 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Feb 09, 2026Despite the growing video understanding capabilities of recent Multimodal Large Language Models (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge, rather than their ability to learn and adapt from dynamic, novel contexts from few examples. To bridge this gap, we present Demo-driven Video In-Context Learning, a novel task focused on learning from in-context demonstrations to answer questions about the target videos. Alongside this, we propose Demo-ICL-Bench, a challenging benchmark designed to evaluate demo-driven video in-context learning capabilities. Demo-ICL-Bench is constructed from 1200 instructional YouTube videos with associated questions, from which two types of demonstrations are derived: (i) summarizing video subtitles for text demonstration; and (ii) corresponding instructional videos as video demonstrations. To effectively tackle this new challenge, we develop Demo-ICL, an MLLM with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization, jointly enhancing the model's ability to learn from in-context examples. Extensive experiments with state-of-the-art MLLMs confirm the difficulty of Demo-ICL-Bench, demonstrate the effectiveness of Demo-ICL, and thereby unveil future research directions.
Think Visually, Reason Textually: Vision-Language Synergy in ARC
Nov 19, 2025



Abstract reasoning from minimal examples remains a core unsolved problem for frontier foundation models such as GPT-5 and Grok 4. These models still fail to infer structured transformation rules from a handful of examples, which is a key hallmark of human intelligence. The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks. Most existing methods treat ARC-AGI as a purely textual reasoning task, overlooking the fact that humans rely heavily on visual abstraction when solving such puzzles. However, our pilot experiments reveal a paradox: naively rendering ARC-AGI grids as images degrades performance due to imprecise rule execution. This leads to our central hypothesis that vision and language possess complementary strengths across distinct reasoning stages: vision supports global pattern abstraction and verification, whereas language specializes in symbolic rule formulation and precise execution. Building on this insight, we introduce two synergistic strategies: (1) Vision-Language Synergy Reasoning (VLSR), which decomposes ARC-AGI into modality-aligned subtasks; and (2) Modality-Switch Self-Correction (MSSC), which leverages vision to verify text-based reasoning for intrinsic error correction. Extensive experiments demonstrate that our approach yields up to a 4.33% improvement over text-only baselines across diverse flagship models and multiple ARC-AGI tasks. Our findings suggest that unifying visual abstraction with linguistic reasoning is a crucial step toward achieving generalizable, human-like intelligence in future foundation models. Source code will be released soon.
Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Oct 31, 2025Spatial understanding remains a weakness of Large Vision-Language Models (LVLMs). Existing supervised fine-tuning (SFT) and recent reinforcement learning with verifiable rewards (RLVR) pipelines depend on costly supervision, specialized tools, or constrained environments that limit scale. We introduce Spatial-SSRL, a self-supervised RL paradigm that derives verifiable signals directly from ordinary RGB or RGB-D images. Spatial-SSRL automatically formulates five pretext tasks that capture 2D and 3D spatial structure: shuffled patch reordering, flipped patch recognition, cropped patch inpainting, regional depth ordering, and relative 3D position prediction. These tasks provide ground-truth answers that are easy to verify and require no human or LVLM annotation. Training on our tasks substantially improves spatial reasoning while preserving general visual capabilities. On seven spatial understanding benchmarks in both image and video settings, Spatial-SSRL delivers average accuracy gains of 4.63% (3B) and 3.89% (7B) over the Qwen2.5-VL baselines. Our results show that simple, intrinsic supervision enables RLVR at scale and provides a practical route to stronger spatial intelligence in LVLMs.
CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
Sep 26, 2025Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.
SPARK: Synergistic Policy And Reward Co-Evolving Framework
Sep 26, 2025



Recent Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) increasingly use Reinforcement Learning (RL) for post-pretraining, such as RL with Verifiable Rewards (RLVR) for objective tasks and RL from Human Feedback (RLHF) for subjective tasks. However, RLHF incurs high costs and potential reward-policy mismatch due to reliance on human preferences, while RLVR still wastes supervision by discarding rollouts and correctness signals after each update. To address these challenges, we introduce the Synergistic Policy And Reward Co-Evolving Framework (SPARK), an efficient, on-policy, and stable method that builds on RLVR. Instead of discarding rollouts and correctness data, SPARK recycles this valuable information to simultaneously train the model itself as a generative reward model. This auxiliary training uses a mix of objectives, such as pointwise reward score, pairwise comparison, and evaluation conditioned on further-reflection responses, to teach the model to evaluate and improve its own responses. Our process eliminates the need for a separate reward model and costly human preference data. SPARK creates a positive co-evolving feedback loop: improved reward accuracy yields better policy gradients, which in turn produce higher-quality rollouts that further refine the reward model. Our unified framework supports test-time scaling via self-reflection without external reward models and their associated costs. We show that SPARK achieves significant performance gains on multiple LLM and LVLM models and multiple reasoning, reward models, and general benchmarks. For example, SPARK-VL-7B achieves an average 9.7% gain on 7 reasoning benchmarks, 12.1% on 2 reward benchmarks, and 1.5% on 8 general benchmarks over the baselines, demonstrating robustness and broad generalization.
CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
Aug 27, 2025Autonomous agents for Graphical User Interfaces (GUIs) face significant challenges in specialized domains such as scientific computing, where both long-horizon planning and precise execution are required. Existing approaches suffer from a trade-off: generalist agents excel at planning but perform poorly in execution, while specialized agents demonstrate the opposite weakness. Recent compositional frameworks attempt to bridge this gap by combining a planner and an actor, but they are typically static and non-trainable, which prevents adaptation from experience. This is a critical limitation given the scarcity of high-quality data in scientific domains. To address these limitations, we introduce CODA, a novel and trainable compositional framework that integrates a generalist planner (Cerebrum) with a specialist executor (Cerebellum), trained via a dedicated two-stage pipeline. In the first stage, Specialization, we apply a decoupled GRPO approach to train an expert planner for each scientific application individually, bootstrapping from a small set of task trajectories. In the second stage, Generalization, we aggregate all successful trajectories from the specialized experts to build a consolidated dataset, which is then used for supervised fine-tuning of the final planner. This equips CODA with both robust execution and cross-domain generalization. Evaluated on four challenging applications from the ScienceBoard benchmark, CODA significantly outperforms baselines and establishes a new state of the art among open-source models.
SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience
Aug 06, 2025Repurposing large vision-language models (LVLMs) as computer use agents (CUAs) has led to substantial breakthroughs, primarily driven by human-labeled data. However, these models often struggle with novel and specialized software, particularly in scenarios lacking human annotations. To address this challenge, we propose SEAgent, an agentic self-evolving framework enabling CUAs to autonomously evolve through interactions with unfamiliar software. Specifically, SEAgent empowers computer-use agents to autonomously master novel software environments via experiential learning, where agents explore new software, learn through iterative trial-and-error, and progressively tackle auto-generated tasks organized from simple to complex. To achieve this goal, we design a World State Model for step-wise trajectory assessment, along with a Curriculum Generator that generates increasingly diverse and challenging tasks. The agent's policy is updated through experiential learning, comprised of adversarial imitation of failure actions and Group Relative Policy Optimization (GRPO) on successful ones. Furthermore, we introduce a specialist-to-generalist training strategy that integrates individual experiential insights from specialist agents, facilitating the development of a stronger generalist CUA capable of continuous autonomous evolution. This unified agent ultimately achieves performance surpassing ensembles of individual specialist agents on their specialized software. We validate the effectiveness of SEAgent across five novel software environments within OS-World. Our approach achieves a significant improvement of 23.2% in success rate, from 11.3% to 34.5%, over a competitive open-source CUA, i.e., UI-TARS.
Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
Aug 01, 2025



Diffusion Large Language Models (DLLMs) are emerging as a powerful alternative to the dominant Autoregressive Large Language Models, offering efficient parallel generation and capable global context modeling. However, the practical application of DLLMs is hindered by a critical architectural constraint: the need for a statically predefined generation length. This static length allocation leads to a problematic trade-off: insufficient lengths cripple performance on complex tasks, while excessive lengths incur significant computational overhead and sometimes result in performance degradation. While the inference framework is rigid, we observe that the model itself possesses internal signals that correlate with the optimal response length for a given task. To bridge this gap, we leverage these latent signals and introduce DAEDAL, a novel training-free denoising strategy that enables Dynamic Adaptive Length Expansion for Diffusion Large Language Models. DAEDAL operates in two phases: 1) Before the denoising process, DAEDAL starts from a short initial length and iteratively expands it to a coarse task-appropriate length, guided by a sequence completion metric. 2) During the denoising process, DAEDAL dynamically intervenes by pinpointing and expanding insufficient generation regions through mask token insertion, ensuring the final output is fully developed. Extensive experiments on DLLMs demonstrate that DAEDAL achieves performance comparable, and in some cases superior, to meticulously tuned fixed-length baselines, while simultaneously enhancing computational efficiency by achieving a higher effective token ratio. By resolving the static length constraint, DAEDAL unlocks new potential for DLLMs, bridging a critical gap with their Autoregressive counterparts and paving the way for more efficient and capable generation.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
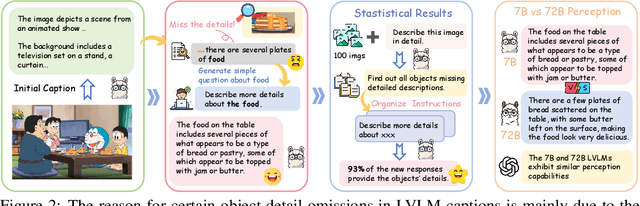

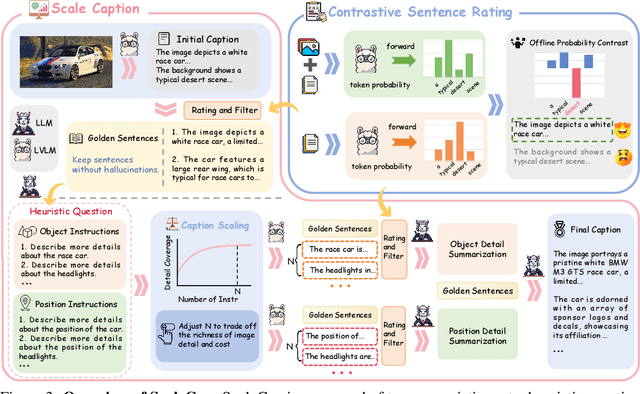
This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.