 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationBooth: Towards Relation-Aware Customized Object Generation
Oct 30, 2024
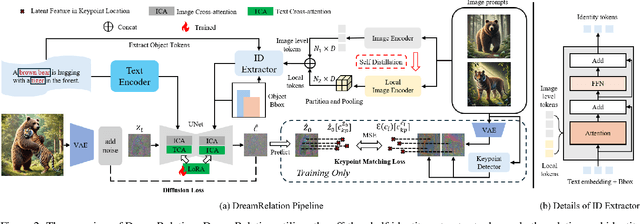

Customized image generation is crucial for delivering personalized content based on user-provided image prompts, aligning large-scale text-to-image diffusion models with individual needs. However, existing models often overlook the relationships between customized objects in generated images. Instead, this work addresses that gap by focusing on relation-aware customized image generation, which aims to preserve the identities from image prompts while maintaining the predicate relations described in text prompts. Specifically, we introduce RelationBooth, a framework that disentangles identity and relation learning through a well-curated dataset. Our training data consists of relation-specific images, independent object images containing identity information, and text prompts to guide relation generation. Then, we propose two key modules to tackle the two main challenges: generating accurate and natural relations, especially when significant pose adjustments are required, and avoiding object confusion in cases of overlap. First, we introduce a keypoint matching loss that effectively guides the model in adjusting object poses closely tied to their relationships. Second, we incorporate local features from the image prompts to better distinguish between objects, preventing confusion in overlapping cases. Extensive results on three benchmarks demonstrate the superiority of RelationBooth in generating precise relations while preserving object identities across a diverse set of objects and relations. The source code and trained models will be made available to the public.
MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning
Oct 15, 2024



Parameter-efficient fine-tuning (PEFT) has been widely employed for domain adaptation, with LoRA being one of the most prominent methods due to its simplicity and effectiveness. However, in multi-task learning (MTL) scenarios, LoRA tends to obscure the distinction between tasks by projecting sparse high-dimensional features from different tasks into the same dense low-dimensional intrinsic space. This leads to task interference and suboptimal performance for LoRA and its variants. To tackle this challenge, we propose MTL-LoRA, which retains the advantages of low-rank adaptation while significantly enhancing multi-task learning capabilities. MTL-LoRA augments LoRA by incorporating additional task-adaptive parameters that differentiate task-specific information and effectively capture shared knowledge across various tasks within low-dimensional spaces. This approach enables large language models (LLMs) pre-trained on general corpus to adapt to different target task domains with a limited number of trainable parameters. Comprehensive experimental results, including evaluations on public academic benchmarks for natural language understanding, commonsense reasoning, and image-text understanding, as well as real-world industrial text Ads relevance datasets, demonstrate that MTL-LoRA outperforms LoRA and its various variants with comparable or even fewer learnable parameters in multitask learning.
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
You Can't Ignore Either: Unifying Structure and Feature Denoising for Robust Graph Learning
Aug 01, 2024Recent research on the robustness of Graph Neural Networks (GNNs) under noises or attacks has attracted great attention due to its importance in real-world applications. Most previous methods explore a single noise source, recovering corrupt node embedding by reliable structures bias or developing structure learning with reliable node features. However, the noises and attacks may come from both structures and features in graphs, making the graph denoising a dilemma and challenging problem. In this paper, we develop a unified graph denoising (UGD) framework to unravel the deadlock between structure and feature denoising. Specifically, a high-order neighborhood proximity evaluation method is proposed to recognize noisy edges, considering features may be perturbed simultaneously. Moreover, we propose to refine noisy features with reconstruction based on a graph auto-encoder. An iterative updating algorithm is further designed to optimize the framework and acquire a clean graph, thus enabling robust graph learning for downstream tasks. Our UGD framework is self-supervised and can be easily implemented as a plug-and-play module. We carry out extensive experiments, which proves the effectiveness and advantages of our method. Code is avalaible at https://github.com/YoungTimmy/UGD.
LLAVADI: What Matters For Multimodal Large Language Models Distillation
Jul 28, 2024



The recent surge in Multimodal Large Language Models (MLLMs) has showcased their remarkable potential for achieving generalized intelligence by integrating visual understanding into Large Language Models.Nevertheless, the sheer model size of MLLMs leads to substantial memory and computational demands that hinder their widespread deployment. In this work, we do not propose a new efficient model structure or train small-scale MLLMs from scratch. Instead, we focus on what matters for training small-scale MLLMs through knowledge distillation, which is the first step from the multimodal distillation perspective. Our extensive studies involve training strategies, model choices, and distillation algorithms in the knowledge distillation process. These results show that joint alignment for both tokens and logit alignment plays critical roles in teacher-student frameworks. In addition, we draw a series of intriguing observations from this study. By evaluating different benchmarks and proper strategy, even a 2.7B small-scale model can perform on par with larger models with 7B or 13B parameters. Our code and models will be publicly available for further research.
MotionBooth: Motion-Aware Customized Text-to-Video Generation
Jun 25, 2024In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Our project page is at https://jianzongwu.github.io/projects/motionbooth
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning
Jun 17, 2024



Graph-based fraud detection has widespread application in modern industry scenarios, such as spam review and malicious account detection. While considerable efforts have been devoted to designing adequate fraud detectors, the interpretability of their results has often been overlooked. Previous works have attempted to generate explanations for specific instances using post-hoc explaining methods such as a GNNExplainer. However, post-hoc explanations can not facilitate the model predictions and the computational cost of these methods cannot meet practical requirements, thus limiting their application in real-world scenarios. To address these issues, we propose SEFraud, a novel graph-based self-explainable fraud detection framework that simultaneously tackles fraud detection and result in interpretability. Concretely, SEFraud first leverages customized heterogeneous graph transformer networks with learnable feature masks and edge masks to learn expressive representations from the informative heterogeneously typed transactions. A new triplet loss is further designed to enhance the performance of mask learning. Empirical results on various datasets demonstrate the effectiveness of SEFraud as it shows considerable advantages in both the fraud detection performance and interpretability of prediction results. Moreover, SEFraud has been deployed and offers explainable fraud detection service for the largest bank in China, Industrial and Commercial Bank of China Limited (ICBC). Results collected from the production environment of ICBC show that SEFraud can provide accurate detection results and comprehensive explanations that align with the expert business understanding, confirming its efficiency and applicability in large-scale online services.
SemFlow: Binding Semantic Segmentation and Image Synthesis via Rectified Flow
May 30, 2024



Semantic segmentation and semantic image synthesis are two representative tasks in visual perception and generation. While existing methods consider them as two distinct tasks, we propose a unified diffusion-based framework (SemFlow) and model them as a pair of reverse problems. Specifically, motivated by rectified flow theory, we train an ordinary differential equation (ODE) model to transport between the distributions of real images and semantic masks. As the training object is symmetric, samples belonging to the two distributions, images and semantic masks, can be effortlessly transferred reversibly. For semantic segmentation, our approach solves the contradiction between the randomness of diffusion outputs and the uniqueness of segmentation results. For image synthesis, we propose a finite perturbation approach to enhance the diversity of generated results without changing the semantic categories. Experiments show that our SemFlow achieves competitive results on semantic segmentation and semantic image synthesis tasks. We hope this simple framework will motivate people to rethink the unification of low-level and high-level vision. Project page: https://github.com/wang-chaoyang/SemFlow.
VG4D: Vision-Language Model Goes 4D Video Recognition
Apr 17, 2024Understanding the real world through point cloud video is a crucial aspect of robotics and autonomous driving systems. However, prevailing methods for 4D point cloud recognition have limitations due to sensor resolution, which leads to a lack of detailed information. Recent advances have shown that Vision-Language Models (VLM) pre-trained on web-scale text-image datasets can learn fine-grained visual concepts that can be transferred to various downstream tasks. However, effectively integrating VLM into the domain of 4D point clouds remains an unresolved problem. In this work, we propose the Vision-Language Models Goes 4D (VG4D) framework to transfer VLM knowledge from visual-text pre-trained models to a 4D point cloud network. Our approach involves aligning the 4D encoder's representation with a VLM to learn a shared visual and text space from training on large-scale image-text pairs. By transferring the knowledge of the VLM to the 4D encoder and combining the VLM, our VG4D achieves improved recognition performance. To enhance the 4D encoder, we modernize the classic dynamic point cloud backbone and propose an improved version of PSTNet, im-PSTNet, which can efficiently model point cloud videos. Experiments demonstrate that our method achieves state-of-the-art performance for action recognition on both the NTU RGB+D 60 dataset and the NTU RGB+D 120 dataset. Code is available at \url{https://github.com/Shark0-0/VG4D}.
Explore In-Context Segmentation via Latent Diffusion Models
Mar 14, 2024In-context segmentation has drawn more attention with the introduction of vision foundation models. Most existing approaches adopt metric learning or masked image modeling to build the correlation between visual prompts and input image queries. In this work, we explore this problem from a new perspective, using one representative generation model, the latent diffusion model (LDM). We observe a task gap between generation and segmentation in diffusion models, but LDM is still an effective minimalist for in-context segmentation. In particular, we propose two meta-architectures and correspondingly design several output alignment and optimization strategies. We have conducted comprehensive ablation studies and empirically found that the segmentation quality counts on output alignment and in-context instructions. Moreover, we build a new and fair in-context segmentation benchmark that includes both image and video datasets. Experiments validate the efficiency of our approach, demonstrating comparable or even stronger results than previous specialist models or visual foundation models. Our study shows that LDMs can also achieve good enough results for challenging in-context segmentation tasks.