 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLabel: Three-stage Active Learning for LLM-based Entity Recognition using Demonstration Retrieval
Sep 09, 2025Many contemporary data-driven research efforts in the natural sciences, such as chemistry and materials science, require large-scale, high-performance entity recognition from scientific datasets. Large language models (LLMs) have increasingly been adopted to solve the entity recognition task, with the same trend being observed on all-spectrum NLP tasks. The prevailing entity recognition LLMs rely on fine-tuned technology, yet the fine-tuning process often incurs significant cost. To achieve a best performance-cost trade-off, we propose ALLabel, a three-stage framework designed to select the most informative and representative samples in preparing the demonstrations for LLM modeling. The annotated examples are used to construct a ground-truth retrieval corpus for LLM in-context learning. By sequentially employing three distinct active learning strategies, ALLabel consistently outperforms all baselines under the same annotation budget across three specialized domain datasets. Experimental results also demonstrate that selectively annotating only 5\%-10\% of the dataset with ALLabel can achieve performance comparable to the method annotating the entire dataset. Further analyses and ablation studies verify the effectiveness and generalizability of our proposal.
Breaking Down and Building Up: Mixture of Skill-Based Vision-and-Language Navigation Agents
Aug 11, 2025Vision-and-Language Navigation (VLN) poses significant challenges in enabling agents to interpret natural language instructions and navigate complex 3D environments. While recent progress has been driven by large-scale pre-training and data augmentation, current methods still struggle to generalize to unseen scenarios, particularly when complex spatial and temporal reasoning is required. In this work, we propose SkillNav, a modular framework that introduces structured, skill-based reasoning into Transformer-based VLN agents. Our method decomposes navigation into a set of interpretable atomic skills (e.g., Vertical Movement, Area and Region Identification, Stop and Pause), each handled by a specialized agent. We then introduce a novel zero-shot Vision-Language Model (VLM)-based router, which dynamically selects the most suitable agent at each time step by aligning sub-goals with visual observations and historical actions. SkillNav achieves a new state-of-the-art performance on the R2R benchmark and demonstrates strong generalization to the GSA-R2R benchmark that includes novel instruction styles and unseen environments.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
T-Detect: Tail-Aware Statistical Normalization for Robust Detection of Adversarial Machine-Generated Text
Jul 31, 2025



The proliferation of sophisticated text generation models necessitates the development of robust detection methods capable of identifying machine-generated content, particularly text designed to evade detection through adversarial perturbations. Existing zero-shot detectors often rely on statistical measures that implicitly assume Gaussian distributions, a premise that falters when confronted with the heavy-tailed statistical artifacts characteristic of adversarial or non-native English texts. This paper introduces T-Detect, a novel detection method that fundamentally redesigns the statistical core of curvature-based detectors. Our primary innovation is the replacement of standard Gaussian normalization with a heavy-tailed discrepancy score derived from the Student's t-distribution. This approach is theoretically grounded in the empirical observation that adversarial texts exhibit significant leptokurtosis, rendering traditional statistical assumptions inadequate. T-Detect computes a detection score by normalizing the log-likelihood of a passage against the expected moments of a t-distribution, providing superior resilience to statistical outliers. We validate our approach on the challenging RAID benchmark for adversarial text and the comprehensive HART dataset. Experiments show that T-Detect provides a consistent performance uplift over strong baselines, improving AUROC by up to 3.9\% in targeted domains. When integrated into a two-dimensional detection framework (CT), our method achieves state-of-the-art performance, with an AUROC of 0.926 on the Books domain of RAID. Our contributions are a new, theoretically-justified statistical foundation for text detection, an ablation-validated method that demonstrates superior robustness, and a comprehensive analysis of its performance under adversarial conditions. Ours code are released at https://github.com/ResearAI/t-detect.
A Dual-Feature Extractor Framework for Accurate Back Depth and Spine Morphology Estimation from Monocular RGB Images
Jul 30, 2025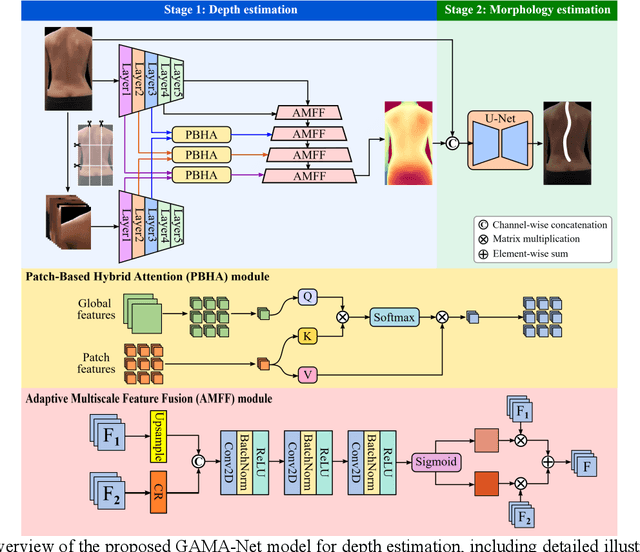

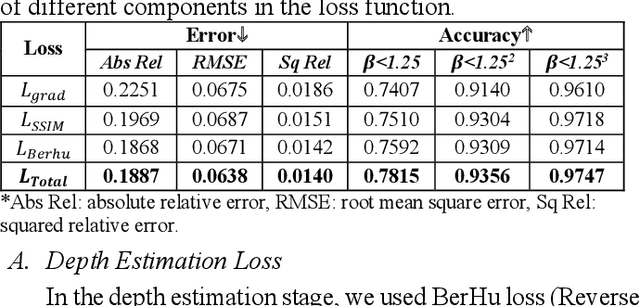

Scoliosis is a prevalent condition that impacts both physical health and appearance, with adolescent idiopathic scoliosis (AIS) being the most common form. Currently, the main AIS assessment tool, X-rays, poses significant limitations, including radiation exposure and limited accessibility in poor and remote areas. To address this problem, the current solutions are using RGB images to analyze spine morphology. However, RGB images are highly susceptible to environmental factors, such as lighting conditions, compromising model stability and generalizability. Therefore, in this study, we propose a novel pipeline to accurately estimate the depth information of the unclothed back, compensating for the limitations of 2D information, and then estimate spine morphology by integrating both depth and surface information. To capture the subtle depth variations of the back surface with precision, we design an adaptive multiscale feature learning network named Grid-Aware Multiscale Adaptive Network (GAMA-Net). This model uses dual encoders to extract both patch-level and global features, which are then interacted by the Patch-Based Hybrid Attention (PBHA) module. The Adaptive Multiscale Feature Fusion (AMFF) module is used to dynamically fuse information in the decoder. As a result, our depth estimation model achieves remarkable accuracy across three different evaluation metrics, with scores of nearly 78.2%, 93.6%, and 97.5%, respectively. To further validate the effectiveness of the predicted depth, we integrate both surface and depth information for spine morphology estimation. This integrated approach enhances the accuracy of spine curve generation, achieving an impressive performance of up to 97%.
Noise Analysis and Hierarchical Adaptive Body State Estimator For Biped Robot Walking With ESVC Foot
Jun 10, 2025



The ESVC(Ellipse-based Segmental Varying Curvature) foot, a robot foot design inspired by the rollover shape of the human foot, significantly enhances the energy efficiency of the robot walking gait. However, due to the tilt of the supporting leg, the error of the contact model are amplified, making robot state estimation more challenging. Therefore, this paper focuses on the noise analysis and state estimation for robot walking with the ESVC foot. First, through physical robot experiments, we investigate the effect of the ESVC foot on robot measurement noise and process noise. and a noise-time regression model using sliding window strategy is developed. Then, a hierarchical adaptive state estimator for biped robots with the ESVC foot is proposed. The state estimator consists of two stages: pre-estimation and post-estimation. In the pre-estimation stage, a data fusion-based estimation is employed to process the sensory data. During post-estimation, the acceleration of center of mass is first estimated, and then the noise covariance matrices are adjusted based on the regression model. Following that, an EKF(Extended Kalman Filter) based approach is applied to estimate the centroid state during robot walking. Physical experiments demonstrate that the proposed adaptive state estimator for biped robot walking with the ESVC foot not only provides higher precision than both EKF and Adaptive EKF, but also converges faster under varying noise conditions.
Model Analysis And Design Of Ellipse Based Segmented Varying Curved Foot For Biped Robot Walking
Jun 08, 2025This paper presents the modeling, design, and experimental validation of an Ellipse-based Segmented Varying Curvature (ESVC) foot for bipedal robots. Inspired by the segmented curvature rollover shape of human feet, the ESVC foot aims to enhance gait energy efficiency while maintaining analytical tractability for foot location based controller. First, we derive a complete analytical contact model for the ESVC foot by formulating spatial transformations of elliptical segments only using elementary functions. Then a nonlinear programming approach is engaged to determine optimal elliptical parameters of hind foot and fore foot based on a known mid-foot. An error compensation method is introduced to address approximation inaccuracies in rollover length calculation. The proposed ESVC foot is then integrated with a Hybrid Linear Inverted Pendulum model-based walking controller and validated through both simulation and physical experiments on the TT II biped robot. Experimental results across marking time, sagittal, and lateral walking tasks show that the ESVC foot consistently reduces energy consumption compared to line, and flat feet, with up to 18.52\% improvement in lateral walking. These findings demonstrate that the ESVC foot provides a practical and energy-efficient alternative for real-world bipedal locomotion. The proposed design methodology also lays a foundation for data-driven foot shape optimization in future research.
Speech Recognition on TV Series with Video-guided Post-Correction
Jun 08, 2025
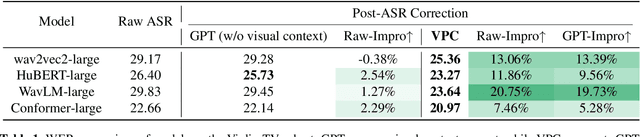

Automatic Speech Recognition (ASR) has achieved remarkable success with deep learning, driving advancements in conversational artificial intelligence, media transcription, and assistive technologies. However, ASR systems still struggle in complex environments such as TV series, where overlapping speech, domain-specific terminology, and long-range contextual dependencies pose significant challenges to transcription accuracy. Existing multimodal approaches fail to correct ASR outputs with the rich temporal and contextual information available in video. To address this limitation, we propose a novel multimodal post-correction framework that refines ASR transcriptions by leveraging contextual cues extracted from video. Our framework consists of two stages: ASR Generation and Video-based Post-Correction, where the first stage produces the initial transcript and the second stage corrects errors using Video-based Contextual Information Extraction and Context-aware ASR Correction. We employ the Video-Large Multimodal Model (VLMM) to extract key contextual information using tailored prompts, which is then integrated with a Large Language Model (LLM) to refine the ASR output. We evaluate our method on a multimodal benchmark for TV series ASR and demonstrate its effectiveness in improving ASR performance by leveraging video-based context to enhance transcription accuracy in complex multimedia environments.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025



Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.