforming traditional supervised models. Notably, in settings where labeled data was scarce, OrthoDiffusion maintained high diagnostic precision using only 10\% of training labels. Furthermore, the anatomical representations learned from knee imaging proved highly transferable to other joints, achieving strong diagnostic performance across 11 diseases of the ankle and shoulder. These findings suggest that diffusion-based foundation models can serve as a unified platform for multi-disease diagnosis and anatomical segmentation, potentially improving the efficiency and accuracy of musculoskeletal MRI interpretation in real-world clinical workflows.
DDAE++: Enhancing Diffusion Models Towards Unified Generative and Discriminative Learning
May 16, 2025While diffusion models have gained prominence in image synthesis, their generative pre-training has been shown to yield discriminative representations, paving the way towards unified visual generation and understanding. However, two key questions remain: 1) Can these representations be leveraged to improve the training of diffusion models themselves, rather than solely benefiting downstream tasks? 2) Can the feature quality be enhanced to rival or even surpass modern self-supervised learners, without compromising generative capability? This work addresses these questions by introducing self-conditioning, a straightforward yet effective mechanism that internally leverages the rich semantics inherent in denoising network to guide its own decoding layers, forming a tighter bottleneck that condenses high-level semantics to improve generation. Results are compelling: our method boosts both generation FID and recognition accuracy with 1% computational overhead and generalizes across diverse diffusion architectures. Crucially, self-conditioning facilitates an effective integration of discriminative techniques, such as contrastive self-distillation, directly into diffusion models without sacrificing generation quality. Extensive experiments on pixel-space and latent-space datasets show that in linear evaluations, our enhanced diffusion models, particularly UViT and DiT, serve as strong representation learners, surpassing various self-supervised models.
Denoising Diffusion Autoencoders are Unified Self-supervised Learners
Mar 17, 2023



Inspired by recent advances in diffusion models, which are reminiscent of denoising autoencoders, we investigate whether they can acquire discriminative representations for classification via generative pre-training. This paper shows that the networks in diffusion models, namely denoising diffusion autoencoders (DDAE), are unified self-supervised learners: by pre-training on unconditional image generation, DDAE has already learned strongly linear-separable representations at its intermediate layers without auxiliary encoders, thus making diffusion pre-training emerge as a general approach for self-supervised generative and discriminative learning. To verify this, we perform linear probe and fine-tuning evaluations on multi-class datasets. Our diffusion-based approach achieves 95.9% and 50.0% linear probe accuracies on CIFAR-10 and Tiny-ImageNet, respectively, and is comparable to masked autoencoders and contrastive learning for the first time. Additionally, transfer learning from ImageNet confirms DDAE's suitability for latent-space Vision Transformers, suggesting the potential for scaling DDAEs as unified foundation models.
AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
Jan 31, 2018
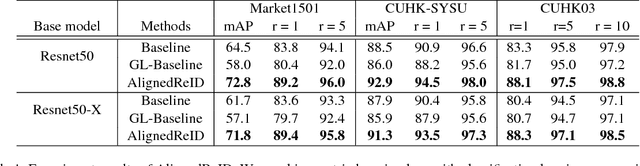
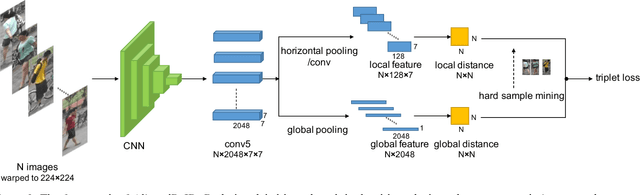
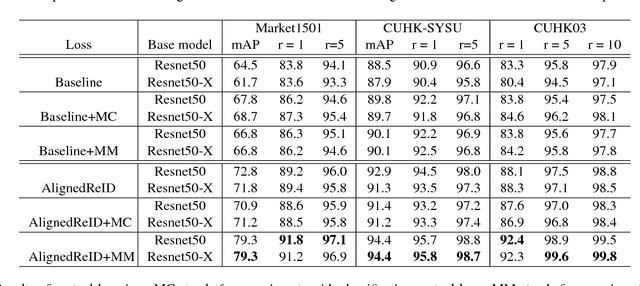
In this paper, we propose a novel method called AlignedReID that extracts a global feature which is jointly learned with local features. Global feature learning benefits greatly from local feature learning, which performs an alignment/matching by calculating the shortest path between two sets of local features, without requiring extra supervision. After the joint learning, we only keep the global feature to compute the similarities between images. Our method achieves rank-1 accuracy of 94.4% on Market1501 and 97.8% on CUHK03, outperforming state-of-the-art methods by a large margin. We also evaluate human-level performance and demonstrate that our method is the first to surpass human-level performance on Market1501 and CUHK03, two widely used Person ReID datasets.