 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit Recommender System in the Permutation Prospective
Feb 24, 2021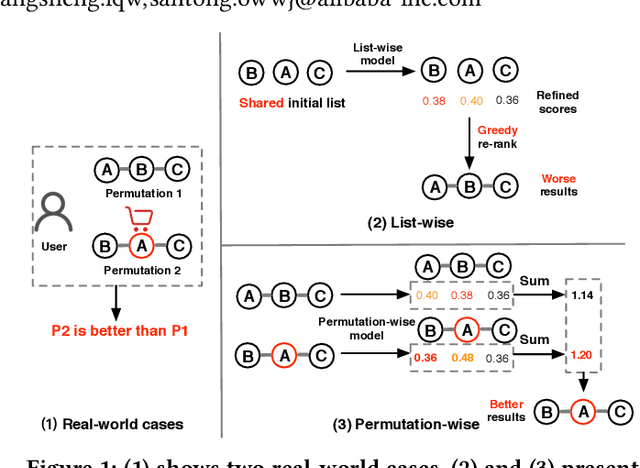
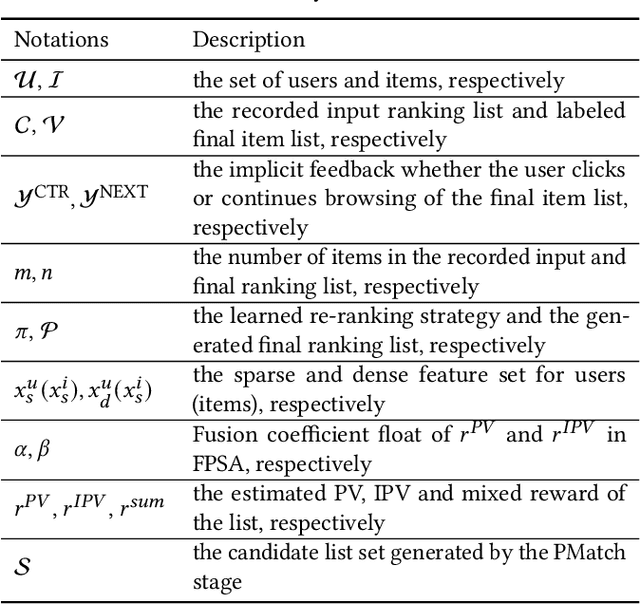
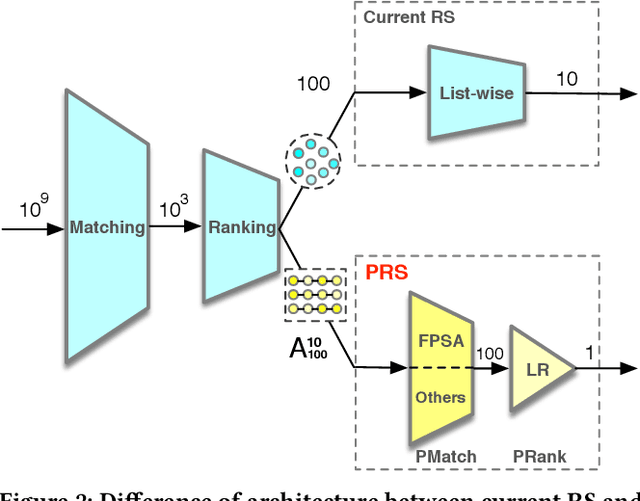
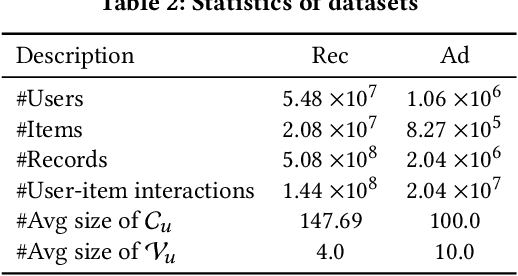
Recommender systems (RS) work effective at alleviating information overload and matching user interests in various web-scale applications. Most RS retrieve the user's favorite candidates and then rank them by the rating scores in the greedy manner. In the permutation prospective, however, current RS come to reveal the following two limitations: 1) They neglect addressing the permutation-variant influence within the recommended results; 2) Permutation consideration extends the latent solution space exponentially, and current RS lack the ability to evaluate the permutations. Both drive RS away from the permutation-optimal recommended results and better user experience. To approximate the permutation-optimal recommended results effectively and efficiently, we propose a novel permutation-wise framework PRS in the re-ranking stage of RS, which consists of Permutation-Matching (PMatch) and Permutation-Ranking (PRank) stages successively. Specifically, the PMatch stage is designed to obtain the candidate list set, where we propose the FPSA algorithm to generate multiple candidate lists via the permutation-wise and goal-oriented beam search algorithm. Afterwards, for the candidate list set, the PRank stage provides a unified permutation-wise ranking criterion named LR metric, which is calculated by the rating scores of elaborately designed permutation-wise model DPWN. Finally, the list with the highest LR score is recommended to the user. Empirical results show that PRS consistently and significantly outperforms state-of-the-art methods. Moreover, PRS has achieved a performance improvement of 11.0% on PV metric and 8.7% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.
Personalized Adaptive Meta Learning for Cold-start User Preference Prediction
Dec 22, 2020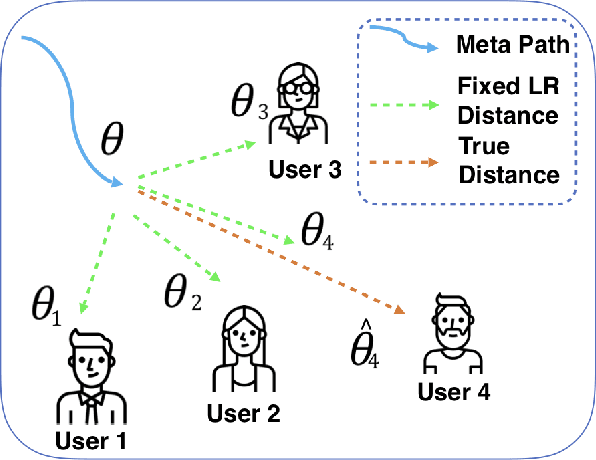
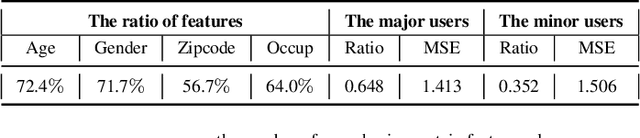
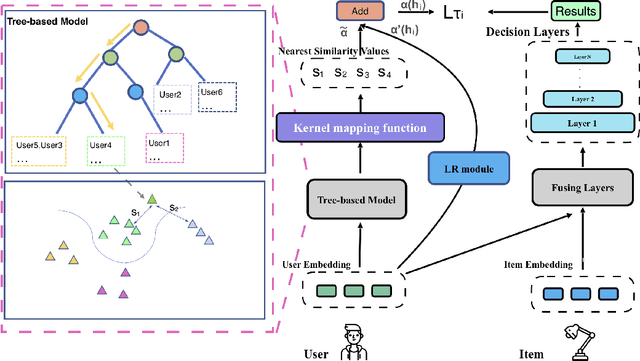

A common challenge in personalized user preference prediction is the cold-start problem. Due to the lack of user-item interactions, directly learning from the new users' log data causes serious over-fitting problem. Recently, many existing studies regard the cold-start personalized preference prediction as a few-shot learning problem, where each user is the task and recommended items are the classes, and the gradient-based meta learning method (MAML) is leveraged to address this challenge. However, in real-world application, the users are not uniformly distributed (i.e., different users may have different browsing history, recommended items, and user profiles. We define the major users as the users in the groups with large numbers of users sharing similar user information, and other users are the minor users), existing MAML approaches tend to fit the major users and ignore the minor users. To address this cold-start task-overfitting problem, we propose a novel personalized adaptive meta learning approach to consider both the major and the minor users with three key contributions: 1) We are the first to present a personalized adaptive learning rate meta-learning approach to improve the performance of MAML by focusing on both the major and minor users. 2) To provide better personalized learning rates for each user, we introduce a similarity-based method to find similar users as a reference and a tree-based method to store users' features for fast search. 3) To reduce the memory usage, we design a memory agnostic regularizer to further reduce the space complexity to constant while maintain the performance. Experiments on MovieLens, BookCrossing, and real-world production datasets reveal that our method outperforms the state-of-the-art methods dramatically for both the minor and major users.
Multi-task MR Imaging with Iterative Teacher Forcing and Re-weighted Deep Learning
Nov 27, 2020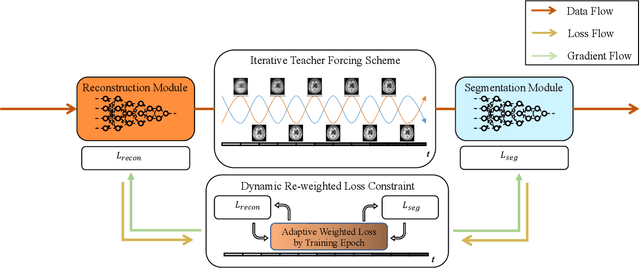

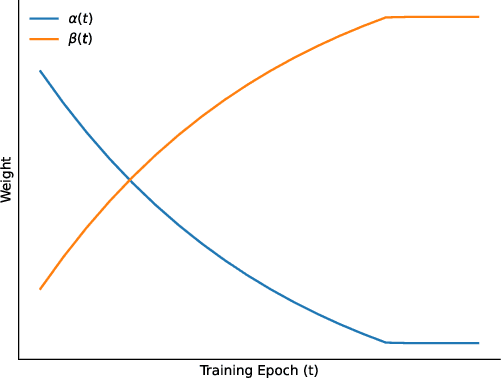
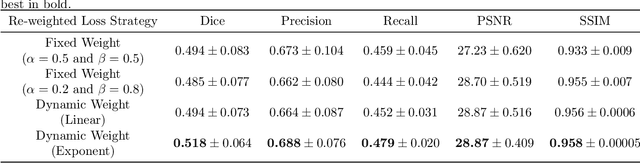
Noises, artifacts, and loss of information caused by the magnetic resonance (MR) reconstruction may compromise the final performance of the downstream applications. In this paper, we develop a re-weighted multi-task deep learning method to learn prior knowledge from the existing big dataset and then utilize them to assist simultaneous MR reconstruction and segmentation from the under-sampled k-space data. The multi-task deep learning framework is equipped with two network sub-modules, which are integrated and trained by our designed iterative teacher forcing scheme (ITFS) under the dynamic re-weighted loss constraint (DRLC). The ITFS is designed to avoid error accumulation by injecting the fully-sampled data into the training process. The DRLC is proposed to dynamically balance the contributions from the reconstruction and segmentation sub-modules so as to co-prompt the multi-task accuracy. The proposed method has been evaluated on two open datasets and one in vivo in-house dataset and compared to six state-of-the-art methods. Results show that the proposed method possesses encouraging capabilities for simultaneous and accurate MR reconstruction and segmentation.
Distant Supervision for E-commerce Query Segmentation via Attention Network
Nov 09, 2020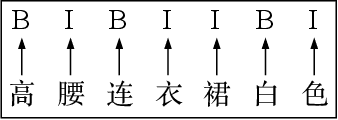
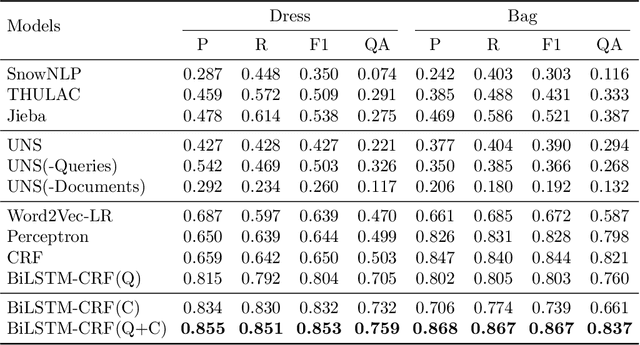
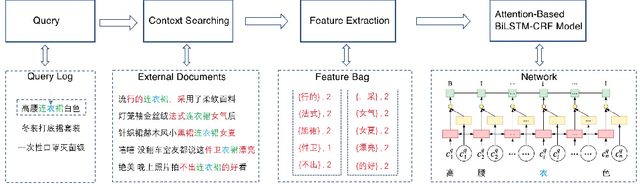
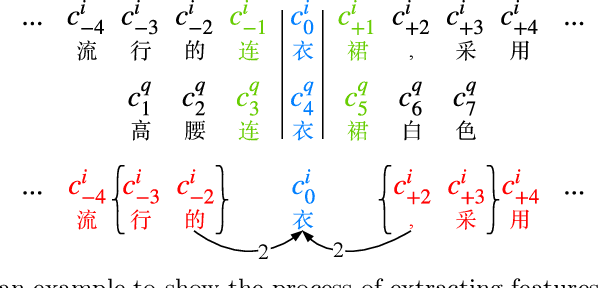
The booming online e-commerce platforms demand highly accurate approaches to segment queries that carry the product requirements of consumers. Recent works have shown that the supervised methods, especially those based on deep learning, are attractive for achieving better performance on the problem of query segmentation. However, the lack of labeled data is still a big challenge for training a deep segmentation network, and the problem of Out-of-Vocabulary (OOV) also adversely impacts the performance of query segmentation. Different from query segmentation task in an open domain, e-commerce scenario can provide external documents that are closely related to these queries. Thus, to deal with the two challenges, we employ the idea of distant supervision and design a novel method to find contexts in external documents and extract features from these contexts. In this work, we propose a BiLSTM-CRF based model with an attention module to encode external features, such that external contexts information, which can be utilized naturally and effectively to help query segmentation. Experiments on two datasets show the effectiveness of our approach compared with several kinds of baselines.
Balanced Order Batching with Task-Oriented Graph Clustering
Aug 19, 2020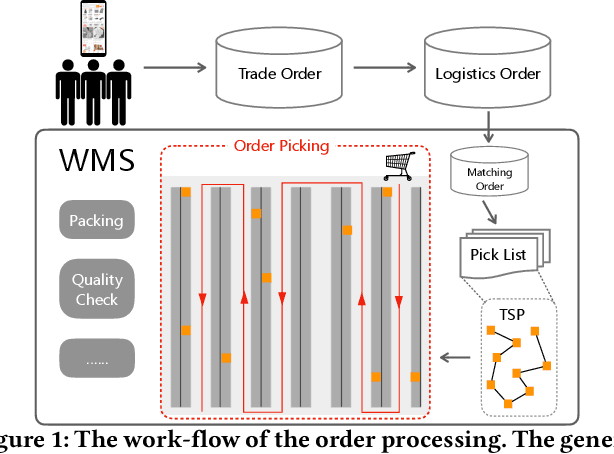
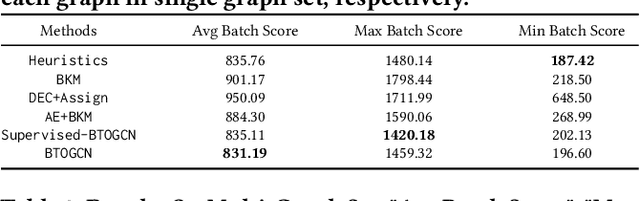
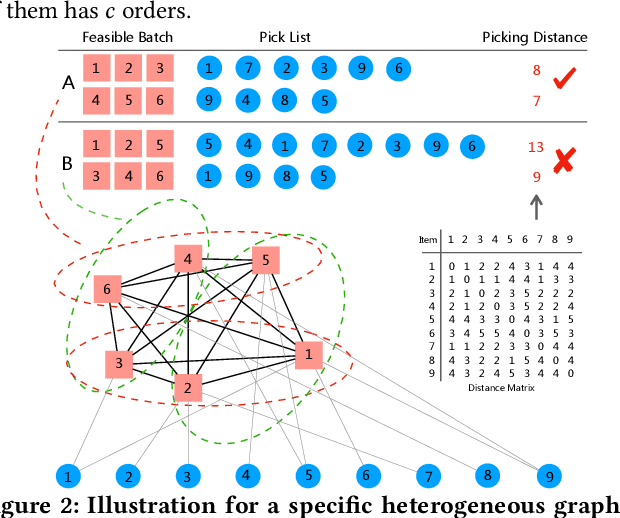
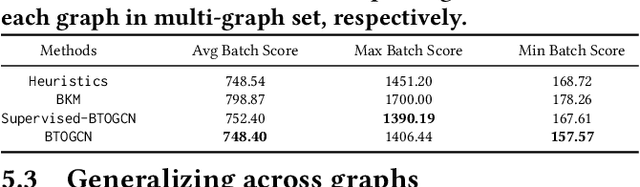
Balanced order batching problem (BOBP) arises from the process of warehouse picking in Cainiao, the largest logistics platform in China. Batching orders together in the picking process to form a single picking route, reduces travel distance. The reason for its importance is that order picking is a labor intensive process and, by using good batching methods, substantial savings can be obtained. The BOBP is a NP-hard combinational optimization problem and designing a good problem-specific heuristic under the quasi-real-time system response requirement is non-trivial. In this paper, rather than designing heuristics, we propose an end-to-end learning and optimization framework named Balanced Task-orientated Graph Clustering Network (BTOGCN) to solve the BOBP by reducing it to balanced graph clustering optimization problem. In BTOGCN, a task-oriented estimator network is introduced to guide the type-aware heterogeneous graph clustering networks to find a better clustering result related to the BOBP objective. Through comprehensive experiments on single-graph and multi-graphs, we show: 1) our balanced task-oriented graph clustering network can directly utilize the guidance of target signal and outperforms the two-stage deep embedding and deep clustering method; 2) our method obtains an average 4.57m and 0.13m picking distance ("m" is the abbreviation of the meter (the SI base unit of length)) reduction than the expert-designed algorithm on single and multi-graph set and has a good generalization ability to apply in practical scenario.
Parameter Constrained Transfer Learning for Low Dose PET Image Denoising
Oct 13, 2019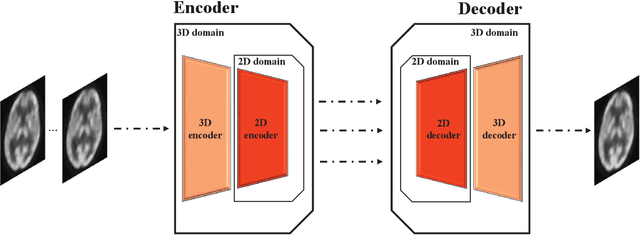



Positron emission tomography (PET) is widely used in clinical practice. However, the potential risk of PET-associated radiation dose to patients needs to be minimized. With reduction of the radiation dose, the resultant images may suffer from noise and artifacts which compromises the diagnostic performance. In this paper, we propose a parameter-constrained generative adversarial network with Wasserstein distance and perceptual loss (PC-WGAN) for low-dose PET image denoising. This method makes two main contributions: 1) a PC-WGAN framework is designed to denoise low-dose PET images without compromising structural details; and 2) a transfer learning strategy is developed to train PC-WGAN with parameters being constrained, which has major merits; namely, making the training process of PC-WGAN efficient and improving the quality of denoised images. The experimental results on clinical data show that the proposed network can suppress image noise more effectively while preserving better image fidelity than three selected state-of-the-art methods.
Conceptualize and Infer User Needs in E-commerce
Oct 08, 2019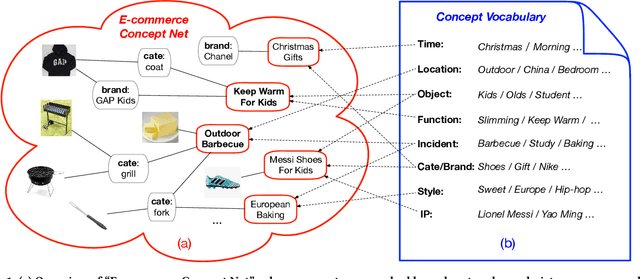


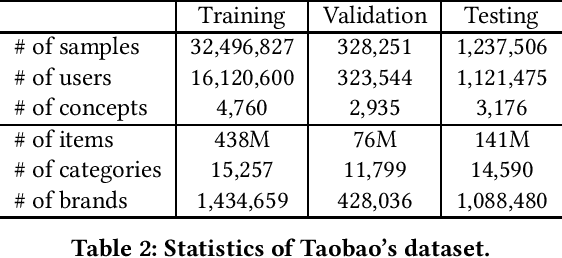
Understanding latent user needs beneath shopping behaviors is critical to e-commercial applications. Without a proper definition of user needs in e-commerce, most industry solutions are not driven directly by user needs at current stage, which prevents them from further improving user satisfaction. Representing implicit user needs explicitly as nodes like "outdoor barbecue" or "keep warm for kids" in a knowledge graph, provides new imagination for various e- commerce applications. Backed by such an e-commerce knowledge graph, we propose a supervised learning algorithm to conceptualize user needs from their transaction history as "concept" nodes in the graph and infer those concepts for each user through a deep attentive model. Offline experiments demonstrate the effectiveness and stability of our model, and online industry strength tests show substantial advantages of such user needs understanding.
Query-based Interactive Recommendation by Meta-Path and Adapted Attention-GRU
Jun 24, 2019
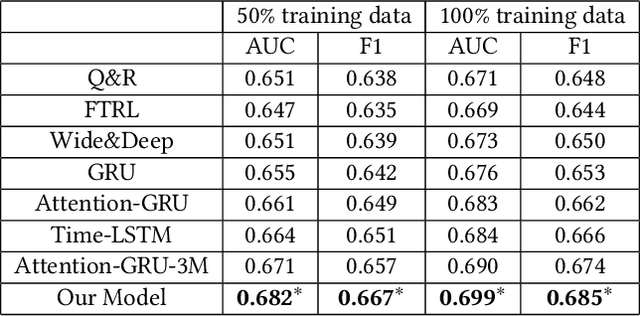

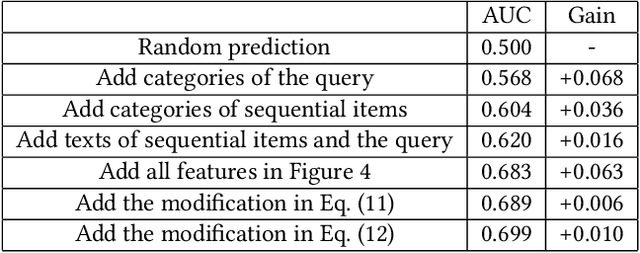
Recently, interactive recommender systems are becoming increasingly popular. The insight is that, with the interaction between users and the system, (1) users can actively intervene the recommendation results rather than passively receive them, and (2) the system learns more about users so as to provide better recommendation. We focus on the single-round interaction, i.e. the system asks the user a question (Step 1), and exploits his feedback to generate better recommendation (Step 2). A novel query-based interactive recommender system is proposed in this paper, where \textbf{personalized questions are accurately generated from millions of automatically constructed questions} in Step 1, and \textbf{the recommendation is ensured to be closely-related to users' feedback} in Step 2. We achieve this by transforming Step 1 into a query recommendation task and Step 2 into a retrieval task. The former task is our key challenge. We firstly propose a model based on Meta-Path to efficiently retrieve hundreds of query candidates from the large query pool. Then an adapted Attention-GRU model is developed to effectively rank these candidates for recommendation. Offline and online experiments on Taobao, a large-scale e-commerce platform in China, verify the effectiveness of our interactive system. The system has already gone into production in the homepage of Taobao App since Nov. 11, 2018 (see https://v.qq.com/x/page/s0833tkp1uo.html on how it works online). Our code and dataset are public in https://github.com/zyody/QueryQR.
Exact-K Recommendation via Maximal Clique Optimization
May 17, 2019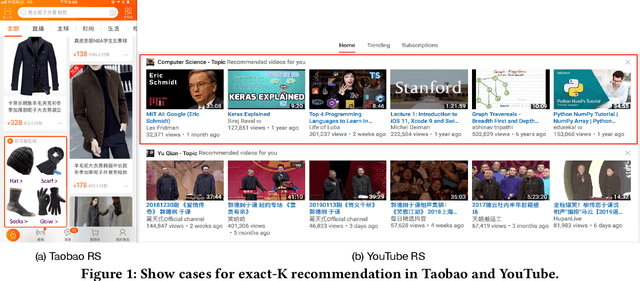
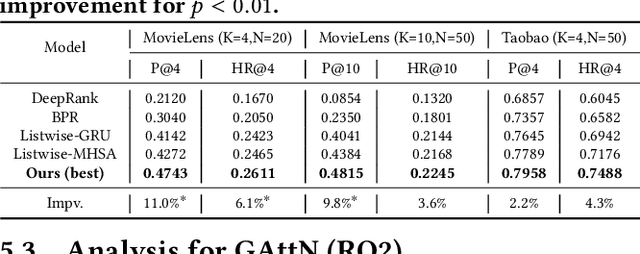
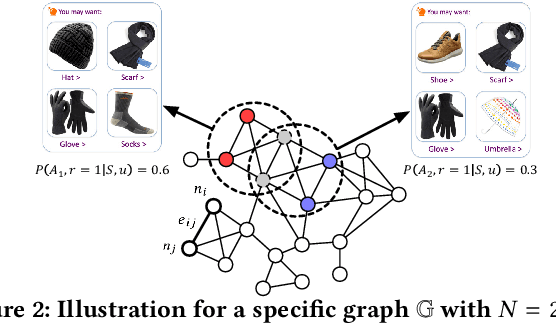
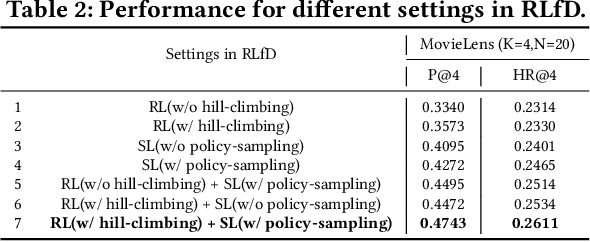
This paper targets to a novel but practical recommendation problem named exact-K recommendation. It is different from traditional top-K recommendation, as it focuses more on (constrained) combinatorial optimization which will optimize to recommend a whole set of K items called card, rather than ranking optimization which assumes that "better" items should be put into top positions. Thus we take the first step to give a formal problem definition, and innovatively reduce it to Maximum Clique Optimization based on graph. To tackle this specific combinatorial optimization problem which is NP-hard, we propose Graph Attention Networks (GAttN) with a Multi-head Self-attention encoder and a decoder with attention mechanism. It can end-to-end learn the joint distribution of the K items and generate an optimal card rather than rank individual items by prediction scores. Then we propose Reinforcement Learning from Demonstrations (RLfD) which combines the advantages in behavior cloning and reinforcement learning, making it sufficient- and-efficient to train the model. Extensive experiments on three datasets demonstrate the effectiveness of our proposed GAttN with RLfD method, it outperforms several strong baselines with a relative improvement of 7.7% and 4.7% on average in Precision and Hit Ratio respectively, and achieves state-of-the-art (SOTA) performance for the exact-K recommendation problem.
Multi-Modal Generative Adversarial Network for Short Product Title Generation in Mobile E-Commerce
Apr 03, 2019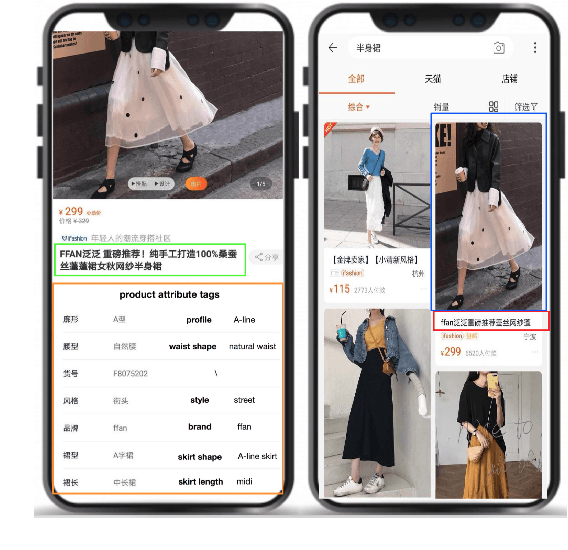
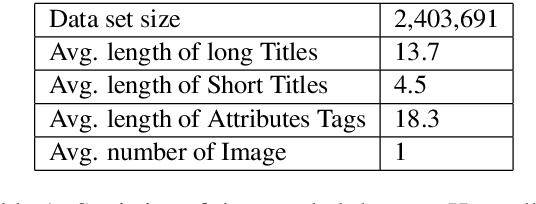
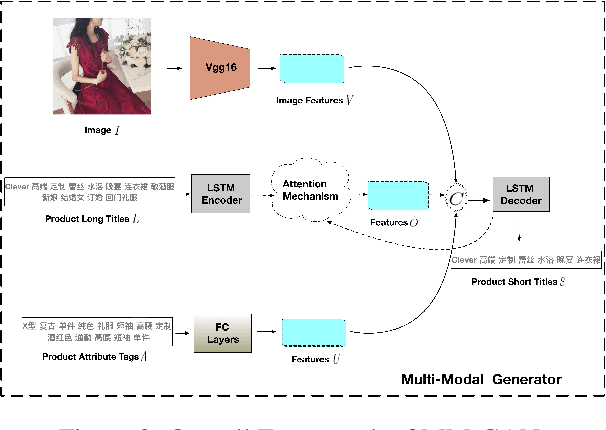

Nowadays, more and more customers browse and purchase products in favor of using mobile E-Commerce Apps such as Taobao and Amazon. Since merchants are usually inclined to describe redundant and over-informative product titles to attract attentions from customers, it is important to concisely display short product titles on limited screen of mobile phones. To address this discrepancy, previous studies mainly consider textual information of long product titles and lacks of human-like view during training and evaluation process. In this paper, we propose a Multi-Modal Generative Adversarial Network (MM-GAN) for short product title generation in E-Commerce, which innovatively incorporates image information and attribute tags from product, as well as textual information from original long titles. MM-GAN poses short title generation as a reinforcement learning process, where the generated titles are evaluated by the discriminator in a human-like view. Extensive experiments on a large-scale E-Commerce dataset demonstrate that our algorithm outperforms other state-of-the-art methods. Moreover, we deploy our model into a real-world online E-Commerce environment and effectively boost the performance of click through rate and click conversion rate by 1.66% and 1.87%, respectively.