 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Video Object Detection with Spatial-Temporal Transformers
Paper and Code
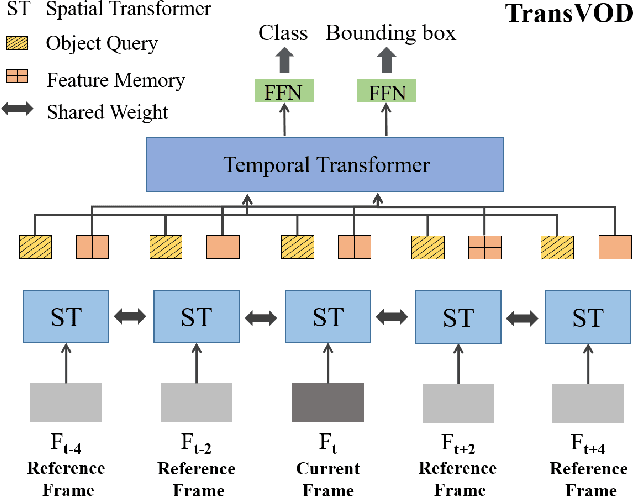
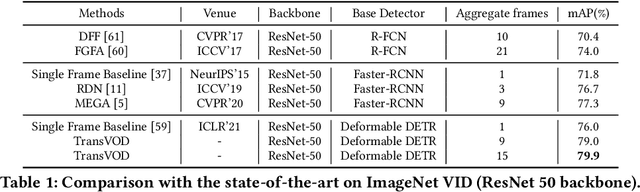
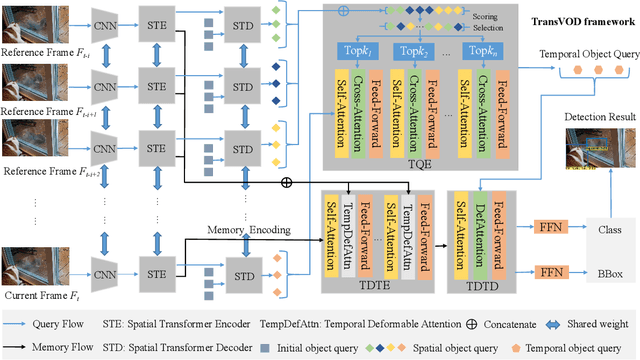
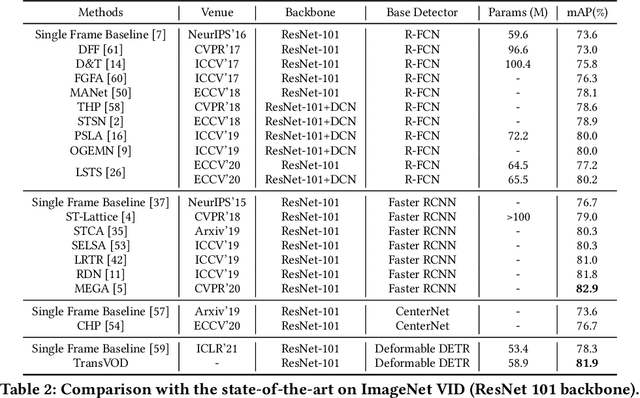
Recently, DETR and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, an end-to-end video object detection model based on a spatial-temporal Transformer architecture. The goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow, recurrent neural networks, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS or Tubelet rescoring, which keeps the pipeline simple and clean. In particular, we present temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal Transformer consists of three components: Temporal Deformable Transformer Encoder (TDTE) to encode the multiple frame spatial details, Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. TransVOD yields comparable results performance on the benchmark of ImageNet VID. We hope our TransVOD can provide a new perspective for video object detection. Code will be made publicly available at https://github.com/SJTU-LuHe/TransVOD.