 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When and What to Ask: a Hierarchical Reinforcement Learning Framework
Oct 14, 2021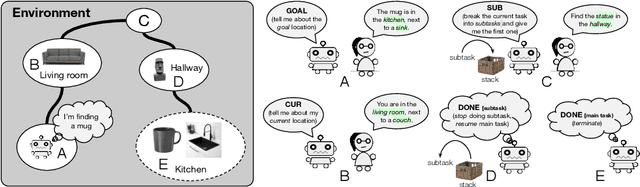
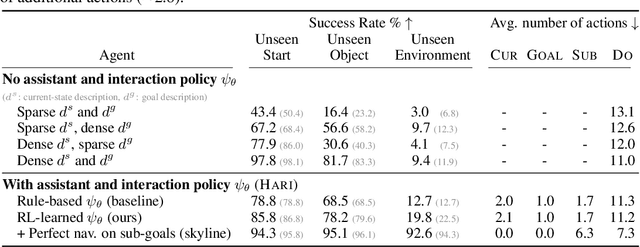
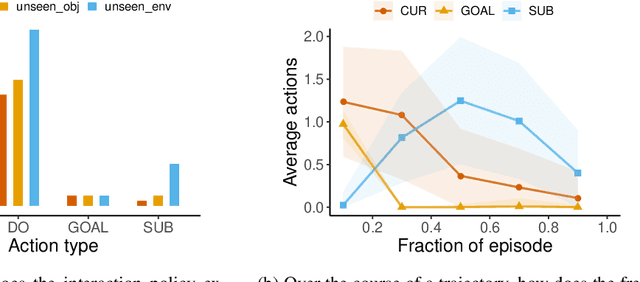

Reliable AI agents should be mindful of the limits of their knowledge and consult humans when sensing that they do not have sufficient knowledge to make sound decisions. We formulate a hierarchical reinforcement learning framework for learning to decide when to request additional information from humans and what type of information would be helpful to request. Our framework extends partially-observed Markov decision processes (POMDPs) by allowing an agent to interact with an assistant to leverage their knowledge in accomplishing tasks. Results on a simulated human-assisted navigation problem demonstrate the effectiveness of our framework: aided with an interaction policy learned by our method, a navigation policy achieves up to a 7x improvement in task success rate compared to performing tasks only by itself. The interaction policy is also efficient: on average, only a quarter of all actions taken during a task execution are requests for information. We analyze benefits and challenges of learning with a hierarchical policy structure and suggest directions for future work.
WebQA: Multihop and Multimodal QA
Sep 21, 2021
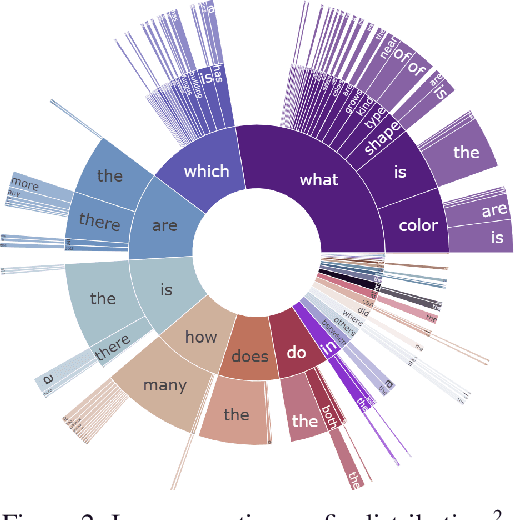


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.
Dependency Induction Through the Lens of Visual Perception
Sep 20, 2021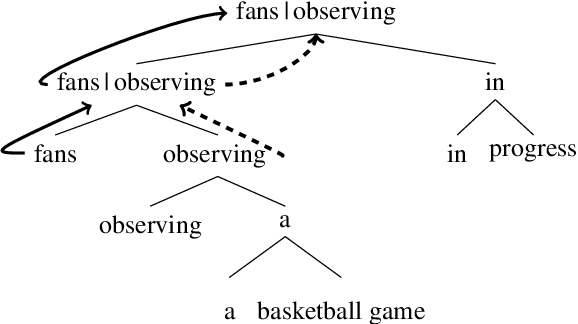
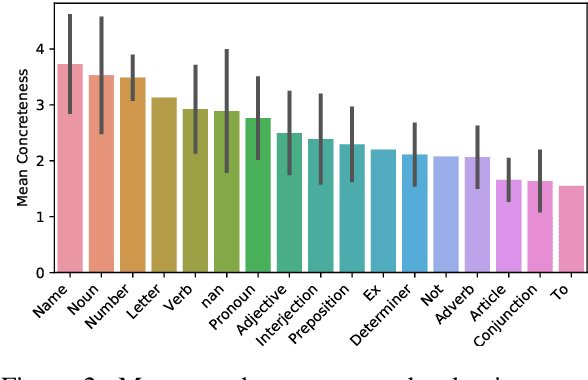
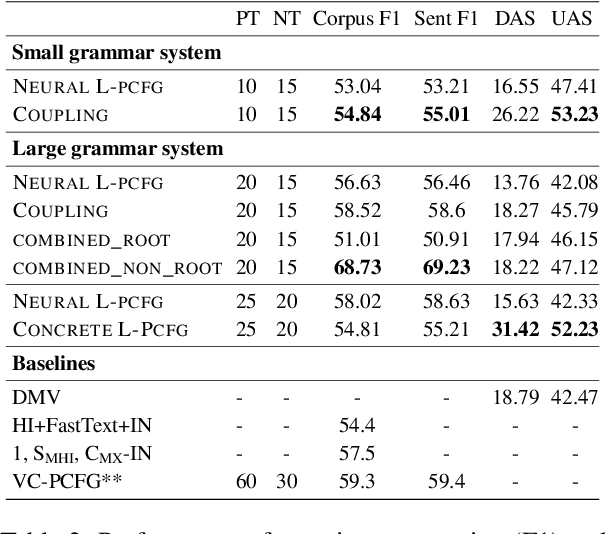
Most previous work on grammar induction focuses on learning phrasal or dependency structure purely from text. However, because the signal provided by text alone is limited, recently introduced visually grounded syntax models make use of multimodal information leading to improved performance in constituency grammar induction. However, as compared to dependency grammars, constituency grammars do not provide a straightforward way to incorporate visual information without enforcing language-specific heuristics. In this paper, we propose an unsupervised grammar induction model that leverages word concreteness and a structural vision-based heuristic to jointly learn constituency-structure and dependency-structure grammars. Our experiments find that concreteness is a strong indicator for learning dependency grammars, improving the direct attachment score (DAS) by over 50\% as compared to state-of-the-art models trained on pure text. Next, we propose an extension of our model that leverages both word concreteness and visual semantic role labels in constituency and dependency parsing. Our experiments show that the proposed extension outperforms the current state-of-the-art visually grounded models in constituency parsing even with a smaller grammar size.
TACo: Token-aware Cascade Contrastive Learning for Video-Text Alignment
Aug 23, 2021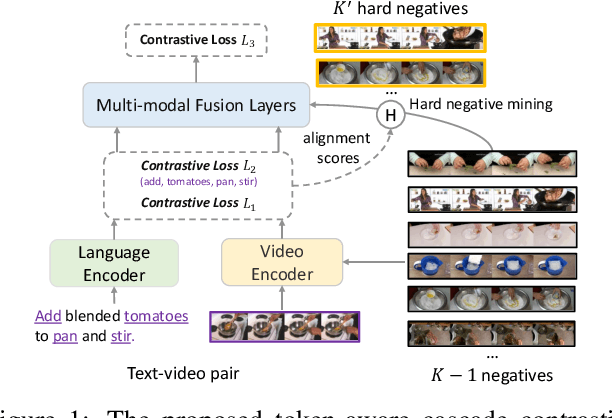
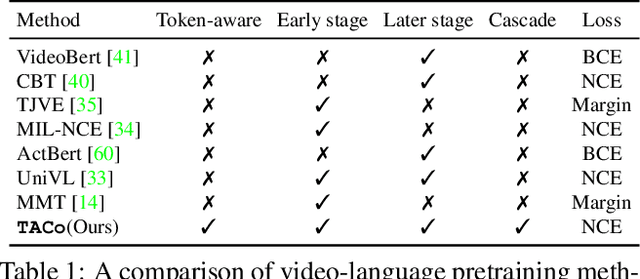
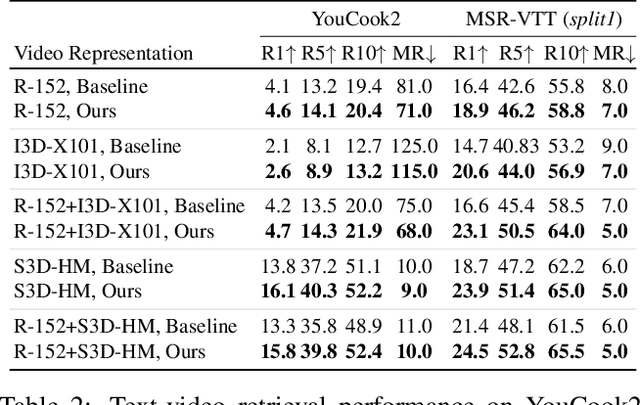
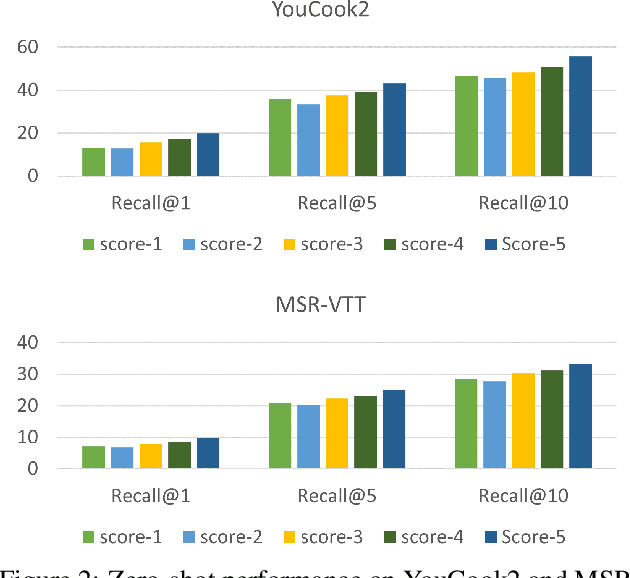
Contrastive learning has been widely used to train transformer-based vision-language models for video-text alignment and multi-modal representation learning. This paper presents a new algorithm called Token-Aware Cascade contrastive learning (TACo) that improves contrastive learning using two novel techniques. The first is the token-aware contrastive loss which is computed by taking into account the syntactic classes of words. This is motivated by the observation that for a video-text pair, the content words in the text, such as nouns and verbs, are more likely to be aligned with the visual contents in the video than the function words. Second, a cascade sampling method is applied to generate a small set of hard negative examples for efficient loss estimation for multi-modal fusion layers. To validate the effectiveness of TACo, in our experiments we finetune pretrained models for a set of downstream tasks including text-video retrieval (YouCook2, MSR-VTT and ActivityNet), video action step localization (CrossTask), video action segmentation (COIN). The results show that our models attain consistent improvements across different experimental settings over previous methods, setting new state-of-the-art on three public text-video retrieval benchmarks of YouCook2, MSR-VTT and ActivityNet.
Language Grounding with 3D Objects
Jul 26, 2021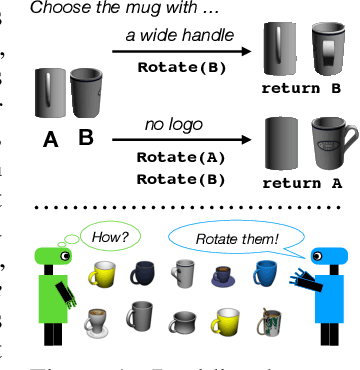
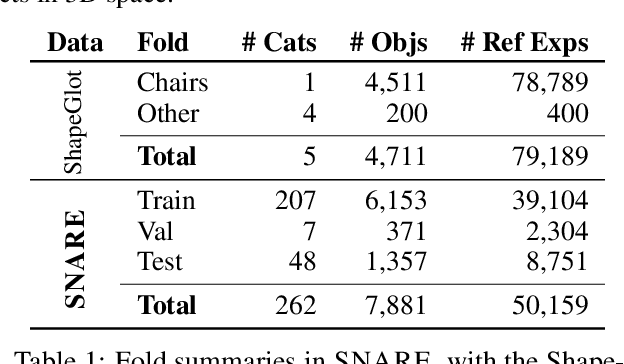
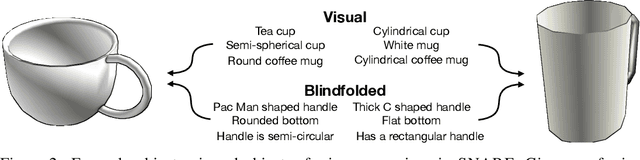
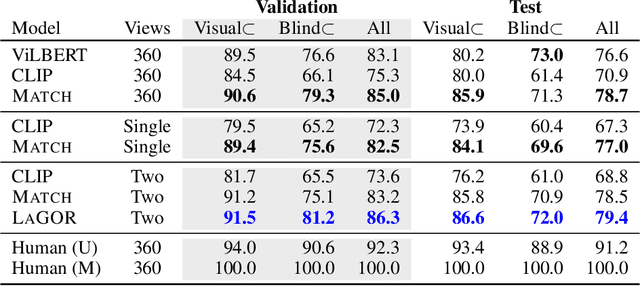
Seemingly simple natural language requests to a robot are generally underspecified, for example "Can you bring me the wireless mouse?" When viewing mice on the shelf, the number of buttons or presence of a wire may not be visible from certain angles or positions. Flat images of candidate mice may not provide the discriminative information needed for "wireless". The world, and objects in it, are not flat images but complex 3D shapes. If a human requests an object based on any of its basic properties, such as color, shape, or texture, robots should perform the necessary exploration to accomplish the task. In particular, while substantial effort and progress has been made on understanding explicitly visual attributes like color and category, comparatively little progress has been made on understanding language about shapes and contours. In this work, we introduce a novel reasoning task that targets both visual and non-visual language about 3D objects. Our new benchmark, ShapeNet Annotated with Referring Expressions (SNARE), requires a model to choose which of two objects is being referenced by a natural language description. We introduce several CLIP-based models for distinguishing objects and demonstrate that while recent advances in jointly modeling vision and language are useful for robotic language understanding, it is still the case that these models are weaker at understanding the 3D nature of objects -- properties which play a key role in manipulation. In particular, we find that adding view estimation to language grounding models improves accuracy on both SNARE and when identifying objects referred to in language on a robot platform.
Few-shot Language Coordination by Modeling Theory of Mind
Jul 12, 2021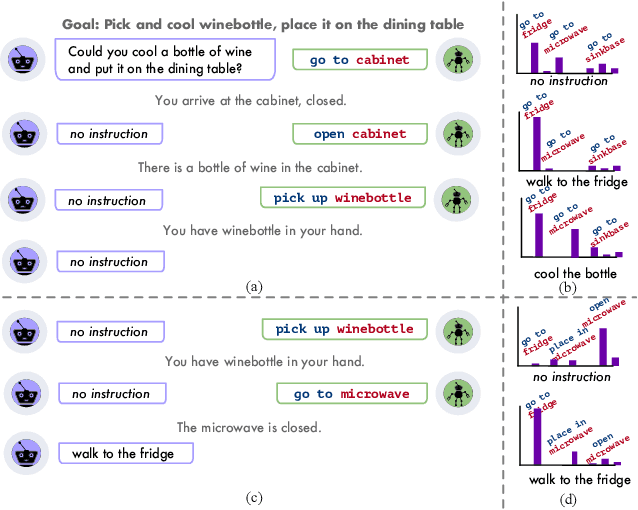
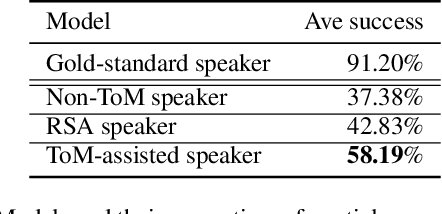
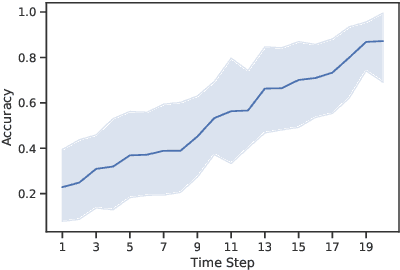
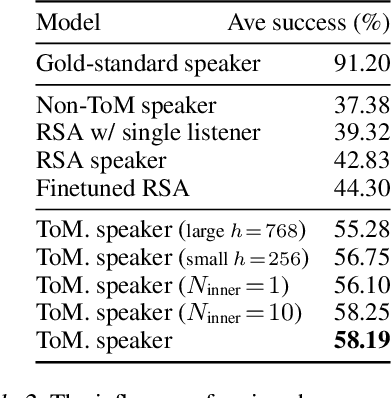
$\textit{No man is an island.}$ Humans communicate with a large community by coordinating with different interlocutors within short conversations. This ability has been understudied by the research on building neural communicative agents. We study the task of few-shot $\textit{language coordination}$: agents quickly adapting to their conversational partners' language abilities. Different from current communicative agents trained with self-play, we require the lead agent to coordinate with a $\textit{population}$ of agents with different linguistic abilities, quickly adapting to communicate with unseen agents in the population. This requires the ability to model the partner's beliefs, a vital component of human communication. Drawing inspiration from theory-of-mind (ToM; Premack& Woodruff (1978)), we study the effect of the speaker explicitly modeling the listeners' mental states. The speakers, as shown in our experiments, acquire the ability to predict the reactions of their partner, which helps it generate instructions that concisely express its communicative goal. We examine our hypothesis that the instructions generated with ToM modeling yield better communication performance in both a referential game and a language navigation task. Positive results from our experiments hint at the importance of explicitly modeling communication as a socio-pragmatic progress.
Grounding 'Grounding' in NLP
Jun 04, 2021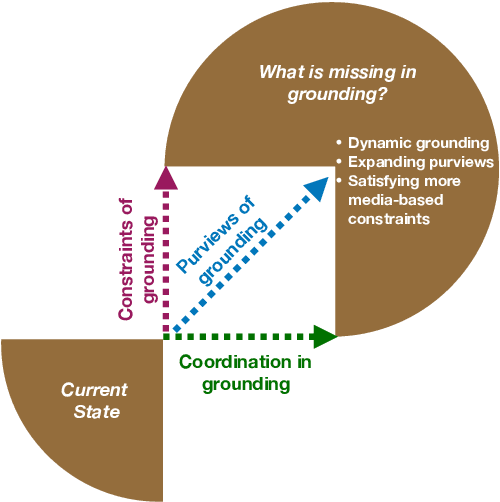
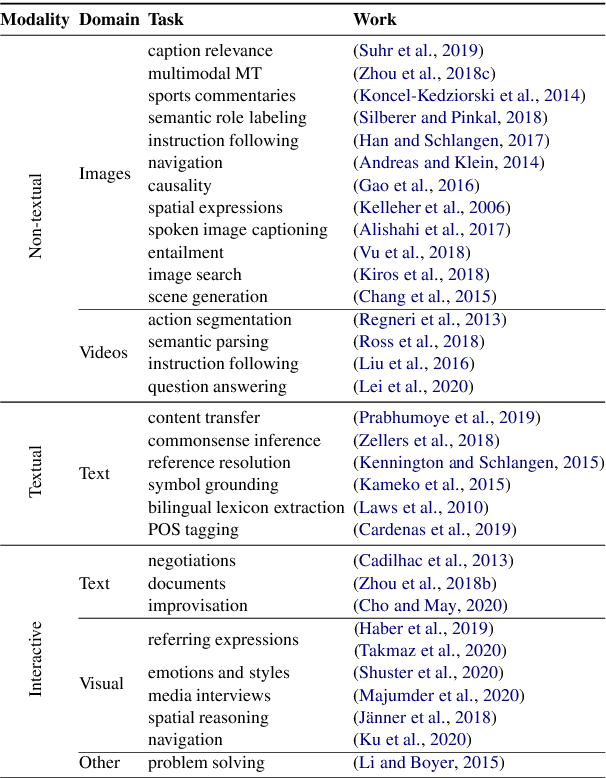
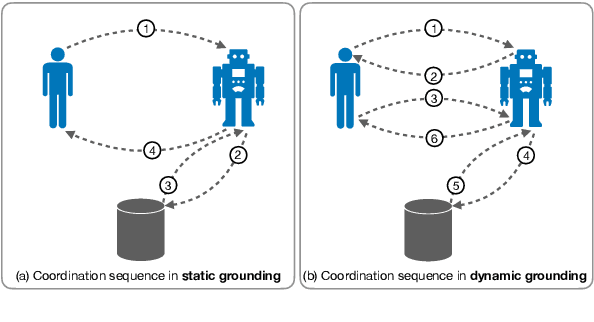

The NLP community has seen substantial recent interest in grounding to facilitate interaction between language technologies and the world. However, as a community, we use the term broadly to reference any linking of text to data or non-textual modality. In contrast, Cognitive Science more formally defines "grounding" as the process of establishing what mutual information is required for successful communication between two interlocutors -- a definition which might implicitly capture the NLP usage but differs in intent and scope. We investigate the gap between these definitions and seek answers to the following questions: (1) What aspects of grounding are missing from NLP tasks? Here we present the dimensions of coordination, purviews and constraints. (2) How is the term "grounding" used in the current research? We study the trends in datasets, domains, and tasks introduced in recent NLP conferences. And finally, (3) How to advance our current definition to bridge the gap with Cognitive Science? We present ways to both create new tasks or repurpose existing ones to make advancements towards achieving a more complete sense of grounding.
Worst of Both Worlds: Biases Compound in Pre-trained Vision-and-Language Models
Apr 18, 2021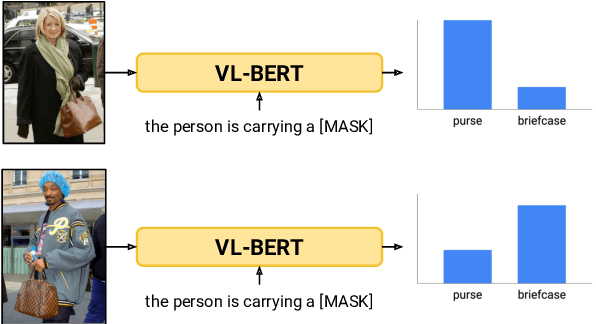


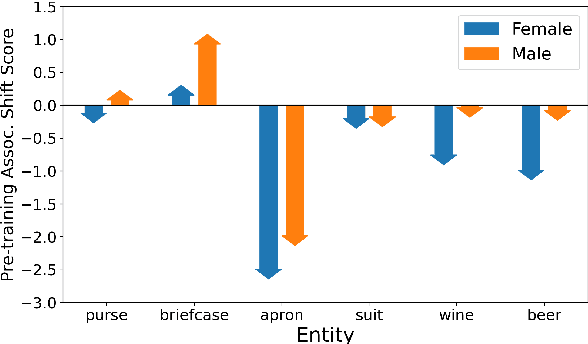
Numerous works have analyzed biases in vision and pre-trained language models individually - however, less attention has been paid to how these biases interact in multimodal settings. This work extends text-based bias analysis methods to investigate multimodal language models, and analyzes intra- and inter-modality associations and biases learned by these models. Specifically, we demonstrate that VL-BERT (Su et al., 2020) exhibits gender biases, often preferring to reinforce a stereotype over faithfully describing the visual scene. We demonstrate these findings on a controlled case-study and extend them for a larger set of stereotypically gendered entities.
An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing Games
Jan 31, 2021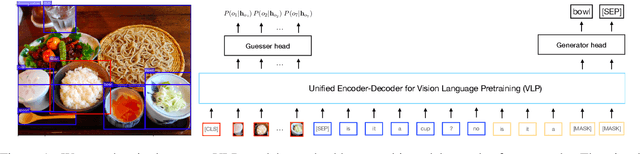
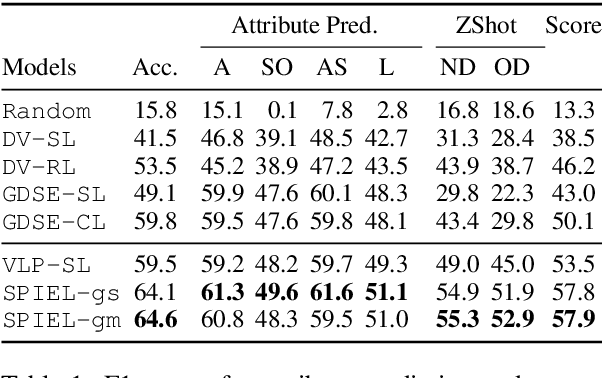


Guessing games are a prototypical instance of the "learning by interacting" paradigm. This work investigates how well an artificial agent can benefit from playing guessing games when later asked to perform on novel NLP downstream tasks such as Visual Question Answering (VQA). We propose two ways to exploit playing guessing games: 1) a supervised learning scenario in which the agent learns to mimic successful guessing games and 2) a novel way for an agent to play by itself, called Self-play via Iterated Experience Learning (SPIEL). We evaluate the ability of both procedures to generalize: an in-domain evaluation shows an increased accuracy (+7.79) compared with competitors on the evaluation suite CompGuessWhat?!; a transfer evaluation shows improved performance for VQA on the TDIUC dataset in terms of harmonic average accuracy (+5.31) thanks to more fine-grained object representations learned via SPIEL.
Knowledge-driven Self-supervision for Zero-shot Commonsense Question Answering
Nov 07, 2020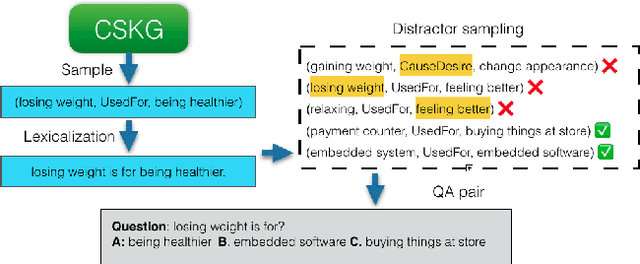

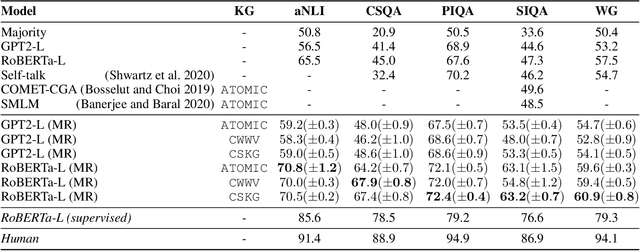
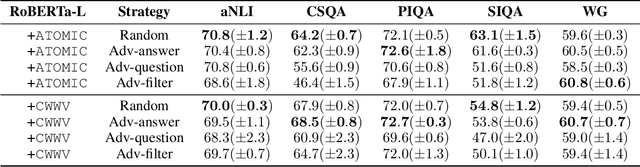
Recent developments in pre-trained neural language modeling have led to leaps in accuracy on commonsense question-answering benchmarks. However, there is increasing concern that models overfit to specific tasks, without learning to utilize external knowledge or perform general semantic reasoning. In contrast, zero-shot evaluations have shown promise as a more robust measure of a model's general reasoning abilities. In this paper, we propose a novel neuro-symbolic framework for zero-shot question answering across commonsense tasks. Guided by a set of hypotheses, the framework studies how to transform various pre-existing knowledge resources into a form that is most effective for pre-training models. We vary the set of language models, training regimes, knowledge sources, and data generation strategies, and measure their impact across tasks. Extending on prior work, we devise and compare four constrained distractor-sampling strategies. We provide empirical results across five commonsense question-answering tasks with data generated from five external knowledge resources. We show that, while an individual knowledge graph is better suited for specific tasks, a global knowledge graph brings consistent gains across different tasks. In addition, both preserving the structure of the task as well as generating fair and informative questions help language models learn more effectively.