 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Knowledge Distillation from Large Language Model: An Empirical Study in the Autonomous Driving Domain
Jul 17, 2023



Engineering knowledge-based (or expert) systems require extensive manual effort and domain knowledge. As Large Language Models (LLMs) are trained using an enormous amount of cross-domain knowledge, it becomes possible to automate such engineering processes. This paper presents an empirical automation and semi-automation framework for domain knowledge distillation using prompt engineering and the LLM ChatGPT. We assess the framework empirically in the autonomous driving domain and present our key observations. In our implementation, we construct the domain knowledge ontology by "chatting" with ChatGPT. The key finding is that while fully automated domain ontology construction is possible, human supervision and early intervention typically improve efficiency and output quality as they lessen the effects of response randomness and the butterfly effect. We, therefore, also develop a web-based distillation assistant enabling supervision and flexible intervention at runtime. We hope our findings and tools could inspire future research toward revolutionizing the engineering of knowledge-based systems across application domains.
Exploration on HuBERT with Multiple Resolutions
Jun 22, 2023



Hidden-unit BERT (HuBERT) is a widely-used self-supervised learning (SSL) model in speech processing. However, we argue that its fixed 20ms resolution for hidden representations would not be optimal for various speech-processing tasks since their attributes (e.g., speaker characteristics and semantics) are based on different time scales. To address this limitation, we propose utilizing HuBERT representations at multiple resolutions for downstream tasks. We explore two approaches, namely the parallel and hierarchical approaches, for integrating HuBERT features with different resolutions. Through experiments, we demonstrate that HuBERT with multiple resolutions outperforms the original model. This highlights the potential of utilizing multiple resolutions in SSL models like HuBERT to capture diverse information from speech signals.
Hybrid Transducer and Attention based Encoder-Decoder Modeling for Speech-to-Text Tasks
May 04, 2023



Transducer and Attention based Encoder-Decoder (AED) are two widely used frameworks for speech-to-text tasks. They are designed for different purposes and each has its own benefits and drawbacks for speech-to-text tasks. In order to leverage strengths of both modeling methods, we propose a solution by combining Transducer and Attention based Encoder-Decoder (TAED) for speech-to-text tasks. The new method leverages AED's strength in non-monotonic sequence to sequence learning while retaining Transducer's streaming property. In the proposed framework, Transducer and AED share the same speech encoder. The predictor in Transducer is replaced by the decoder in the AED model, and the outputs of the decoder are conditioned on the speech inputs instead of outputs from an unconditioned language model. The proposed solution ensures that the model is optimized by covering all possible read/write scenarios and creates a matched environment for streaming applications. We evaluate the proposed approach on the \textsc{MuST-C} dataset and the findings demonstrate that TAED performs significantly better than Transducer for offline automatic speech recognition (ASR) and speech-to-text translation (ST) tasks. In the streaming case, TAED outperforms Transducer in the ASR task and one ST direction while comparable results are achieved in another translation direction.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023



ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
Enhancing Speech-to-Speech Translation with Multiple TTS Targets
Apr 10, 2023



It has been known that direct speech-to-speech translation (S2ST) models usually suffer from the data scarcity issue because of the limited existing parallel materials for both source and target speech. Therefore to train a direct S2ST system, previous works usually utilize text-to-speech (TTS) systems to generate samples in the target language by augmenting the data from speech-to-text translation (S2TT). However, there is a limited investigation into how the synthesized target speech would affect the S2ST models. In this work, we analyze the effect of changing synthesized target speech for direct S2ST models. We find that simply combining the target speech from different TTS systems can potentially improve the S2ST performances. Following that, we also propose a multi-task framework that jointly optimizes the S2ST system with multiple targets from different TTS systems. Extensive experiments demonstrate that our proposed framework achieves consistent improvements (2.8 BLEU) over the baselines on the Fisher Spanish-English dataset.
FLYOVER: A Model-Driven Method to Generate Diverse Highway Interchanges for Autonomous Vehicle Testing
Jan 30, 2023



It has become a consensus that autonomous vehicles (AVs) will first be widely deployed on highways. However, the complexity of highway interchanges becomes the bottleneck for deploying AVs. An AV should be sufficiently tested under different highway interchanges, which is still challenging due to the lack of available datasets containing diverse highway interchanges. In this paper, we propose a model-driven method, FLYOVER, to generate a dataset consisting of diverse interchanges with measurable diversity coverage. First, FLYOVER proposes a labeled digraph to model the topology of an interchange. Second, FLYOVER takes real-world interchanges as input to guarantee topology practicality and extracts different topology equivalence classes by classifying the corresponding topology models. Third, for each topology class, FLYOVER identifies the corresponding geometrical features for the ramps and generates concrete interchanges using k-way combinatorial coverage and differential evolution. To illustrate the diversity and applicability of the generated interchange dataset, we test the built-in traffic flow control algorithm in SUMO and the fuel-optimization trajectory tracking algorithm deployed to Alibaba's autonomous trucks on the dataset. The results show that except for the geometrical difference, the interchanges are diverse in throughput and fuel consumption under the traffic flow control and trajectory tracking algorithms, respectively.
UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Dec 15, 2022Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
Improving Speech-to-Speech Translation Through Unlabeled Text
Oct 26, 2022Direct speech-to-speech translation (S2ST) is among the most challenging problems in the translation paradigm due to the significant scarcity of S2ST data. While effort has been made to increase the data size from unlabeled speech by cascading pretrained speech recognition (ASR), machine translation (MT) and text-to-speech (TTS) models; unlabeled text has remained relatively under-utilized to improve S2ST. We propose an effective way to utilize the massive existing unlabeled text from different languages to create a large amount of S2ST data to improve S2ST performance by applying various acoustic effects to the generated synthetic data. Empirically our method outperforms the state of the art in Spanish-English translation by up to 2 BLEU. Significant gains by the proposed method are demonstrated in extremely low-resource settings for both Spanish-English and Russian-English translations.
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022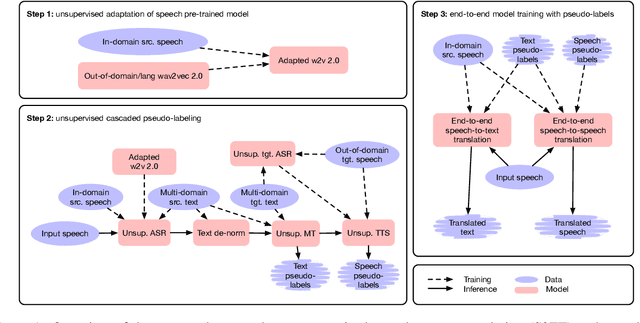
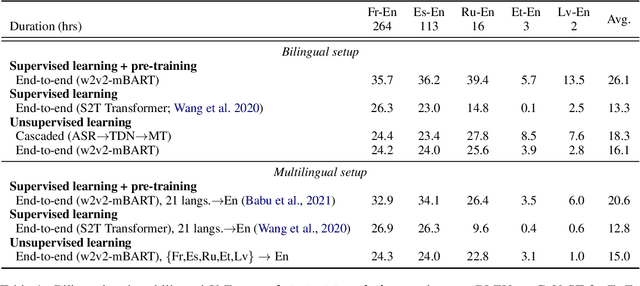
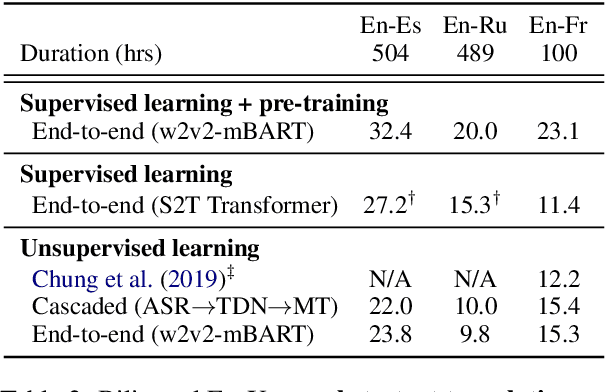
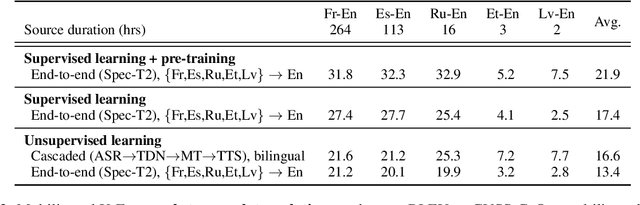
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022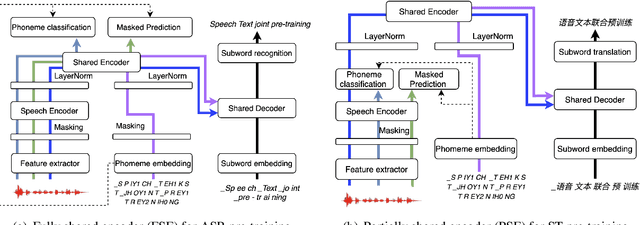

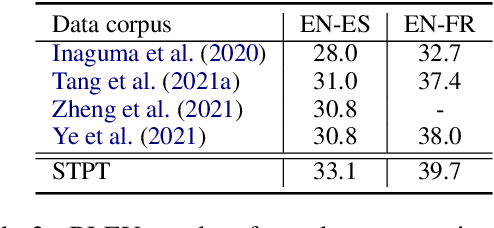
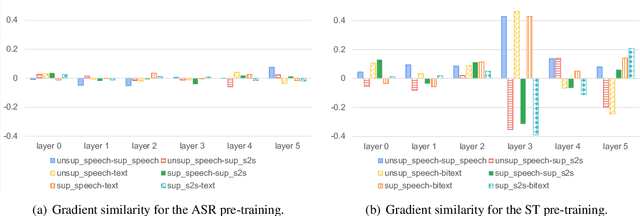
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.